怎样验证好的relations?
最小化冗余,使得其在每个属性(column)中只出现一次,除非这些属性全部或部分担任的是foreign keys的角色。
为何这不是个好design?

冗余!

冗余会导致异常:
1. 插入异常:由于没有某些属性信息,而该属性又不能为 null,导致无法插入。
比如新录用了一个lecturer, 系里还没生成lecturer的lecID, 就导致无法插入该lecturer的信息到表格里

2. 删除异常:只想删除一条信息却连带的删除了其他信息。
若该系仅有的两位lecturer退休,将则两位lecturer的信息从database里删除,则该dept的相关信息也丢失了

3. 更新异常:更新一条记录却连带的需要更新其他多条记录。
若电话系统更新,deptPhone换掉,则所有带deptPhone的table都要连带更新

函数依赖(functional dependency)
类似于函数 y = x2 当x = 2时,可以确定y = 4; 但是当y等于4时,不能确定x = 2(也可能等于-2)
也就是说,若relation R中存在 x-> y(函数依赖中,x 决定 y),则有t1[x] = t2[x] (都为a)可以确定t1[y] = t2[y] (都为b)
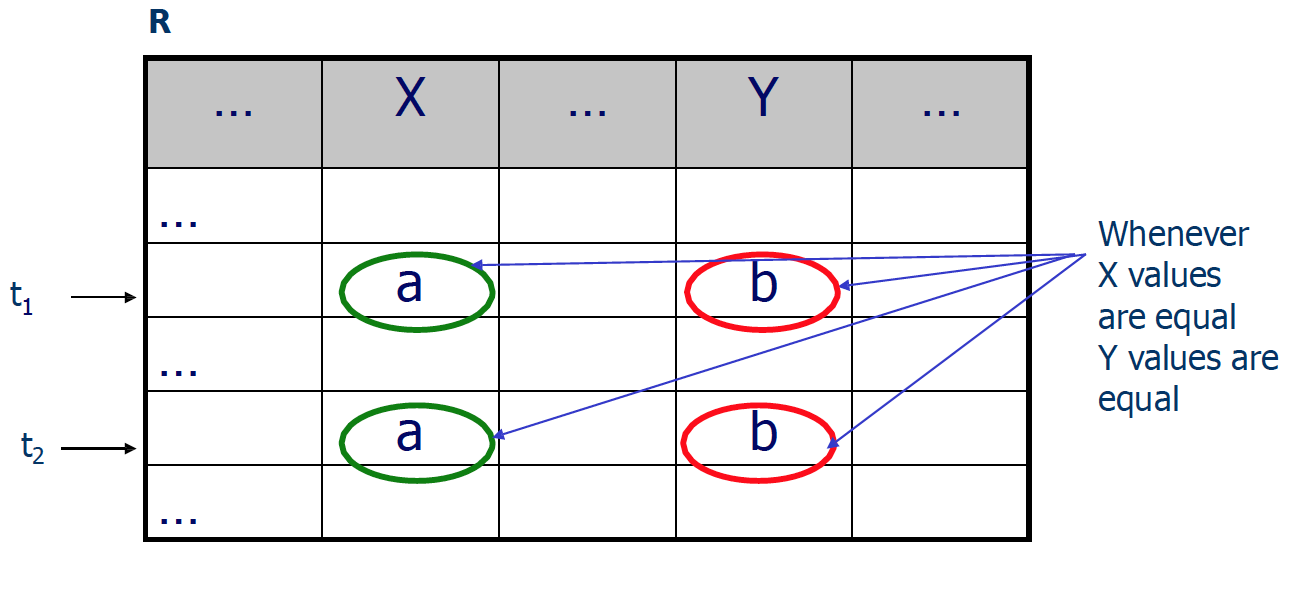
完全函数依赖 X、Y 是表的属性或属性组,若 X → Y,且对于 X 的任何一个真子集(假如属性组 X 包含超过一个属性的话),X → Y 成立,那么我们称 Y 完全函数依赖于 X 。
比如: lectID -> deptCode
lectID可以确定deptCode
部分函数依赖 X、Y 是表的属性或属性组,若 X → Y,且存在 X 的一个真子集(假如属性组 X 包含超过一个属性的话),X → Y 成立,那么我们称 Y 部分函数依赖于 X 。

比如: lectID, name -> deptCode
可以看到(lectID, name)的组合键可以确定deptCode, 但组合键的一个部分lectID就可以确定deptCode
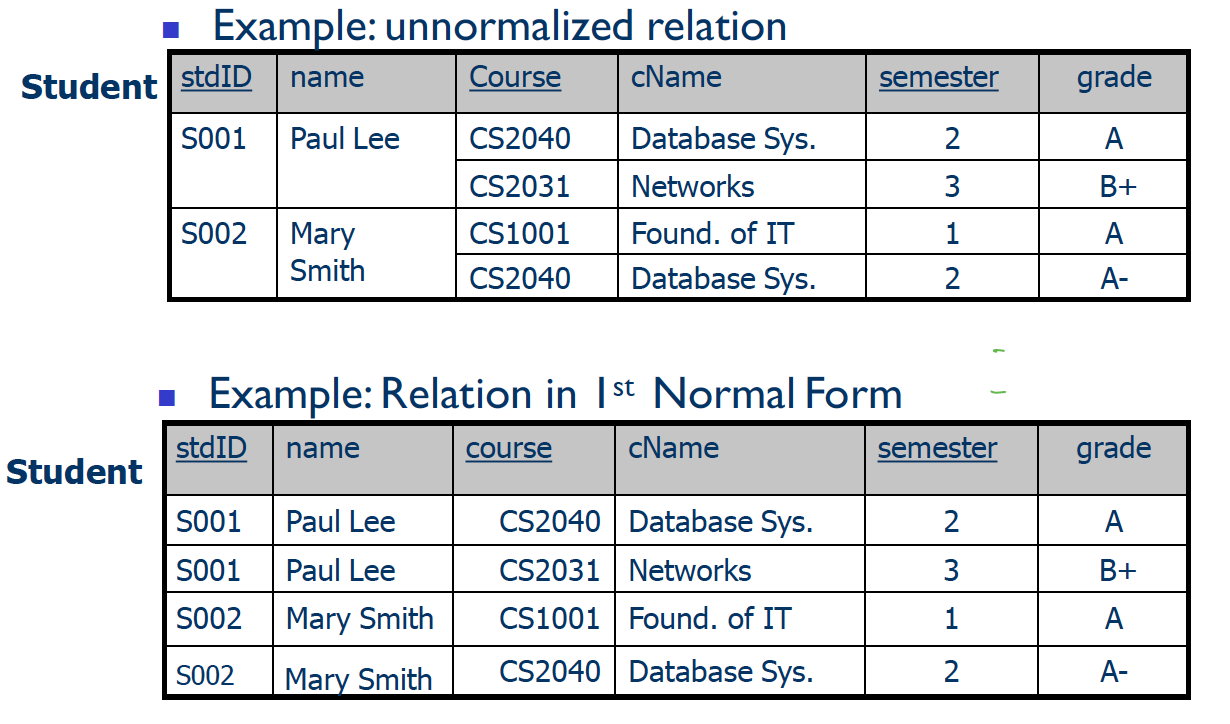
第一范式(1NF,First Normal Form): 列不再分
总结
1. 一个表如果每一行都是唯一,并且任何行都没有包含多个值的列,则它满足1NF。但对于关系表来说,真正的规范化过程从第二范式开始,因为关系表本身已经满足1NF了。
2. 要满足1NF就要保证数据在实际使用时, 不用对列(column)进行二次拆分(原子性)
3. 1NF主要处理颗粒大的行(row)
4. 仍然存在四个问题: 插入异常,删除异常,更新异常,数据冗余
第二范式(2NF,Second Normal Form):消除非主属性对码的部分函数依赖
总结
1. 解决列(column)部分依赖主键(复合主键)的问题
2.在实际中,几乎不用复合主键,因此可以完美避免违背第二范式
3. 插入异常和数据冗余问题有改进,但仍存在,仍存在删除异常和更新异常。
第三范式(3NF,Third Normal Form):消除非主属性对码的传递函数依赖
Boyce-Codd 范式(BCNF,Boyce-Codd normal form)