1.drbd简介
drbd是通过网络(tcp连接)在不同服务器之间实现基于block级别进行数据实时同步的软件。类似于inotify+rsync,只不过inotify+rsync是按文件级别来同步的,而drbd是工作在文件系统下层的,实现的是block同步和拷贝,效率相对较高。且inotify+rsync是通过监控事件来实现实时同步的,而drbd则跟普通写入磁盘的过程一样,只不过多了一条写入网卡的分支路线。
如下图,此处只是简单的示意图。更具体的原理图见下文。
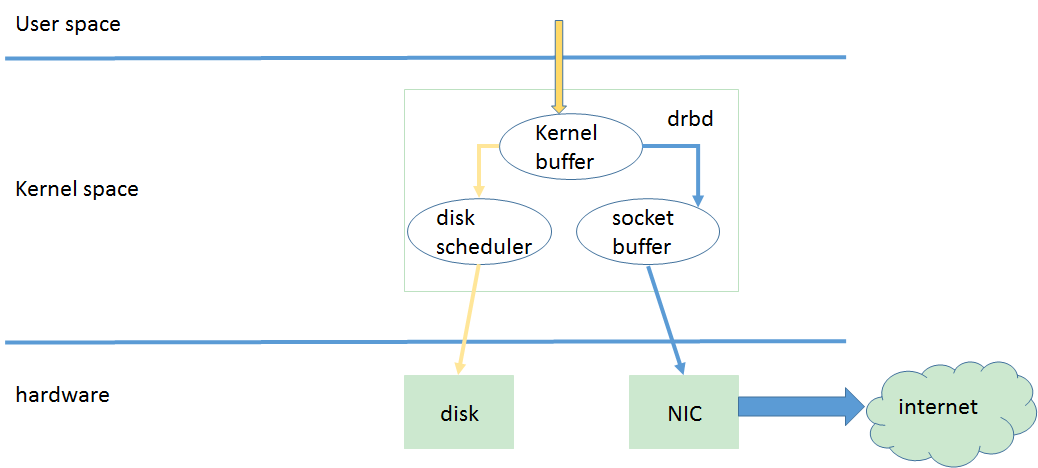
drbd只能在分区上、LVM逻辑卷上或整块磁盘上实现,不能在某一个目录上实现。 drbd支持同步、半同步、异步三种数据同步的方式。 drbd支持脑裂(brain split)通知和自动恢复。
2.drbd工作原理和术语说明
drbd的核心功能是通过Linux内核模块实现的。特别地,操作系统中的虚拟块设备(virtual block device)中有它的驱动,因此drbd几乎处于操作系统I/O堆栈的"最底部"。这使得它非常具有弹性,可以很容易地为服务提供高可用性。 但注意,drbd处于文件系统之下的层次,不能实现文件系统层次的功能,例如检查文件是否损坏、为文件系统提供高可用等。但它是基于block的,可以做块设备检查、同步的完整性检查等。
2.1 drbd工作原理
drbd实现基于块级别的数据同步,其实现方式是通过tcp连接来镜像整个设备。
它有主备节点的概念。在主节点上,可以对drbd设备创建文件系统以供读取,甚至可以直接IO。在主节点写入的数据通过DRBD设备存储到主节点的磁盘设备中,同时,这个数据块也会通过网络传输到备节点对应的DRBD设备上,最终写入备用节点的磁盘设备上实现同步。在备用节点上,DRBD只是将数据从DRBD设备写入到备用节点的磁盘中,无法供外界读、写,之所以连读都提供,是为了维护缓存一致性(cache coherency)的问题。
现在大部分的高可用集群都会使用共享存储,在实时同步以及数据一致性角度而言,drbd能代替共享存储。而且,drbd可以配合高可用软件,实现高可用服务的切换而不会数据丢失,因为备节点和主节点数据是实时同步的,这样给用户的体验是更好的,但却节约了成本,其性能与稳定性方面也不错。
下图是drbd的原理图。
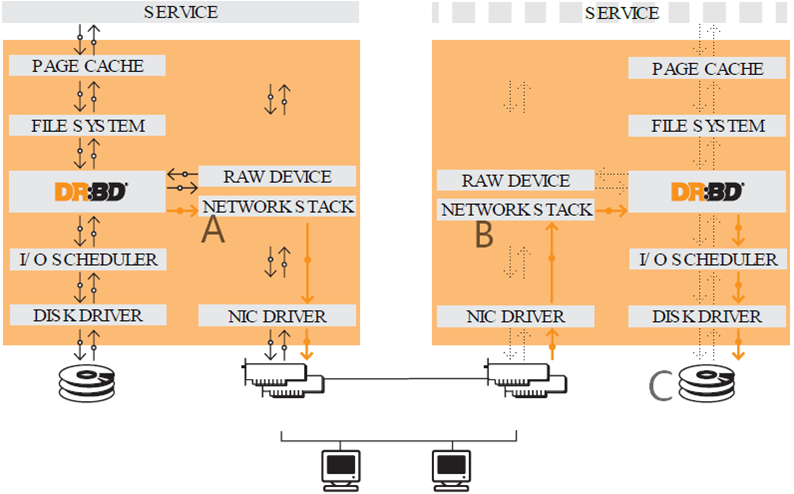
对于正常的文件系统,写入数据的流程:buffer-->filesystem--> disk scheduler-->disk driver-->disk。
而使用drbd时,流程是上图中的红色箭头。在filesystem的下一层加上drbd层,该层将写入的数据通过drbd发送到tcp套接字的send缓存(send buffer),再通过DMA的方式拷贝到网卡,由网卡发送到备节点。备节点的drbd设备从tcp套接字的recv缓存(recv buffer)中接收数据,然后从drbd设备读出数据并等待disk scheduler调度写入到磁盘中。
如果不理解或者理解的不清晰,可先阅读:不可不知的socket和TCP连接过程。
其中A/B/C是drbd复制的协议级别,如下"drbd复制模型"所述。
2.2 drbd复制协议模型
上面drbd工作原理图中的A、B、C对应的是drbd的不同复制模型。复制模型指的是数据的写入执行到哪个过程就认为此次写操作已经完成。
drbd有三种复制协议:同步、半同步、异步。
A协议:异步复制(asynchronous),如上图A标识,指的是当数据写到本地磁盘上,并且复数据已经复制到tcp的send buffer缓冲区以后,此时就认为写入磁盘成功。此复制协议性能好,但可能会丢失一些最近的数据。
B协议:半同步复制(semi sync),也称为内存复制,如上图B标识,指的是数据已经写到本地磁盘上,并且已经被对方的tcp协议栈接收到(即写入到了对方的recv buffer中),此时就认为此次写操作成功。此复制协议性能较好,且只有当两节点都断电时才会丢失最近处于socket buffer中的数据。因此性能和数据可靠性介于协议A和C之间。
C协议:同步复制(sync),如上图C标识,指的是数据已经写入到本地磁盘,也已经写入到远程磁盘上,此时就认为此次写操作成功。此复制协议性能较差,但数据可靠性高。
C复制协议是drbd默认使用的协议。
2.3 DRBD设备的概念
DRBD设备是操作系统中的一个虚拟块设备,在Linux上游内核中已经集成了DRBD的块设备模块和驱动。它的主设备号(major)为147,次设备号默认从0开始编号。
在一组主机上,drbd设备的设备名称为/dev/drbdN,这个N通常和它的次设备号一致。
DRBD需要构建在底层设备之上,然后构建出一个块设备出来。对于用户来说,一个DRBD设备,就像是一个分区,可以在上面创建文件系统。DRBD所支持的底层设备有以下这些类:
- 1、磁盘或磁盘的某一个分区;
- 2、软 raid 设备;
- 3、LVM的逻辑卷;
- 4、EVMS(企业卷管理系统,Enterprise Volume Management System);
- 4、其他任何的块设备,甚至DRBD块设备自身也能成为另一个DRBD的底层设备。
2.4 drbd资源角色
在drbd构造的集群中,资源具有角色的概念,分别为primary和secondary(主从的概念)。
所有primary的资源将不受限制进行读写操作,可以创建文件系统,可以使用裸设备,可以直接io。而所有secondary的设备中不能挂载,不能读、写。
2.5 drbd工作模式
-
主从模型master/slave(primary/secondary)
这种机制在某一时刻只允许有一个主节点。主节点的作用是可以挂载使用,写入数据等;从节点只是作为主节点的镜像,是主节点的备份,且是不可见的。
这样的工作机制的好处是可以有效的避免磁盘出现单点故障,而且数据不会错乱。 -
双主模型dula primary(primary/primary)
所谓双主模型是2个节点都可以当做主节点来挂载使用。但会导致数据错乱。当第一个主节点对某一文件正在执行写操作,此时另一个节点也正在对同一文件执行写操作,这种情况会造成数据错乱,从而导致数据不能正常使用。
解决双主模型数据混乱的方案是:使用集群(分布式)文件系统,如gfs2。集群文件系统使用分布式文件锁管理器,当一个节点对文件加锁之后会通过某种机制来通知其他节点锁信息,从而实现文件锁共享。
也可以将两节点的不同drbd设备分别设置主从,从而实现双主模型。例如服务器A上的a分区(主)和服务器B上的a分区(从),同时服务器A上的b分区(从)和服务器B上的b分区(主)。
2.6 分区说明
drbd分为两种分区。其中一个分区是metadata区,用于存储元数据,给个1G就够了,2G就非常多了;另一种分区是数据区,这是drbd块设备的底层设备。因此,大多数情况下需要在drbd的两节点上创建两个分区,分别作为metadata区和data区。
注意,metadata区也可以和数据区在同一分区,这时metadata区称为"内部元数据区(Internal metadata)"。
关于分区有几点注意:
- 数据区创建完成后不能挂载。
- metadata分区创建完成后不能格式化,也就是不能创建文件系统(要交给drbd来处理)。
- 建议两边的数据分区大小给一样的,否则一端会浪费空间。如何解决此问题后文说明。
3.drbd部署实验
绝大多数情况下,drbd都是两节点的,要么是主从工作模式(primary/secondary),要么是结合集群文件系统的主主模式(primary/primary)。很少情况下,可以添加一个第三节点,作为backup角色。
drbd节点最好部署在使用专门的网络环境下,节点之间可以使用直连模式、back-to-back模式或使用高速网卡。如果中间跨了交换机,建议加上Linux的网卡绑定功能(如不了解,请百度"bonding驱动")。不建议drbd节点之间跨路由器,这会严重影响性能。
drbd两节点之间的数据区应尽量差不多大小。