(接上文《架构设计:系统存储(23)——数据一致性与Paxos算法(上)》)
2-1-1. Prapare准备阶段
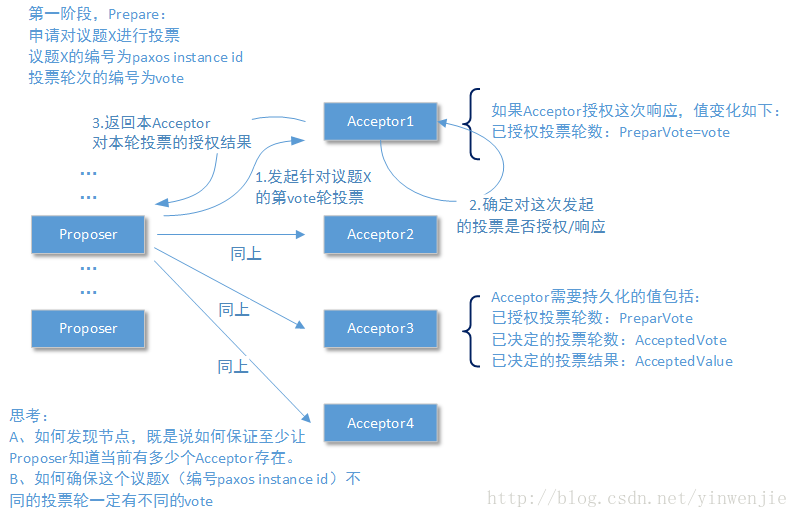
首先需要介绍几个在Acceptor角色上需要被持久化保存的数据属性:
- PrepareVote保存了当前Acceptor接收到的已完成投票授权的最大投票轮次
- AcceptedVote保存了当前Acceptor在赋值阶段完成投票赋值的投票轮次
- AcceptedValue保存了当前Acceptor在赋值阶段被赋予的值
1、第一个阶段Proposer和Acceptor至少要完成一次网络通讯,其主要目的是确定针对提议X的当前投票轮次是否能被授权。换句话说,根据Acceptor在准备阶段的工作原则,即使确定当前投票轮次的编号值是大于Acceptor中记录的PrepareVote的值。处理过程很简单,即Proposer向所有Acceptor发出关于发起提议X的新一轮投票的申请,并等待各个Acceptor进行响应。当然会有一个超时时间,如果超过这个时间还没有得到Acceptor的响应,则认为已经被拒绝。如果有超过N/2 + 1个节点在规定的时间内没有回复响应,那就说明整个选举系统发现了问题,则终止操作抛出错误,向客户端反馈异常信息。
2、收到这个发起新的一轮投票操作的授权请求后,各个Acceptor开始判断是否可以进行授权。判断的原则只与PrepareVote有关,既是如果当前申请的投票轮次小于等于PrepareVote的赋值,则拒绝授权;其它情况都要接受授权,并更改PrepareVote属性为当前新的投票伦次编号。这里有一个隐藏含义,即这个Acceptor新授权的投票轮次编号,一定大于之前PrepareVote的值。
3、Proposer将负责汇总所有Acceptor的响应情况,并根据汇总的情况判断下一步的操作。无论Acceptor是授权这次投票还是拒绝这次投票,给出的响应信息中都最好包括当前Acceptor所记录的PrepareVote、AcceptedVote和AcceptedValue信息,这样有利于Proposer分析为什么会被Acceptor拒绝。下图展示了Proposer在汇总所有Acceptor的响应时可能出现的各种情况:
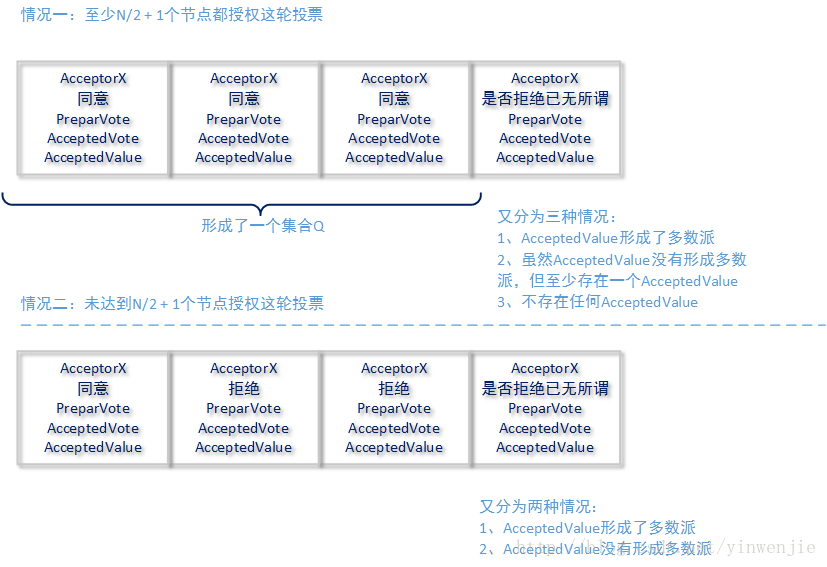
当然还有一种情况三,就是超过(包括)N/2 + 1个Acceptor节点在规定的时间内没有反馈结果,这种情况直接判定Paxos系统崩溃,所以就不做进一步讨论了。请注意,无论是上图的哪种情况,只要至少N/2 + 1个Acceptor节点的AcceptedValue为同一个值,就认为提议X的结果达到了最终一致,整个Paxos算法过程也结束。
3.1、在Proposer得到的响应情况一中,至少N/2 + 1个Acceptor允许这轮投票。这些Acceptor就形成了一个集合Q,这个集合Q将继续下一步骤的操作。这时集合Q中的Acceptor是否已有AcceptedValue就很重要了:如果集合Q中没有任何一个Acceptor的AcceptedValue属性有值,则当前Proposer会在下一步提议自己的值为集合Q中每一个Acceptor的赋值目标;如果集合Q中至少存在一个Acceptor的AcceptedValue属性有值,则Proposer会选择一个AcceptedVote最大的AcceptedValue属性值,作为当前Proposer会在下一步进行Acceptor赋值的目标。
3.2、在Proposer得到的响应情况二中,始终未达到N/2 + 1个Acceptor允许这轮投票——无论是不满足Acceptor的授权原则还是Acceptor超时未响应。只要至少N/2 +1个Acceptor所回复的AcceptedValue属性值相同,则表示针对提议X已经形成了最终一致的结果,无需再进行投票了。否则,Proposer会将自己的投票轮次编号进行增加后,再发起投票——这个增加规则后续再讨论,读者目前可以认为是+1。
2-1-2. Accept赋值阶段
一旦有N/2 + 1个Acceptor节点授权了本轮投票,Proposer就可以进入第二阶段——赋值阶段,第二阶段将以上一阶段形成的多数派集合Q作为操作目标。如下图所示:
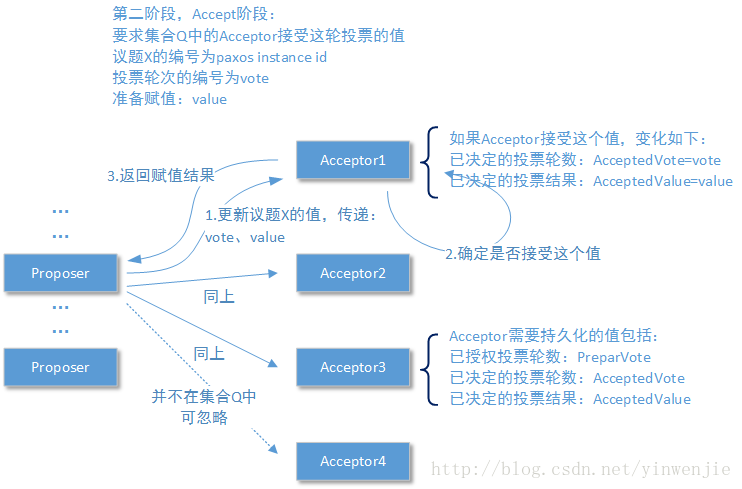
1、Proposer将会以上一阶段3.1步骤中所确定的value和自己的vote一起发送给集合Q中的每一个Acceptor,并等待回复。
2、Acceptor收到赋值请求后,将会按照判断原则确认是否进行赋值。这个判断原则上文已经说过了,这里再说一次。如果当前收到的vote小于当前Acceptor的PrepareVote属性值,则不会进行赋值。为什么Acceptor上的PrepareVote会发生变化呢?这是因为在这个Proposer从第一阶段到第二阶段的操作间隙,另一个或者多个Proposer使用编号更大的vote发起了更新一轮的投票,并得到当前Acceptor的授权。如果当前收到的vote等于当前Acceptor的PrepareVote属性值则接受这次赋值,这时Acceptor将更改其AcceptedVote属性为vote,更改其AcceptedValue属性为value。
注意一种情况,Acceptor会不会在第二阶段操作时收到一个vote大于当前PrepareVote的赋值请求呢?这是不会的,因为任何Acceptor要更换PrepareVote,只可能更换比当前PrepareVote更大的值,所以之前被Acceptor同意授权的vote一定会小于或者等于当前Acceptor的PrepareVote属性值。
3、赋值操作完成后,Acceptor将向Proposer返回赋值操作后的AcceptedValue属性和AcceptedVote属性。换句话说就是,即使Acceptor拒绝了第二阶段的赋值操作,也要向Proposer返回AcceptedValue属性值。以下为Proposer端汇总统计时,可能出现的情况:
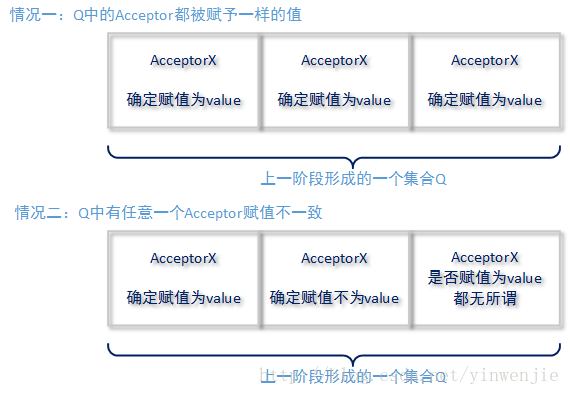
3.1、Acceptor收到集合Q中所有Acceptor的赋值结果后,就会进行汇总判断。如果发现所有赋值结果都是一样的value,则认为针对议题X形成了最终一致的结果。整个投票过程结束,value就是达成的最终值。
3.2、如果收到集合Q中所有Acceptor的赋值结果,并进行比较的过程中,发现任何一个赋值结果不一致,则认为赋值操作失败。这时Proposer会将自己的投票轮次编号进行增加后,再回到第一阶段重新发起投票。
2-1-3. 分析一种极端情况
Paxos算法的一个核心思路在于形成多数派决议,要形成核心思路Acceptor就必须按照自己的两个工作原则进行授权操作和赋值操作。这就是为什么我们在介绍Paxos算法时经常提到N/2 + 1的边界节点数量的原因。因为一旦形成多数派,决定最终一致性的关键表决就可以落在唯一一个节点上,也就是说如果第X1轮投票和第X2轮投票如果都同时拿到了多数派Acceptor的授权,那么它们的核心战略点就是要去抢占授权X1投票的Acceptor集合和授权X2投票的Acceptor集合求交集后至少存在一个的Acceptor节点。好消息是赋值阶段X1轮投票的编号和X2轮投票的编号总是不同的,也总有大小差异的,而Acceptor的工作方式决定了它只会接受编号更大的投票操作的赋值。
这个原理可以扩展到任意多个Proposer,那么有的读者会问了,会不会出现一种每个Acceptor的AcceptedValue属性都被赋值,且都没有达到多数派的特殊情况呢(如下图所示)?
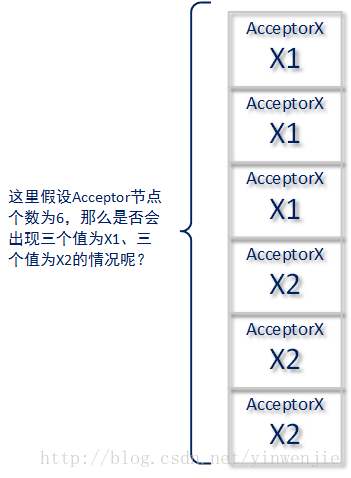
答案是不会的,本小节我们将使用反向论证证的方式来进行阐述。首先要出现三个X1的赋值结果Proposer1便不能继续赋值这样的现象,只可能是一种情况即Proposer1在经过两阶段操作,并在进行Acceptor1~Acceptor3赋值的时候,后者三个节点上PrepareVote等于Proposer1的Vote,而在Proposer1准备进行后续三个节点赋值时,却发现Acceptor4~Acceptor6的PrepareVote改变了。如下图所示:
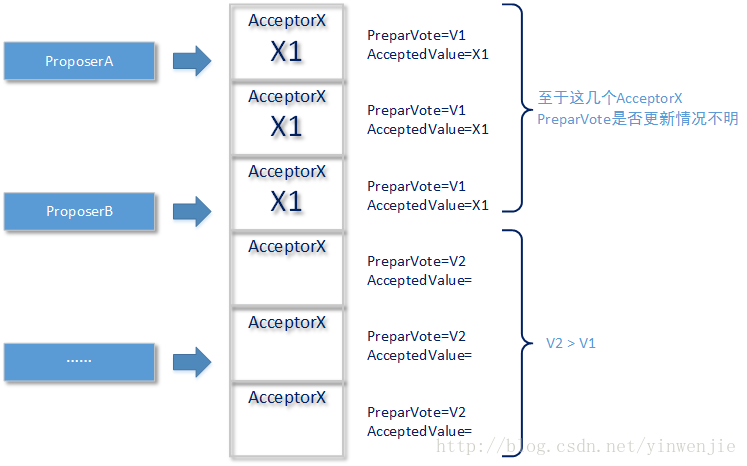
这时发起V2轮次投票的ProposerB,有两种情况,如下图所示:
第一种情况ProposerB还没有接收到至少N/2 + 1个Acceptor节点的授权结果,还处于第一阶段(这里Acceptor节点个数为6个,所以至少应该收到4个Acceptor的授权结果),这时ProposerB会一直等待汇总,如果等待超时都没有收到必要数量的结果,那么ProposerB继续增加它的投票编号,并重新发起。这时同样能够保证Acceptor集合不被之前的Proposer继续赋值——因为投票编号仍然最大。
如果是上图所示的第二种情况,就更简单了。ProposerB节点已经收到了至少4个Acceptor节点的授权结果,而这4个Acceptor节点,至少有一个节点携带了AcceptedValue为X1的值——因为目前被赋予X1的Acceptor节点个数,刚好为一半3个节点,和N/2 + 1个节点求交集后,至少有一个重叠的Acceptor节点(注意,基数为偶数,如果为奇数就更不会出现我们现在讨论的极端情况了)。也就是说当ProposerB节点进入第二阶段赋值操作时,向剩余Acceptor节点传递的值同样为X1,而不是自身原始提议的X2,所以最终本小节最初所述的极端情况不会出现。
2-1-4、一种投票轮次的初始和增加规则
在目前我们讨论的设计中,提到一个投票轮次的确定问题。不同Proposer发起的投票可以不一定全局递增,而同一个Proposer必须保证自己的发起的新一轮投票编号vote,一定是递增的(增量必须为1吗?这个不一定)。这是因为Acceptor在第一阶段的工作原则是,只接受vote大于当前PrepareVote的新一轮投票授权,那么对于某个Proposer而言,最不济的情况就是无论自己本身如何发起新一轮的投票,都不会得到Acceptor的授权,而最终结果只能听命于别的Proposer所提议的值。
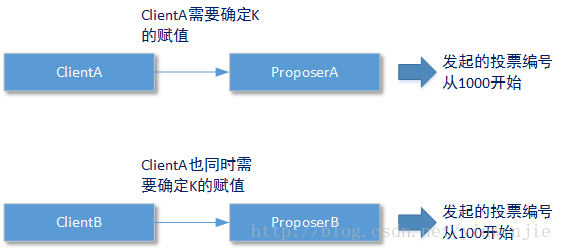
很显然上图中无论ProposerB如何发起新一轮投票,都会在第一阶段被Acceptor拒绝掉,因为至少有一个Proposer的投票轮次编号一直比他的大。这种算法的简便处理方式虽然一定程度上降低了代码的编写难度,但是只能算作伪算法实现(目前很多系统为了平衡性能、维护性和实现难易度,都会采用这种方式),因为所有投票轮次的发起和赋值只会听从于唯一一个Proposer,在算法的执行过程中根本就不会出现投票冲突的情况;另一个方面,对并发状态下无法最终确认选值的Client来说也不公平,因为所有Client对最终赋值的选择也只会听命于唯一一个Client(忘了说了,Client是整个Paxos中另一个角色,这个角色负责向对应的Proposer提交需要进行表决的提案)。所以我们需要一种投票轮次编号递增的方式,来保证不同轮次的投票请求真正的竞争起来。
有的读者可能第一个想到的就是zookeeper这样的分布式协调器来生成编号,保证编号的唯一性和递增性,甚至很多学术资料、网络文章上都有提到使用这样的方式。拜托!要是能够使用zookeeper解决这个问题,那我们还实现Paxos算法干什么?所有解决冲突的工作都交给zookeeper就好了嘛。之所以要实现Paxos算法,就是因为要建造一个和ZK同属一个工作层的协调组件,所以关于编号的问题就只能自己想办法了。
这里介绍一种对投票轮次的编号方式,可以有效减少编号冲突,并在针提案X的投票过程中真正产生竞争。这个编号方式的前提条件是,各个Proposer工作在局域网环境下,并能通过组播的方式发现对方。在各个Proposer内部有一个使用Proposerid进行排序后的Proposer集合列表。这时就可以通过余数原则进行编号了:

(N × V) + index + 1,这个公式中,N表示集合大小,V表示投票轮次(从0开始),index表示当前Proposer所在集合的位置索引。例如,设N==4时,id为1的存在于这个有序集合列表第一个索引位置的Proposer,可以使用的投票编号就是1、5、9、13……,存在于这个有序集合列表第二个索引位置的Proposer,可以使用的投票编号就是2、6、10、14、18……,存在于这个有序集合列表第三个索引位置的Proposer,可以使用的编号就是3、7、11、15、19……
那么这样的编号设计就不会重复了吗?当然会,特别是在整个Paxos算法系统的启动阶段。例如整个Paxos算法中所有N个节点的Proposer都已经启动了,但是某个Proposer上还暂时只发现了N-2个Proposer节点,这样该Proposer计算得出的自己所使用的编号,就可能和另外某个Proposer所计算得出的自己使用的编号重复。而且这个差异还与使用的不同节点发现方式而不同,例如在后续文章中给出的Basic-Paxos算法实现代码中,就使用组播方式进行Proposer节点发现,而这种节点发现方式就会使每个Proposer节点上的节点发现进度在Paxos算法系统启动之初出现不一致。
不过好消息是,Acceptor在第一阶段的工作原则中,只会授权大于当前AcceptedVote的投票申请(此时AcceptedVote <= PrepareVote)。也就是说当两个或者多个持有相同投票伦次的Proposer向同一个Acceptor申请投票授权时,Acceptor只会授权其中一个,另一个的授权申请将被Acceptor拒绝,这就保证了有相同投票轮次编号的授权请求在同一个Acceptor上不会被重复同意,那么这些有同样投票轮次编号的Proposer就可以决定自己是否拿到了授权多数派。如果没有拿到授权,当Proposer集合稳定存在后,就会有新的且更大的投票轮次编号了。
===============
(接下文)