在Hadoop1.x版本中,MapReduce采用master/salve架构,TaskTracker就是这个架构中的slave部分。TaskTracker以服务组件的形式存在,负责任务的执行和任务状态的汇报。TaskTracker是hadoop集群中运行在各个节点上的服务。扮演着“通信交通”的角色,是JobTracker和Task之间的“沟通桥梁”,一方面,TaskTracker发送心跳信息到JobTracker,并接收和执行返回的各种任务命令,比如运行任务(launchTaskAction),提交任务(SubmitTaskAction),杀死任务(KillTaskAction),杀死job(KillJobAction),重新初始化(TaskTrackerReinitAction)。另一方面,接收Task的汇报信息并发送需要执行的任务命令。简单来说,就是两个功能:汇报心跳和执行命令。
一、TaskTracker启动过程分析
TaskTracker服务由类org.apache.hadoop.mapred.TaskTracker来实现。该类实现四个接口,分别是MRContents(常量接口),TaskUmbilicalProtocol(和Task通信协议接口),Runnable(线程接口,目的是以线程的方式启动TaskTracker),TaskTrackerMXBean(JMX MXBean,为了其他第三方监控软件监控)。
/** * TaskTracker是一个独立的服务,所以有一个main方法。 */ public static void main(String argv[]) throws Exception { ...... 打印信息,以及检查argv参数 try { JobConf conf=new JobConf(); ...... JMX信息设置 TaskTracker tt = new TaskTracker(conf); // 创建TaskTracker对象 MBeans.register("TaskTracker", "TaskTrackerInfo", tt); // 注册MXBean tt.run(); // 执行 } catch (Throwable e) { ..... 异常处理 } }
TaskTracker在构造函数中初始化一些重要的对象和线程,在run方法中维护一个和JobTracker通信的RPC连接。接下来分别分析构造函数和run方法。
1、重要变量和对象
TaskTracker中的成员变量主要作用是用于管理节点和监控节点上的任务。这里简单介绍一些比较有用的变量以及它们的默认值和意义。
| 变量名 | 变量修饰符 | 默认值 | 意义解释 |
| running | volatile boolean | true | TaskTracker是否处于运行状态,true表示处于运行状态 |
| lastCheckDirsTime | private long | 0 | 最近检查时间 |
| lastNumFailures | private int | 0 | 最近检查失败个数 |
| jobTrackAddr | InetSocketAddress | JobTracker的网络地址 | |
| taskReportAddress | InetSocketAddress | TaskTracker和Task通信的网络地址 | |
| taskReportServer | Server | RPC server,用于TaskTracker和Task间通信 | |
| jobClient | InterTrackerProtocol | RPC client,用于和JobTracker通信 | |
| heartbeatResponseId | short | -1 | 心跳响应id |
| status | TaskTrackerStatus | null | TaskTrackerStatus状态 |
| server | HttpServer | 将TaskTracker信息显示到web界面 | |
| shuttingDown | volatile boolean | false | 关闭 |
| tasks | Map<TaskAttemptID,TaskInProgress> | hashmap | 该节点上TID和TIP的映射关系 |
| runningTasks | Map<TaskAttemptID,TaskInProgress> | null | 该节点上正在运行的TID和TIP的映射关系 |
| runningJobs | Map<JobID,RunningJob> | treemap | 该节点上正在运行的作用列表,如果某个作业中的任务在该节点上运行,那么将该任务添加进入 |
| acceptNewTasks | boolean | true | 是否接受新任务,每次给JobTracker汇报心跳的时候带上该值。 |
| maxMapSlots | private int | 0 | 该节点上配置的Map slot数目 |
| maxReduceSlots | private int | 0 | 该节点上配置的Reduce slot数目 |
| failures | private int | 0 | 该节点上失败的job次数 |
| heartbeatInterval | private volatile int | 3000(ms) | 心跳间隔时间,默认3s |
| aclsManager | ACLsManager | 作业访问权限控制对象 | |
| taskController | TaskController | 用于控制任务的初始化,终结和清洗工作 | |
| userLogManager | UserLogManager | 用户日志管理 | |
| jvmManager | JvmManager | JVM管理 | |
| distributedCacheManager | TrackerDistributedCacheManager | 分布式缓存管理 | |
| mapEventsFetcher | MapEventsFetcherThread | 获取以及完成的MapTask列表,为Reduce Task远程copy提供前期准备 | |
| taskMemoryManager | TaskMemoryManagerThread | 任务内存监控 | |
| taskLauncher | TaskLauncher | 启动任务 | |
| localizer | Localizer | 任务本地化 | |
| healthChecker | NodeHealthCheckerService | 节点健康状况检查 | |
| jettyBugMonitor | JettyBugMonitor | 应对jetty中的bug启动的一个线程 |
这些变量和对象的初始化工作基本上均放在构造函数中完成,现在看看构造函数:
........ FILE_CACHE_SIZE = conf.getInt("mapred.tasktracker.file.cache.size", 2000); // 获取文件cache大小,默认2000 maxMapSlots = conf.getInt("mapred.tasktracker.map.tasks.maximum", 2); // 获取配置的map slot大小,默认2 maxReduceSlots = conf.getInt("mapred.tasktracker.reduce.tasks.maximum", 2); // 获取配置的reduce slot个数,默认为2 diskHealthCheckInterval = conf.getLong(DISK_HEALTH_CHECK_INTERVAL_PROPERTY, DEFAULT_DISK_HEALTH_CHECK_INTERVAL); // 获取节点健康检查间隔时间,默认为60s .......... taskController = (TaskController) ReflectionUtils.newInstance(taskControllerClass, fConf); // 创建控制器对象 .......... initialize(); // 初始化 ......... server.start(); // 启动httpserver this.httpPort = server.getPort(); checkJettyPort(httpPort); // 检查jetty服务器,由于当端口号为小于0的情况下,jetty有bug,所以在这种情况下,设置shuttingDown为true。
在构造函数中,除了获取一些基本的设置参数外,只初始化了taskController,server等。其他的初始化工作是调用方法initialize完成的。
// RPC initialization int max = maxMapSlots > maxReduceSlots ? maxMapSlots : maxReduceSlots; // RPC初始值,采用最大的slot值。 //set the num handlers to max*2 since canCommit may wait for the duration of a heartbeat RPC // 创建和Task通信的Server端对象,线程大小为2倍的slot大小。 this.taskReportServer = RPC.getServer(this, bindAddress, tmpPort, 2 * max, false, this.fConf, this.jobTokenSecretManager); this.taskReportServer.start(); // 启动 ........ // Initialize DistributedCache this.distributedCacheManager = new TrackerDistributedCacheManager(this.fConf, taskController); // 初始化分布式缓存系统 this.distributedCacheManager.startCleanupThread(); // 启动 this.jobClient = (InterTrackerProtocol)UserGroupInformation.getLoginUser().doAs( new PrivilegedExceptionAction<Object>() { public Object run() throws IOException { return RPC.waitForProxy(InterTrackerProtocol.class,InterTrackerProtocol.versionID,jobTrackAddr, fConf); } }); // 创建和JobTracker通信的客户端对象 ...... // 创建获取map的线程 this.mapEventsFetcher = new MapEventsFetcherThread(); mapEventsFetcher.setDaemon(true); mapEventsFetcher.setName("Map-events fetcher for all reduce tasks " + "on " + taskTrackerName); mapEventsFetcher.start(); ............. // 创建map/reduce任务启动线程并run mapLauncher = new TaskLauncher(TaskType.MAP, maxMapSlots); reduceLauncher = new TaskLauncher(TaskType.REDUCE, maxReduceSlots); mapLauncher.start(); reduceLauncher.start();
我们可以看到基本上所有涉及到的变量或者对象都已经完成了初始化并启动,至此TaskTracker的初始化工作基本完成。
二、和JobTracker的交互
1、单次心跳发送
Hadoop中的所有心跳机制均采用pull通信模型,即master从不会主动与slave通信,而总是被动的等待slave汇报信息并领取其对应的命令。TaskTracker周期性的向JobTracker汇报信息就是这种模式。
在TaskTracker中的run方法中,维护一个无线循环,用于通过心跳发送状态信息和接收命令,代码如下:
boolean denied = false; // 是否JobTracker拒绝TaskTracker的心跳报告 while (running && !shuttingDown && !denied) { // 如果当然TaskTracker处于运行状态,而且jetty服务器运行正常,并且没有被JobTracker拒绝请求,那么就一直循环 boolean staleState = false; // 状态信息 try { // This while-loop attempts reconnects if we get network errors while (running && !staleState && !shuttingDown && !denied) { // 外面的条件加上如果状态信息为false,那么就一直循环,这种方式是为了保证,当网络出现问题的时候,能够重新连接。 try { State osState = offerService(); // 进行具体和JobTracker的通信 if (osState == State.STALE) { // 返回的状态不正常 staleState = true; } else if (osState == State.DENIED) { // 返回的状态不正常 denied = true; } } catch (Exception ex) { // 异常处理 } } } finally { close(); // 只要是出现异常,或者是退出死循环,那么都关闭资源,重新启动资源 } if (shuttingDown) { return; } // 如果是jetty服务器问题,那么直接退出 initialize(); // 网络出现问题,重新连接 } if (denied) { // 如果JobTracker拒绝请求,那么关闭httpserver shutdown(); }
其中offerService中的函数代码框架是:
while (running && !shuttingDown) {// Send the heartbeat and process the jobtracker's directives // 发送心跳报告,并获取任务命令 HeartbeatResponse heartbeatResponse = transmitHeartBeat(now); if (actions != null){ // 如果命令不为空,那就处理命令 for(TaskTrackerAction action: actions) { if (action instanceof LaunchTaskAction) { // 如果命令为启动task命令 addToTaskQueue((LaunchTaskAction)action); } else if (action instanceof CommitTaskAction) { // 提交task命令 ... } else { .... } } } markUnresponsiveTasks(); // 杀死一定时间内无反应的任务 killOverflowingTasks(); // 当磁盘空间少于mapred.local.dir.minspacekill时候,寻找合适的任务将其杀死以释放空间。
TaskTracker的单次心跳发送过程为:
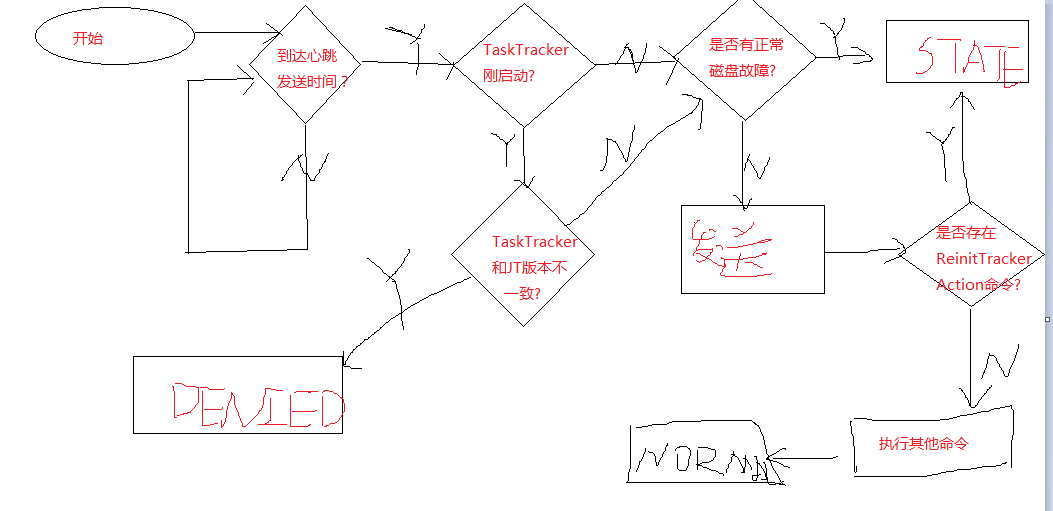
步骤1: 判断是否到达心跳发送时间
心跳发送时间由集群的规模和任务的运行情况来决定。JobTracker能够根据当前集群的规模和状态动态调整心跳间隔,并将下一次的心跳间隔时间放到应答中返回给TaskTracker。任务运行情况,当TaskTracker发送有任务或者job执行失败,就会立即缩短间隔时间,以便将任务完成或者任务失败的信息发送给JobTracker,进而可以快速的分配新的任务,主要作用是为了提高任务的响应时间和资源的利用率。需要配置参数:
mapreduce.tasktracker.outofband.beartbeat: 决定是否启用,默认为flase,不启用。
mapreduce.tasktracker.outofband.hearbeat.damper: 心跳收缩因子。默认值为10000。
计算时间间隔算法为:(heartbeatInterval / (numFinishedTasks * oobHeartbeatDamper + 1)),其中heartbeatInterval为从JobTracker端获取的心跳间隔时间(默认为3000),numberFinishedTasks为完成的任务个数,oobHeartbeatDammper为收缩因子的值。
步骤2: 如果TaskTracker刚启动,检查TaskTracker和JobTracker的版本信息是否一致
只有与JobTracker的版本信息一致,才可以发送心跳报告。版本信息由hadoop版本号,修订版本号,代码编译用户和校验和四部分组成。比如:"1.0.0 from 12555 by kashad source checksum 423dcd5a752eddd8e45ead6fd5ff9a24",hadoop版本号2.5.0,修订版本号为12555,编译者为kashad,校验和为423dcd5a752eddd8e45ead6fd5ff9a24。
步骤3: 检测磁盘是否损坏
由于存储中间结果的输入目录(mapred.local.dir)是存储在本地的,而且没有备份文档,所以当磁盘出现损坏的时候,需要TaskTracker重新初始化。TaskTracker周期性(间隔由mapred.disk.healthChecker.interval决定,默认为60s)的检查磁盘是否损坏。
步骤4: 发送心跳
TaskTracker将当前节点的运行信息发送给JobTracker,同时接收JobTracker的各种命令。
步骤5: 接收并执行各种命令
主要分为三种:job重新运行命令,TaskTracker重新初始化命令,其他命令。
待续................