13. 内存管理

#define NODES_SHIFT CONFIG_NODES_SHIFT
#define MAX_NUMNODES (1 << NODES_SHIFT)
这里主要介绍UMA机制。contig_page_data被定义如下:
struct pglist_data __refdata contig_page_data = { .bdata = &bootmem_node_data[0] };
EXPORT_SYMBOL(contig_page_data);
struct pglist_data即是pg_data_t的原型。了解pg_data_t中的结构成员对于了解内存管理是必经之路:
struct zone node_zones[MAX_NR_ZONES];
struct zonelist node_zonelists[MAX_ZONELISTS];
#ifdef CONFIG_FLAT_NODE_MEM_MAP /* means !SPARSEMEM */
#ifdef CONFIG_CGROUP_MEM_RES_CTLR
struct page_cgroup *node_page_cgroup;
...... /* for CONFIG_MEMORY_HOTPLUG */
unsigned long node_present_pages; /* total number of physical pages */
unsigned long node_spanned_pages; /* total size of physical page
wait_queue_head_t kswapd_wait;
- node_zones:当前节点中包含的最大管理区数。MAX_NR_ZONES在include/linux/bounds.h定义,该文件是在编译过程中根据管理区类型定义中的__MAX_NR_ZONES变量自动生成的。
- node_zonelists: 内存分配器所使用的管理区链表数组,MAX_ZONELISTS的值在配置CONFIG_NUMA时为2,否则为1。索引为0的链表表示后援 (Fallback)链表,也即当该链表中的第一个不满足分配内存时,依次尝试链表的其他管理区。索引为1,的链表则用来针对GFP_THISNODE的 内存申请,此时只能申请指定的该链表中的管理区。
- nr_zones:指定当前节点中的管理区数,也即node_zones中实际用到的管理区数。它的取值范围为[1, MAX_NR_ZONES]。对于UMA来说,它的值为1。
- node_mem_map:节点中页描述符数组首地址。
- node_page_cgroup:
- bdata:系统引导时用的Bootmem分配器。
- node_start_pfn:节点中第一个页框的下标。
- node_present_pages:节点中的页面数,不包含孔洞。
- node_spanned_pages:节点中的页面总数,包含孔洞。
- node_id:节点标识符,在节点数组中唯一存在。
- kswapd_wait:kswapd页换出守护进程使用的等待队列。
- kswapd: 指针指向kswaps内核线程的进程描述符。
- kswapd_max_order:kswapd将要创建的空闲块大小取对数的值。
/* Maximum number of zones on a zonelist */
#define MAX_ZONES_PER_ZONELIST (MAX_NUMNODES * MAX_NR_ZONES)
struct zonelist_cache *zlcache_ptr; // NULL or &zlcache
struct zoneref _zonerefs[MAX_ZONES_PER_ZONELIST + 1];
struct zonelist_cache zlcache; // optional ...
节点中的管理区都在free_area_init_core函数中初始化。调用关系如下所示:
最后一种限制不仅存在于80x86,而存在于所有的体系结构中。为了应对这两种限制,Linux把每个内存节点的物理内存划分为多个(通常为3个)管理区(zone)。在80x86 UMA体系结构中的管理区为:
/* Fields commonly accessed by the page allocator */
unsigned long pages_min, pages_low, pages_high;
unsigned long lowmem_reserve[MAX_NR_ZONES];
struct per_cpu_pageset pageset[NR_CPUS];
struct free_area free_area[MAX_ORDER];
/* Fields commonly accessed by the page reclaim scanner */
unsigned long recent_rotated[2];
unsigned long recent_scanned[2];
unsigned long pages_scanned; /* since last reclaim */
unsigned long flags; /* zone flags, see below */
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
- pages_min,记录管理区中空闲页的数目。
- pages_low,回收页框使用的下届,同时也被管理区分配器作为阈值使用。
- pages_high,回收页框使用的上届,同时也被管理区分配器作为阈值使用。
- lowmem_reserve,指明在处理内存不足的临界情况下每个管理区必须保留的页框数目。
- pageset,单一页框的特殊告诉缓存。
内核为了尽可能保证一个原子内存分配请求成功,它为原子内存分配请求保留了一个页框池,只有在内存不足时才使用。保留内存的数量存放在min_free_kbytes变量中,单位为KB。
/* min_free_kbytes = sqrt(lowmem_kbytes * 16); */
lowmem_kbytes = nr_free_buffer_pages() * (PAGE_SIZE >> 10);
min_free_kbytes = int_sqrt(lowmem_kbytes * 16);
名称 | 大小 |
pages_min | min_free_kbytes >> (PAGE_SHIFT - 10) |
pages_low | pages_min * 5 / 4 |
pages_high | pages_min * 3 / 2 |
free_area_init_core中对管理区初始化的代码部分如下,后续章节将对该函数进一步分析。
zone->present_pages = realsize;
spin_lock_init(&zone->lru_lock);
zone->prev_priority = DEF_PRIORITY;
INIT_LIST_HEAD(&zone->lru[l].list);
unsigned long flags; /* Atomic flags, some possibly
atomic_t _count; /* Usage count, see below. */
atomic_t _mapcount; /* Count of ptes mapped in mms,
* & limit reverse map searches.
每一个物理页框都需要一个对应的page结构来进行管理:记录分配状态,分配和回收,互斥以及同步操作。对该结构成员的解释如下:
- flag域存放当前页框的页标志,它存储了体系结构无关的状态,专门供Linux内核自身使用。该标志可能的值定义在include/linux/page-flags.h中。
- 原子计数成员_count则指明了当前页框的引用计数,当该值为0时,就说明它没有被使用,此时在新分配内存时它就可以被使用。内核代码应该通过page_count来访问它,而非直接访问。
- 原子计数成员_mapcount表示在页表中有多少页指向该页框。在SLUB中它被inuse和objects代替。
PG_locked, /* Page is locked. Don't touch. */
以上是页标志位的可能取值,通常不应该直接使用这些标志位,而应该内核预定义好的宏,它们在相同的头文件中被定义,但是它们是被间接定义的,也即通过##连字符来统一对它们进行定义。
#define TESTPAGEFLAG(uname, lname)
static inline int Page##uname(struct page *page)
{ return test_bit(PG_##lname, &page->flags); }
PAGEFLAG(Referenced, referenced) TESTCLEARFLAG(Referenced, referenced)
宏 | 扩展函数/宏 | 用途 |
TESTPAGEFLAG(uname, lname) | Page##uname | 测试PG_##lname位 |
SETPAGEFLAG(uname, lname) | SetPage##uname | 设置PG_##lname位 |
CLEARPAGEFLAG(uname, lname)[a] | ClearPage##uname | 清除PG_##lname位 |
TESTSETFLAG(uname, lname) | TestSetPage##uname | 测试并设置PG_##lname |
TESTCLEARFLAG(uname, lname) | TestClearPage##uname | 测试并清除PG_##lname |
PAGEFLAG(uname, lname)[b] | TESTPAGEFLAG | 当于同时扩展了三个宏,也即三个函数 |
PAGEFLAG_FALSE(uname) | Page##uname | 永远返回0 |
TESTSCFLAG(uname, lname) | TESTSETFLAG | 当于同时扩展了两个宏,也即两个函数 |
SETPAGEFLAG_NOOP(uname) | SetPage##uname | 空操作 |
CLEARPAGEFLAG_NOOP(uname) | ClearPage##unam | 空操作 |
__CLEARPAGEFLAG_NOOP(uname) | __ClearPage##uname | 空操作 |
TESTCLEARFLAG_FALSE(uname) | TestClearPage##uname | 永远返回0 |
[a] 以上三个宏分别对应test_bit,set_bit和clear_bit,是原子操作,与它们对应的是有三个开头 [b] 与此对应也有__PAGEFLAG的宏存在。 | ||
_count引用计数不应被直接引用,内核提供了一系列的内联函数来操作它,通常它们被定义在include/linux/mm.h中。
函数名 | 用途 |
page_count | 读取引用计数 |
get_page | 引用计数加1 |
init_page_count | 初始化引用计数为1 |
_mapcount与_count引用计数类似,不应被直接引用,内核提供了一系列的内联函数来操作它,它们也被定义在include/linux/mm.h中。
函数名 | 用途 |
reset_page_mapcount | 初始化引用计数为-1[a] |
page_mapcount | 读取引用计数并加1的值 |
page_mapped | 该函数根据引用计数值是否大于等于0,判断该页框是否被映射。 |
[a] 没有初始化为0是因为atomic_inc_and_test和atomic_add_negative的操作,对该引用计数的加减是由这两个函数完成的。 | |
union {
struct {
unsigned long private; /* Mapping-private opaque data:
* usually used for buffer_heads
* if PagePrivate set; used for
* swp_entry_t if PageSwapCache;
* indicates order in the buddy
* system if PG_buddy is set.
*/
struct address_space *mapping; /* If low bit clear, points to
* inode address_space, or NULL.
* If page mapped as anonymous
* memory, low bit is set, and
* it points to anon_vma object:
* see PAGE_MAPPING_ANON below.
*/
};
#if USE_SPLIT_PTLOCKS
spinlock_t ptl;
#endif
struct kmem_cache *slab; /* SLUB: Pointer to slab */
struct page *first_page; /* Compound tail pages */
};
union {
pgoff_t index; /* Our offset within mapping. */
void *freelist; /* SLUB: freelist req. slab lock */
};
struct list_head lru; /* Pageout list, eg. active_list
lru是一个表头,用于在各种量表上维护该页框,以便将它按不同类别分组,最重要的就是zone->lru_lock保护的活动页框(active_list)和不活动页框。
#if defined(WANT_PAGE_VIRTUAL)
void *virtual; /* Kernel virtual address (NULL if
#endif /* WANT_PAGE_VIRTUAL */
WANT_PAGE_VIRTUAL是由是否需要高端内存决定的,virtual用于寻址高端内存区域中的页框,存储该页的虚拟地址。有些时候高端内存并不映射到任何实际的物理地址页框上,此时它的值为NULL。
struct membank bank[NR_BANKS];
static unsigned long __init bootmem_init_node(int node, struct meminfo *mi);
bootmem_free_node与bootmem_init_node参数类似,它用来初始化特定内存节点的管理区信息。
static void __init bootmem_free_node(int node, struct meminfo *mi);
- 尽管局部zone_size和zhole_size声明为大小为MAX_NR_ZONES的数组,但是只用到了其中的第一个元素。这是由于ARM Linux采用了UMA方式的内存管理机制。
- zone_size[0]被赋值为end_pfn - start_pfn,然后根据zone_size减去meminfo中每个membank中真正的size得到内存孔洞的大小zhole_size[0]。
- 通过arch_adjust_zones为特定架构的系统预留内存。通常用它来为特定的限制的DMA寻址预留内存,将这些DMA无法访问的内存放入zone[1],而DMA对应zone[0],通常DMA可以寻址所有内存。
- 最后调用free_area_init_node初始化节点对应的pg_data_t描述符信息,并且为每个页表分配struct page结构。
#define arch_adjust_zones(node,size,holes) do { } while (0)

void __paginginit free_area_init_node(int nid, unsigned long *zones_size,
unsigned long node_start_pfn, unsigned long *zholes_size)
- nid,节点ID号。
- zones_size,大小为MAX_NR_ZONES的数组,用来记录当前内存节点中的内存页框数,包含孔洞。
- node_start_pfn,当前内存节点中的起始内存页框。
- zholes_size,大小为MAX_NR_ZONES的数组,用来记录当前内存节点中的内存孔洞页框数。
- 根据参数nid,确定该节点对应的pgdat,并初始化成员node_id = nid。
- pgdat->node_start_pfn = node_start_pfn。
- 通过calculate_node_totalpages函数,计算pgdat->node_spanned_pages(包含孔洞)和pgdat->node_present_pages(不含孔洞)。
- 每一个物理页框对应一个struct page结构,通过alloc_node_mem_map为所有的物理页面分配该结构体空间,并将起始页框地址保存在pgdat->node_mem_map中。
- 调用free_area_init_core,用来初始化内存管理区zone。
* Set up the zone data structures:
* - mark all memory queues empty
static void __paginginit free_area_init_core(struct pglist_data *pgdat,
unsigned long *zones_size, unsigned long *zholes_size);
- pgdat,内存节点对应的pgdat_t类型描述符。
- zones_size,大小为MAX_NR_ZONES的数组,用来记录当前内存节点中的内存页框数,包含孔洞。
- zholes_size,大小为MAX_NR_ZONES的数组,用来记录当前内存节点中的内存孔洞页框数。
free_area_init_core针对单个内存节点内的所有管理区进行初始化,并计算管理内存页所用的struct page数组占用的memmap_pages。
- 通过pgdat_resize_init函数初始化pgdat自旋锁成员node_size_lock,它与CONFIG_MEMORY_HOTPLUG(内存热插拔)有关。
- 初始化pgdat->nr_zones为0。
- 通过init_waitqueue_head函数初始化pgdat->kswapd_wait,它是kswapd页换出守护进程使用的等待队列。
- 初始化pgdat->kswapd_max_order为0。
- 通过pgdat_page_cgroup_init函数初始化pgdat->node_page_cgroup为NULL,如果没有打开CONFIG_CGROUP_MEM_RES_CTLR选项,则为空函数。
- 计算含有孔洞的页面总数存入size,同时zone->spanned_pages记录该值。
- 计算不含孔洞的页面总数存入realsize。
- 根 据size变量计算页面数组所占用的页面数,存入memmap_pages。之所以不使用realsize,是因为在通过 alloc_node_mem_map函数来分配页面管理数组时采用的含有孔洞的页面数,这是为了管理方便,但是在有大量孔洞的内存节点中,这样会浪费大 量struct page页面管理结构,所以通常会使能内存的CONFIG_DISCONTIGMEM选项。
- 如果处理管理区是DMA区,那么将在realsize中再次为DMA预留内存。也即realsize再次减去dma_reserve。
- 将realsize减去页面映射使用的页面大小memmap_pages并存入zone->present_pages。
- 通过is_highmem_idx判断当前内存区是否为高端内存,如果不是,那么将realsize计入内核全局统计信息nr_kernel_pages,它描述了内核所有可以一一映射的页。
- 将realsize计入nr_all_pages,与nr_kernel_pages类似,它还记录了高端内存页。
- 如果定义了CONFIG_NUMA,则初始化管理区中的node,min_unmapped_pages和min_slab_pages成员。
- 为zone->name赋值,它指向zone_names数组中对应的当前管理区的值
- 使用spin_lock_init初始化管理区中的lock和lru_lock自旋锁。
- 如果配置了CONFIG_MEMORY_HOTPLUG,那么初始化自旋锁span_seqlock。与lock和lru_lock不同,它通过seqlock_init函数完成初始化。
- 设置prev_priority为DEF_PRIORITY。
- 初始化管理区中的回调指针zone_pgdat,显然它指向该区所属的内存节点类型pgdat指针。
- zone_pcp_init初始化管理区的per-CPU缓存。
- 初始化lru成员。
- 初始化recent_rotated和recent_scanned成0。
- 通过函数zap_zone_vm_stats初始化vm_stat成员为0。
- 初始化flags成员为0。
- 如果打开了CONFIG_HUGETLB_PAGE_SIZE_VARIABLE选项,则通过pageblock_default_order函数获取默认值并设置给全局变量pageblock_order,否则默认值为MAX_ORDER-1。它被用在伙伴系统中。
- setup_usemap设置pageblock_flags为NULL。如果该区包含的页框数满足要求,那么为pageblock_flags分配内存并初始化为0。pageblock_flags与伙伴系统的碎片迁移算法有关。
- init_currently_empty_zone初始化伙伴系统的free_area列表。
- 最后通过memmap_init宏间接引用函数memmap_init_zone将属于该管理区的所有page数组都设置为初始默认值。
- zone_start_pfn记录下一循环处理的管理区的开始页框地址。
memmap_init_zone函数初始化每个管理区中的页帧对应的page数组。
#ifndef __HAVE_ARCH_MEMMAP_INIT
#define memmap_init(size, nid, zone, start_pfn)
memmap_init_zone((size), (nid), (zone), (start_pfn), MEMMAP_EARLY)
void __meminit memmap_init_zone(unsigned long size, int nid, unsigned long zone,
unsigned long start_pfn, enum memmap_context context);
- size指明了管理区的页帧数,它包含孔洞。
- nid是当前管理区所属的内存节点的编号。
- zone指明了当前管理区在内存节点中node_zones数组下标。
- zone_start_pfn则提供了当前管理区的第一个页帧的编号。
- context是为了指明当前是在系统初始化阶段,还是热插拔阶段对内存管理页的初始化。它只有两个值:MEMMAP_EARLY和MEMMAP_HOTPLUG。
- 通过end_pfn = start_pfn + size得到终止页帧,然后从start_pfn到end_pfn通过循环一次处理它们对应的struct page。
- 如果context指定的系统状态是MEMMAP_EARLY,则需要判断当前页帧是否存在,这是因为内存孔洞的存在。[10]
- 根据公式page = pfn_to_page(pfn),由页帧得到它对应的struct page管理项。
- 设 置page中flags成员的Field Area,它由段区,管理区和节点区三部分组成,分别占用的位数由SECTIONS_WIDTH,ZONES_WIDTH和NODES_WIDTH分别表 示。set_page_links函数的作用就是分别通过set_page_zone,set_page_node和set_page_section函 数来设置这些字段区。以后就可以根据这些区域获取当前页帧的位置信息。
- mminit_verify_page_links用来验证set_page_links设置的信息是否正确。
- 通过init_page_count将page->_count成员初始化为1。
- 通过reset_page_mapcount将page->_mapcount成员初始化为-1。
- 通过由宏定义展开后的函数SetPageReserved设置PG_reserved标记到page->flags中。
- 设置所有页面均为MIGRATE_MOVABLE的。
- 初始化page->lru。
- 如果配置了WANT_PAGE_VIRTUAL,且不为高端内存则初始化virtual成员。比如SPARC系统。
include/asm-generic/memory_model.h
#if defined(CONFIG_FLATMEM)
#ifndef ARCH_PFN_OFFSET
#define ARCH_PFN_OFFSET (0UL)
#endif
......
#define __pfn_to_page(pfn) (mem_map + ((pfn) - ARCH_PFN_OFFSET))
#define __page_to_pfn(page) ((unsigned long)((page) - mem_map) +
ARCH_PFN_OFFSET)
......
#ifdef CONFIG_OUT_OF_LINE_PFN_TO_PAGE
struct page;
/* this is useful when inlined pfn_to_page is too big */
extern struct page *pfn_to_page(unsigned long pfn);
extern unsigned long page_to_pfn(struct page *page);
#else
#define page_to_pfn __page_to_pfn
#define pfn_to_page __pfn_to_page
#endif /* CONFIG_OUT_OF_LINE_PFN_TO_PAGE */
在struct page管理数组是线性分布的时候,pfn_to_page被统一定义为__pfn_to_page。平坦内存中的ARCH_PFN_OFFSET被定义 为0,而mem_map在alloc_node_mem_map中被赋值为node_mem_map,也即管理数组的首地址。
page中flags成员的Field Area由三部分组成,它们从高地址位该是依次分布。段区只有在配置了CONFIG_SPARSEMEM时才有可能存在。
/* .....
*
* No sparsemem or sparsemem vmemmap: | NODE | ZONE | ... | FLAGS |
* classic sparse with space for node:| SECTION | NODE | ZONE | ... | FLAGS |
* classic sparse no space for node: | SECTION | ZONE | ... | FLAGS |
*/
build_all_zonelists在init/main.c中的start_kernel中被调用,它用来初始化内存分配器使用的存储节点中的管理区链表。
void build_all_zonelists(void)
if (system_state == SYSTEM_BOOTING) {
cpuset_init_current_mems_allowed();
/* we have to stop all cpus to guarantee there is no user
stop_machine(__build_all_zonelists, NULL, NULL);
/* cpuset refresh routine should be here */
vm_total_pages = nr_free_pagecache_pages();
if (vm_total_pages < (pageblock_nr_pages * MIGRATE_TYPES))
page_group_by_mobility_disabled = 1;
page_group_by_mobility_disabled = 0;
printk("Built %i zonelists in %s order, mobility grouping %s. "
zonelist_order_name[current_zonelist_order],
page_group_by_mobility_disabled ? "off" : "on",
- 根 据system_state查看系统的运行状态,在内核启动阶段,它的值保持为0,也即SYSTEM_BOOTING,只有在start_kernel执 行到最后一个函数rest_init后,才会进入SYSTEM_RUNNING阶段。如果为内核启动阶段,那么调用 __build_all_zonelists初始化分配器管理区链表,否则挂起系统,显然内存管理功能初始化出现异常为致命错误。
- nr_free_pagecache_pages直接调用nr_free_zone_pages来统计系统中所有内存节点中可用的内存页框数,通常就是对present_pages成员的叠加。
- 根 据当前系统中的内存页框数目,决定是否启用流动分组(Mobility Grouping)机制,这种机制可以在分配大内存块时减少内存碎片。显然只有内存足够大时才会启用该功能,否则将得不偿失。 pageblock_nr_pages实际上是一个宏,它表示伙伴系统中的最高阶页块所能包含的页面数。
include/linux/pageblock-flags.h
#define pageblock_nr_pages (1UL << pageblock_order)
Built 1 zonelists in Zone order, mobility grouping on. Total pages: 65024
build_all_zonelists调用了一些列函数,调用流程如下所示:
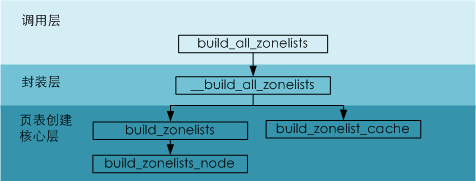
/* return values int ....just for stop_machine() */
static int __build_all_zonelists(void *dummy)
pg_data_t *pgdat = NODE_DATA(nid);
static void build_zonelist_cache(pg_data_t *pgdat)
pgdat->node_zonelists[0].zlcache_ptr = NULL;
static void build_zonelists(pg_data_t *pgdat)
zonelist = &pgdat->node_zonelists[0];
j = build_zonelists_node(pgdat, zonelist, 0, MAX_NR_ZONES - 1);
for (node = local_node + 1; node < MAX_NUMNODES; node++) {
j = build_zonelists_node(NODE_DATA(node), zonelist, j,
for (node = 0; node < local_node; node++) {
j = build_zonelists_node(NODE_DATA(node), zonelist, j,
zonelist->_zonerefs[j].zone = NULL;
zonelist->_zonerefs[j].zone_idx = 0;
注意到最后一个_zonerefs元素的zone被设置为NULL,zone_idx为0,这是用来遍历时判断结尾。
static int build_zonelists_node(pg_data_t *pgdat, struct zonelist *zonelist,
int nr_zones, enum zone_type zone_type)
BUG_ON(zone_type >= MAX_NR_ZONES);
zone = pgdat->node_zones + zone_type;
&zonelist->_zonerefs[nr_zones++]);
check_highest_zone(zone_type);
- pgdat:当前存储节点对应的pg_data_t类型描述符。
- zonelist:当前存储节点对应的管理区列表,通常它通过就是pgdat->node_zonelists + 0。
- nr_zones:当前开始处理的管理区在存储节点中的编号,每处理一个管理区那么该值加1。
- zone_type:指定处理几个管理区。通常为MAX_NR_ZONES - 1。
- 返回下一个未处理的管理区的索引值。
build_zonelists_node完成了以下功能,当未开启CONFIG_NUMA时,依次映射管理区到参考链表中。
- 判定提供的zone_type参数是否正确,它不应该超过一个管理节点所能包含的最大管理区的个数。
- populated_zone是一个简单的宏:!!zone->present_pages,由于present_pages参数在free_area_init_core 被初始化为该节点中可用的内存页数realsize,所以这里的意图就是保证当天节点是否已经被初始化。
- zoneref_set_zone 设置管理节点中的成员zoneref,它记录当前管理区的地址和在管理区数组node_zones中的索引。显然在循环中,所有的初始化过的zone都是 依次从node_zones出来,放入_zonerefs的,这个顺序是倒序的。build_zonelists_node函数跟是否配置 CONFIG_NUMA相关,启用该功能将使用另一个同名函数,此函数将根据Node的各个要素权衡它们在链表中的顺序。
- check_highest_zone函数只在CONFIG_NUMA中有效。
static void zoneref_set_zone(struct zone *zone, struct zoneref *zoneref)
zoneref->zone_idx = zone_idx(zone);
注意:zoneref同时定义zone的地址和索引,看起来多此一举,这是因为在NUMA中,可能将另一个Node中的zone加入本Node中的参考链表中。