JUnit 测试
- Junit:
- 我们写好一个方法后经常希望对其单独进行测试,从前我们都是写一个 main 方法,在 main 方法中对被测试方法进行调用。这种方式相对麻烦。
- Junit 是一个测试框架,利用它可以在不写 main 方法的情况下调用被测试方法,从而对方法中的代码进行测试。
- 要求:
- 被测试方法必须为无参数、非静态、无返回值的公共(public)方法
- 测试用类必须为public类
- 测试过程:
- 在方法上加上注解:@Test
- 导入Junit框架jar包
- 在被测试方法上执行Junit测试
- 写测试用例:
@BeforeClass在被测试类加载后立即执行,除了上述要求外还必须是静态的方法@AfterClass在被测试类释放前执行,除了上述要求外还必须是静态的方法@Before在测试方法执行前执行@After在测试方法执行后执行
XML 概述
什么是XML?
全称:Extensible Markup Language (可扩展标记语言)。
XML 技术是 W3C 组织发布的,目前遵循的是 W3C 组织于 2000 发布的 XML1.0 规范。
现实中存在大量数据,在数据之间往往又存在一定的关系,我们希望保存数据的同时又能够保存他们之间的关系。为此,XML 应用而生。是为了解决这样的需求而产生数据存储格式。
XML 是如何保存数据的?
- 允许用户自定义标签。每个标签用于描述一段数据
- 标签分为开始标签和结束标签,标签之间还可以嵌套其他标签,利用标签间的嵌套关系来保存数据之间的上下级关系
由于 XML 实质上是一段字符串,计算机可以十分方便的对他进行操作,开发人员也可以方便的阅读
XML 常见应用场景
- 传输数据 —— XML 本质上是一段字符串,具有跨平台性的特性,因此XML常被用来在不同系统之间进行数据交换。
一个典型的 Android 应用是由服务器发送信息给android客户端后,由android客户端负责展示。此时,Android 客户端是 Java+Android 开发环境的。而服务器端很可能是 C# + Windows 开发环境。如何在不同的语言、不同操作系统之间传输数据呢?XML 就是一个很好的选择。 - 配置文件 —— XML 可以在保存数据的同时保存数据之间的关系。利用这一特点,它还经常用作应用程序配置文件来使用。
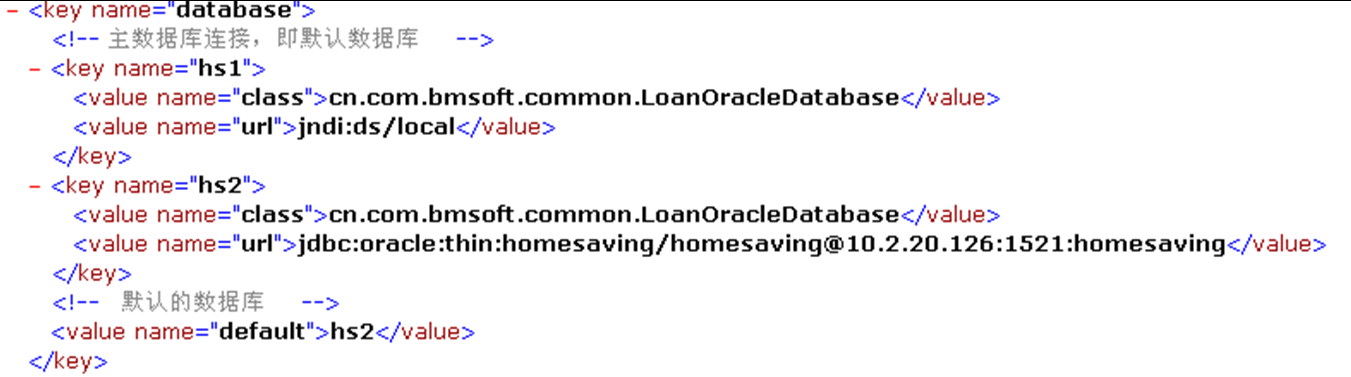
编写 XML 文件
XML 是一种存储数据的格式,我们可以将遵照这种数据格式写出来的 XML 数据保存到一个文件中去,并将文件的后缀名设定为 .xml,那么这样的保存了 XML 数据的文件就叫做 XML 文件。
XML 文件是保存 XML 数据的一种方式,XML 数据也可以以其他的方式存在(如在内存中构建XML数据),不要将 XML 语言狭隘的理解成 XML 文件。
校验 XML 文件
浏览器除了内置 HTML 解析其外还内置了 XML 解析器,因此我们可以使用浏览器对XML进行校验。
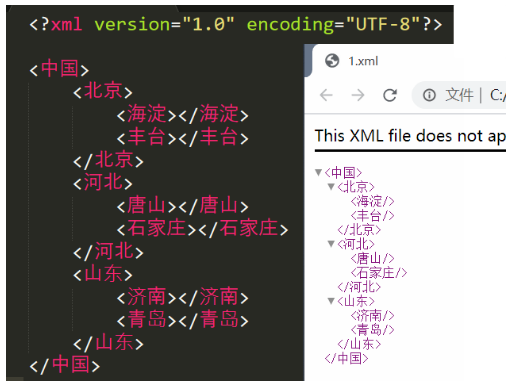

XML 语法
文档声明
- 用来声明 XML 的基本属性,用来指挥解析引擎如何解析当前 XML(XML解析器将根据 [文档声明] 决定如何正确解析一个XML)
- 通常一个 XML 都要包含且只能包含一个 [文档声明]
- xml的文档必须在整个xml的最前面,在文档声明之前不能有任何内容
- 格式:
<?xml version="1.0" encoding="utf-8" standalone="yes"?>- version(必须)
- 表明当前 XML 所遵循规范的版本
- 默认1.0
- encoding(可选)
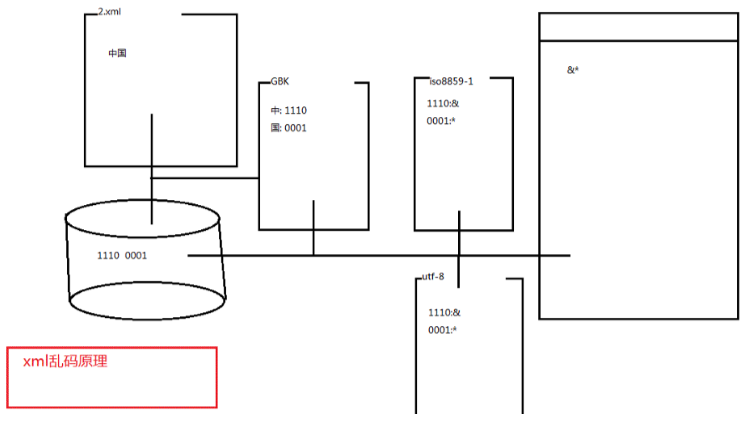
- 通知解析引擎解析xml时使用的编码(默认 ISO8859-1)
- 一定要保证xml格式的数据在保存时使用的编码和解析时使用的编码必须要一致。若编码和解码用的不是一张码表,就会有乱码问题
- standalone(可选)
- 用来指明当前 XML 是否是一个独立的 XML
- 默认 yes,表明当前文档不需要依赖于其他文档
- 如果当前文档依赖于其他文档而存在,则需要设置为no
- version(必须)
元素
- 一个 XML 标签就是一个 XML 元素
- 分类
- 标签
<a> … </a>- 分为 开始标签 和 结束标签
- 在开始标签和结束标签之间的文本被称为"标签体"
- 自闭标签
<a/>- 标签不包含"标签体" / "子标签"
- 标签
- Tips
- 一个标签中可包含若干子标签
- 标签之间要合理嵌套
- 一个格式良好的XML必须且只包含一个"根标签",其他标签都必须是这个"根标签"的"子标签"
- 对于XML标签中出现的所有空格和换行,XML 解析程序都会当作标签内容进行处理(写的时候正常写,解析器在解析的时候会进行trim操作)
<网址>www.nuist.edu.cn<网址> <网址> www.nuist.edu.cn <网址>
- 命名规范
- 区分大小写
- 不能包含空格
- 不能以 [数字] / [标点符号] / [下划线] 开头
- 不能以 xml/XML/Xml 开头
- 名称中间不能包含" : "
属性
- 一个标签可以有多个属性,每个属性都有它自己的名称和取值,例如:
<liujiaqi age="22" sex="f"/> - 属性的名字在定义的时候要遵循和 XML 元素相同的命名规则
- 属性值需要用单引号或双引号括起来
注释
- 格式:
<!-- 注释内容 --> - Tips
- 注释可以出现在任意位置,除了文件开头的文档声明之前
- 注释不能嵌套注释
CDATA区/转义字符
- CDATA区
- 当XML中一段文本(标签体)不希望被解析器解析时,将其用CDATA区包起来
- 格式:
<![CDATA[转义的内容]]>
- 转义字符

CDATA区与转义的不同:CDATA 可以保留特殊符号而转义是使用其他的符号代替特殊符号。
处理指令
- 简称 PI(Porcessing Instruction),用来指挥解析引擎如何解析 XML 文档的内容
- 格式:
<?xml-stylesheet type="text/css" href="1.css" ?>- 处理指令必须以
<?作为开头,以?>作为结尾 - 用 1.css 来渲染当前XML文件
- 加了这条指令,解析效果仿佛HTML
- 处理指令必须以
- 文档声明也是处理指令,只不过是一种特殊的处理指令
XML 约束
- 概述:编写一个文档来约束一个XML文档的写法,称为"XML约束"。
- 情景:从网上下载了一个开源框架,这个开源框架是使用XML作为配置文件的,这时候框架的设计者就需要约束我们配置文件的写法
- 作用
- 约束 XML 文档的写法
- 对 XML 进行校验
- 常见的XML约束技术
- XML DTD
- XML Schema
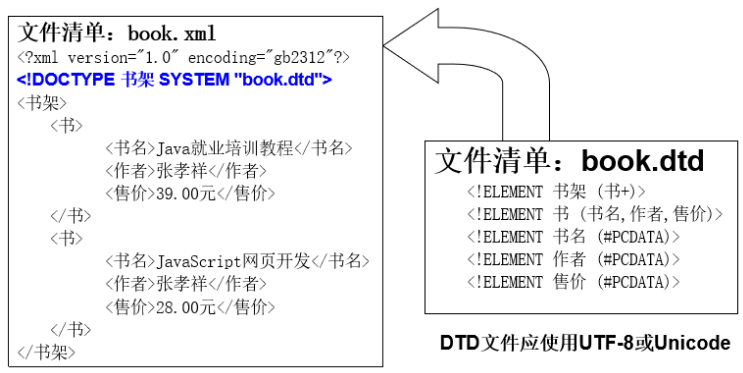
DTD
- DTD(Document Type Definition),全称为 [文档类型定义]
- 举例:
- 默认的情况下IE浏览器内置的 XML 解析器的约束校验器是被关闭了的。所以我们需要使用 JavaScript 手动创建解析器对象,打开约束校验功能,对 XML 进行约束校验。
// 创建xml文档解析器对象 var xmldoc = new ActiveXObject("Microsoft.XMLDOM"); // 开启xml校验 xmldoc.validateOnParse = "true"; // 装载xml文档 xmldoc.load("book.xml"); // 获取错误信息 xmldoc.parseError.reason; xmldoc.parseError.line
引入 DTD 约束的 2 种方式
外部引入:
- 可以将dtd的约束内容写在外置的dtd文件(必须保存成 UTF-8 格式)中
- DTD的约束也可以定义在一个独立的后缀为 .dtd 的文件中再由xml文件引入,此时引入此dtd的 XML 文档声明中standalone="no"
- 根据 dtd 文件所在位置分为
<!DOCTYPE 文档根元素 SYSTEM 文件的位置>- SYSTEM:表明当前引入的dtd在当前文件系统中,后面指定的文件位置是当前硬盘中的位置
<!DOCTYPE 文档根元素 PUBLIC "DTD名称" "DTD文件的URL">- PUBLIC:表明当前引入的dtd在网络公共位置中,后面指定dtd的名字和dtd所在网络位置URL地址
<!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN" "http://java.sun.com/dtd/web-app_2_3.dtd">
内部引入:
- 直接在 XML 中书写dtd
- DTD的约束可以定义在XML文件内部,如果DTD被定义在了XML内部则XML文档声明中
standalone="yes" - 格式
<!DOCTYPE 根元素名称 [ // dtd约束 ]>
DTD 语法
约束对象:<!ELEMENT 元素名称 {元素约束}>
- 存放类型
- EMPTY:用于定义空元素,例如
<br/>,<hr/> - ANY:表示元素内容为任意类型
- EMPTY:用于定义空元素,例如
- 元素内容 (子元素列表)
- 子元素之间使用
,分割,表示子元素必须按照顺序出现
<!ELEMENT 书架 (书名,作者,售价)> <!ELEMENT 书名 (#PCDATA)>` // 表示 包含"标签体- 子元素之间使用
|分割,子元素只出现其中之一 - 使用
+(1~n)、*(0~1)、?(0~n)等符号表示元素出现的次数 - 使用圆括号( )批量设置,如:
<!ELEMENT MYFILE ((TITLE*, AUTHOR?, EMAIL)* | COMMENT)>
- 子元素之间使用
约束属性:
<!ATTLIST 元素名
属性名1 属性类型 属性约束
属性名2 属性类型 属性约束
…
>
- 属性类型

- 属性约束

Schema
- 优点
- 本身就是一个XML,非常方便使用 XML 解析引擎进行解析
- 对 [名称空间] 有非常好的支持
- 支持更多的数据类型,并且支持用户自定义数据类型
- 可以进行语义级别的限定,限定能力大大强于dtd,就是用来替代 DTD 的
- 缺点
- 相对于dtd不支持实体
- 相对于dtd复杂得多,学习成本比较的高
- Quick Start
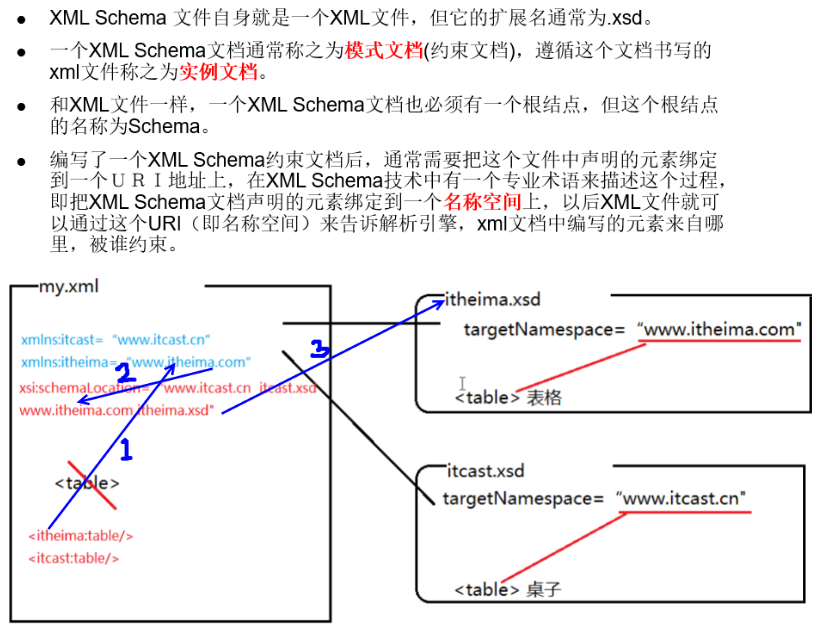
- 举例

XML 编程
利用程序去 CRUD XML 的过程就是XML编程
两种解析思想
DOM 解析
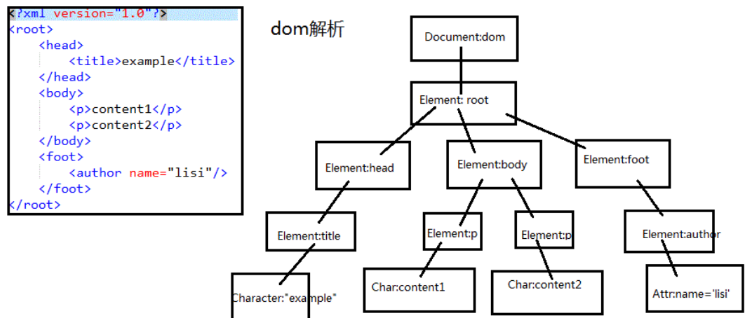
- 此接口中提供了很多CRUD方法,文档树中的所有对象都实现过这个接口

- 优点
- 便于进行CRUD操作
- 拿到 Document 对象后可以重复使用此对象,最大程度上减少解析的次数
- 缺点
- 第一次解析过程比较慢,需要将整个文档都解析完成后才能进行操作
- 需要将整个树的内容都加载到内存中来,比较耗费内存
- 当文档过大时,dom解析方式对内存的损耗非常严重
SAX 解析
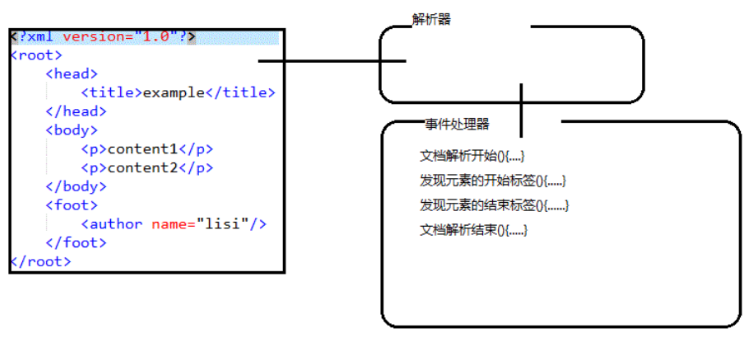
- 优点
- 不需要等待整个XML加载进内存,当解析到某一部分时自动触发到对应的方法去做处理,处理的效率比较高
- 对内存损耗比较小,无论多大的XML,理论上都可以解析
- 缺点
- 每次解析只能处理一次,下次再想处理还要重新解析
- 只能进行查询,不能进行增删改操作
解析 API
基于这两种解析思想,市面上有很多的XML解析API
- Sun—jaxp
- 既有 DOM 方式也有 SAX 方式
- 这套 API 已经加入到 J2SE 规范中,意味着不需要导入任何第三方开发包就可以直接使用这种解析方式
- 但它效率低下
- Dom4j:可以使用dom方式高效地解析XML
SAX 解析编程
public class JaxpSaxDemo {
public static void main(String[] args) throws Exception, SAXException {
// 1. 获取解析器工厂
SAXParserFactory factory = SAXParserFactory.newInstance();
// 2. 通过工厂获取SAX解析器
SAXParser parser = factory.newSAXParser();
// 3. 获取读取器
XMLReader reader = parser.getXMLReader();
// 4. 注册事件处理器
reader.setContentHandler(new ContentHandlerImpl2());
// 5. 解析XML
reader.parse("book2.xml");
}
}
book2.xml
<?xml version="1.0" encoding="UTF-8"?>
<书架>
<书>
<书名>Java编程思想</书名>
<作者>Bruce Eckel</作者>
<售价>99.9元</售价>
</书>
<书>
<书名>大话数据结构</书名>
<作者>程杰</作者>
<售价>49元</售价>
</书>
</书架>
继承 ContentHandler<I> 的默认实现类 DefaultHandler:
// Quiz:打印第二本书的书名
// [适配器设计模式]
// 空实现所有方法
class ContentHandlerImpl2 extends DefaultHandler {
boolean findIt = false;
private int count = 0;
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
if("书名".equals(qName)) {
this.findIt = true;
count++;
}
}
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
if(this.findIt && count == 2)
System.out.println(new String(ch, start, length));
}
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
if(this.findIt) this.findIt = false;
}
}
直接实现 ContentHandler<I>:
class ContentHandlerImpl implements ContentHandler {
public void startPrefixMapping(String prefix, String uri)
throws SAXException {}
public void startElement(String uri, String localName, String qName,
Attributes atts) throws SAXException {
System.out.println("开始标签:" + qName);
}
public void startDocument() throws SAXException {
System.out.println("文档解析开始了");
}
public void skippedEntity(String name) throws SAXException {}
public void setDocumentLocator(Locator locator) {}
public void processingInstruction(String target, String data)
throws SAXException {}
public void ignorableWhitespace(char[] ch, int start, int length)
throws SAXException {}
public void endPrefixMapping(String prefix) throws SAXException {}
public void endElement(String uri, String localName, String qName)
throws SAXException {
System.out.println("结束标签:" + qName);
}
public void endDocument() throws SAXException {
System.out.println("文档解析结束了");
}
public void characters(char[] ch, int start, int length) throws SAXException {
/*
API: 任何单个事件中的全部字符都必须来自同一个外部实体
char[] ch - 整个XML文档
start - 数组中的开始位置
length - 从数组中读取的字符的个数
*/
System.out.println(new String(ch, start, length));
}
}
DOM 解析编程
Quick Start:
public class Dom4jDemo {
public static void main(String[] args) throws Exception {
// 1. 获取解析器 (虽然叫SAX 但是DOM思想解析!)
SAXReader reader = new SAXReader();
// 2. 获取代表整个文档的DOM对象
Document dom = reader.read("book2.xml");
// 3. 获取根节点
Element root = dom.getRootElement();
// 4. 找第一本书的名字
// 注意啊!不能跨级取元素
String bookName = root.element("书").element("书名").getText();
System.out.println(bookName);
}
}
CRUD:
public class Dom4jDemo2 {
// 找第2本书的书名
public void find() throws Exception {
SAXReader reader = new SAXReader();
Document dom = reader.read("book2.xml");
Element root = dom.getRootElement();
List<Element> list = root.elements();
Element book2Ele = list.get(1);
System.out.println(book2Ele.element("书名").getText());
}
// 为第二本书新增<特价>标签
public void add() throws Exception {
SAXReader reader = new SAXReader();
Document dom = reader.read("book2.xml");
Element root = dom.getRootElement();
// 创建<特价>节点, 设置标签体
Element priceEle = DocumentHelper.createElement("特价");
priceEle.setText("19.9");
// 获取父标签<书>, 将<特价>节点挂在上去
Element bookEle = root.element("书");
bookEle.add(priceEle);
// 以上操作均是在内存中的DOM树进行的!
// 得把内存中的DOM树回写到XML文件中, 从而使XML中的数据进行更新
/*
FileWriter writer = new FileWriter("book2.xml");
dom.write(writer);
writer.flush(); // Writer自带缓冲区
writer.close();
*/
// 回写
writeBack(dom, "book2.xml");
}
public void update() throws Exception {
SAXReader reader = new SAXReader();
Document dom = reader.read("book2.xml");
Element root = dom.getRootElement();
root.element("书").element("特价").setText("10元");
// 回写
writeBack(dom, "book2.xml");
}
@Test
public void delete() throws Exception {
SAXReader reader = new SAXReader();
Document dom = reader.read("book2.xml");
Element root = dom.getRootElement();
Element priceEle = root.element("书").element("特价");
priceEle.getParent().remove(priceEle);
// 回写
writeBack(dom, "book2.xml");
}
public void writeBack(Document dom, String destFile) throws Exception {
XMLWriter writer = new XMLWriter(new FileOutputStream(destFile),
OutputFormat.createPrettyPrint());
writer.write(dom);
writer.close();
}
}
XPath
- 从根路径开始,即以 / 开头的绝对路径方式获取元素
例子:获取所有AAA下的BBB下的所有CCC/AAA/BBB/CCC - 使用 // 所有指定名称的元素,无论层级关系
例子:获取所有名称为AAA的元素//AAA - 使用 * 号匹配符获得所有满足条件的元素
例子:获取AAA下BBB下所有的元素/AAA/BBB/* - 使用中括号,获取多个匹配元素中的某一个,可以使用
last()获取最后一个
例子:获取AAA下所有BBB的第二个/AAA/BBB[2]
例子:获取AAA下所有BBB的最后一个/AAA/BBB[last()] - 指定某一属性:@AttName,可以配合中括号使用
例子:获取所有id属性//@id
例子:获取所有具有id属性的BBB元素//BBB[@id]
例子:获取所有不具有属性的BBB元素//BBB[not(@*)]
例子:获取属性的值为某一个固定值的BBB元素//BBB[@id='b1']
前文 #5 中提到的根接口 Node 中有一个方法:List selectNodes(String xpathExpression),释义:select Nodes evaluates an XPath expression and returns the result as a List of Node instances or String instances depending on the XPath expression.