一、inputSplit
1.什么是block
块是以 block size 进行划分数据。 因此,如果群集中的 block size 为 128 MB,则数据集的每个块将为 128 MB,除非最后一个块小于block size(文件大小不能被 block size 完全整除)。例如下图中文件大小为513MB,513%128=1,最后一个块(e)小于block size,大小为1MB。 因此,块是以 block size 的硬切割,并且块甚至可以在逻辑记录结束之前结束(blocks can end even before a logical record ends)。
假设我们的集群中block size 是128 MB,每个逻辑记录大约100 MB(假设为巨大的记录)。所以第一个记录将完全在一个块中,因为记录大小为100 MB小于块大小128 MB。但是,第二个记录不能完全在一个块中,因此第二条记录将出现在两个块中,从块1开始,在块2中结束
2.什么是inputSplit
如果分配一个Mapper给块1,在这种情况下,Mapper不能处理第二条记录,因为块1中没有完整第二条记录。因为HDFS不知道文件块中的内容,它不知道记录会什么时候可能溢出到另一个块(because HDFS has no conception of what’s inside the file blocks, it can’t gauge when a record might spill over into another block)。InputSplit这是解决这种跨越块边界的那些记录问题,Hadoop使用逻辑表示存储在文件块中的数据,称为输入拆分(InputSplit)。
当MapReduce作业客户端计算InputSplit时,它会计算出块中第一个完整记录的开始位置和最后一个记录的结束位置。在最后一个记录不完整的情况下,InputSplit 包括下一个块的位置信息和完成该记录所需的数据的字节偏移(In cases where the last record in a block is incomplete, the input split includes location information for the next block and the byte offset of the data needed to complete the record)。下图显示了数据块和InputSplit之间的关系:
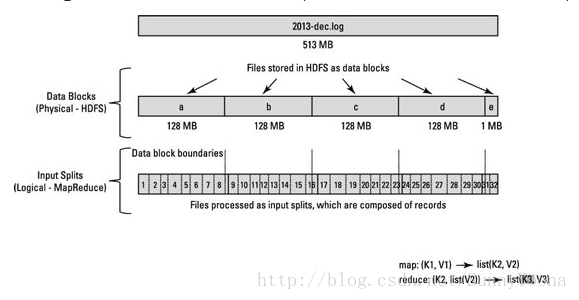
块是磁盘中的数据存储的物理块,其中InputSplit不是物理数据块。 它是一个Java类,指向块中的开始和结束位置。 因此,当Mapper尝试读取数据时,它清楚地知道从何处开始读取以及在哪里停止读取。 InputSplit的开始位置可以在块中开始,在另一个块中结束。InputSplit代表了逻辑记录边界,在MapReduce执行期间,Hadoop扫描块并创建InputSplits,并且每个InputSplit将被分配给一个Mapper进行处理。