可以把pandas看作是numpy的字典形式
array == Series 一维
array == DataFrame 二维
DataFrame有两种初始化方式:1、利用numpy(可以指定行名称和列名称) 2、利用字典
数组选择:
默认按列索引,
loc按标签索引,
iloc按数字索引
trainset.iloc[0:4, [0, 1, 2, 3, -3, -2, -1]](切片时可以利用数组进行不连续索引)
ix按标签和数字混合索
利用逻辑索引:df.B[df.A > 0] = 0,A这一列大于0的数赋值为0
df['F']=np.nan 增加F这一列
常用属性:
shape:形状
dtypes:查看各列的类型
index:行名称
columns:列名称
values:所有值
T:转置
常用函数:
describe():统计所有数字类型的列的均值、方差、最值等
sort_values(by=列名)按某一列进行排序
dropna(axis=0,how='any')how的值默认为any,表示该列有人以一个nan即删除整个列,若 选择all,则只有该列全为nan时才删除该列
fillna(value=0)
np.any(df.isnull())== True 查看是否含有空值
head()前五个数据
导入导出数据:
read_csv
to_csv
数据合并:
1、DataFrame.append(other, ignore_index=False, verify_integrity=False, sort=None)
ignore_index:默认值为False,如果为True则不使用index标签
2、concat([df1, df2, df3],axis=0,ignore_index=True,join='inner',join_axes=[df1.index])
ignore_index:使index重新排序
join:inner只保留相同的部分、outer空白部分用nan填充
join_axes:选择依据的表
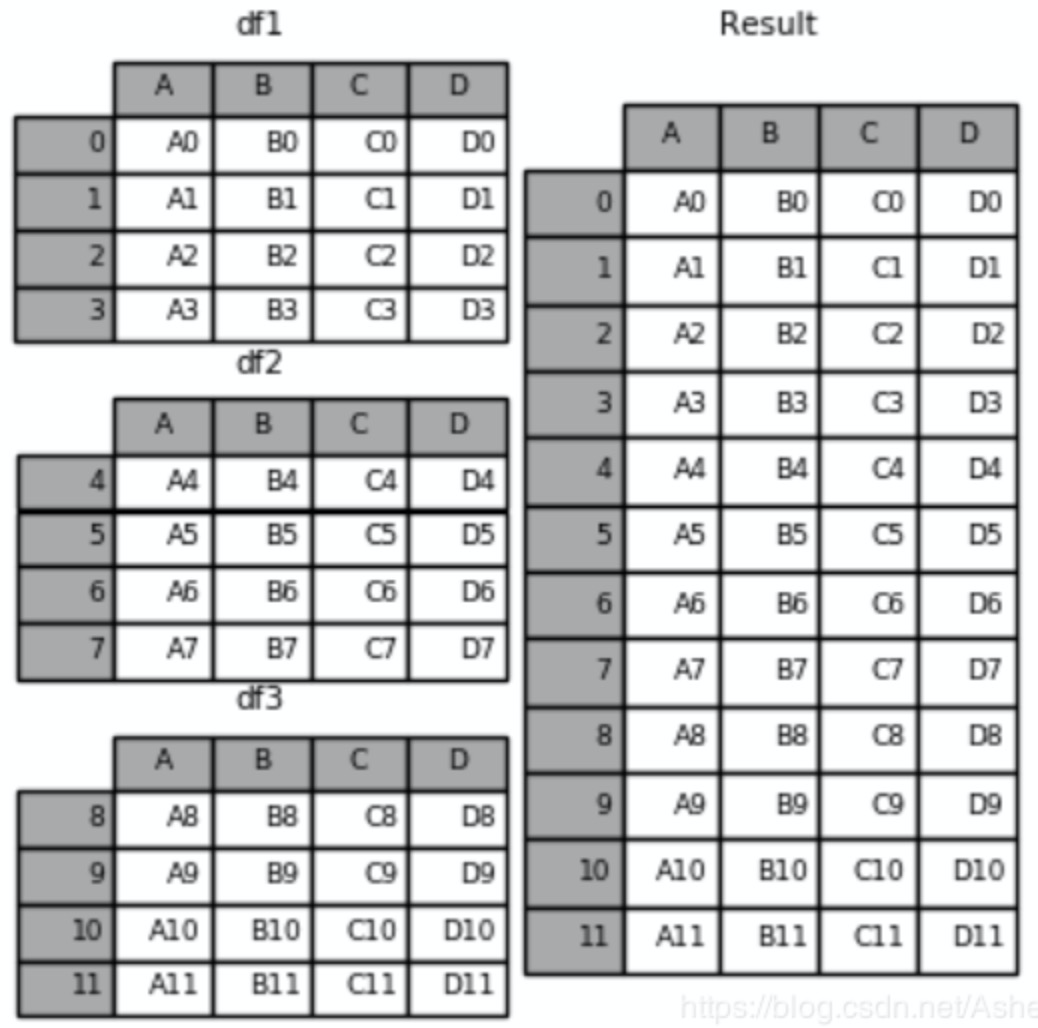
(1)pd.concat([df1,df2,df3]),默认axis=0,在0轴上合并
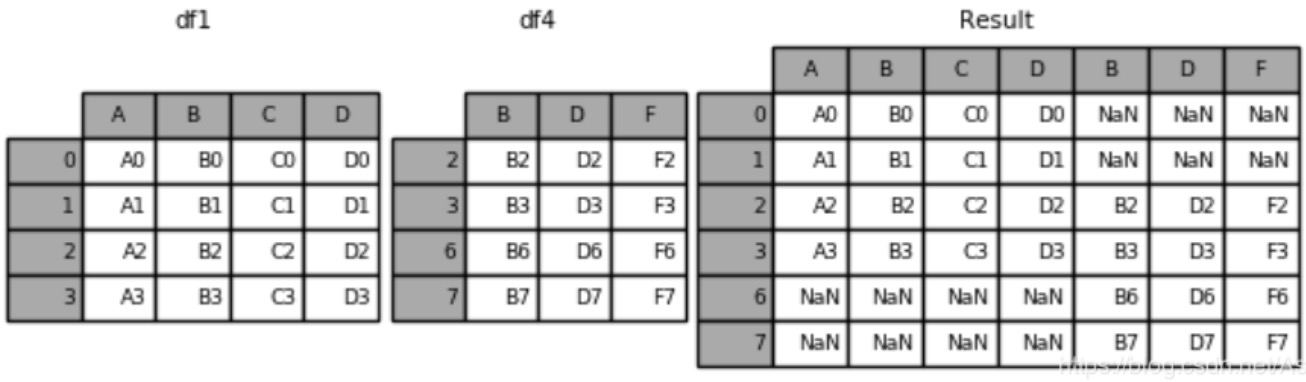
(2) pd.concat([df1,df4],axis=1)在1轴上合并
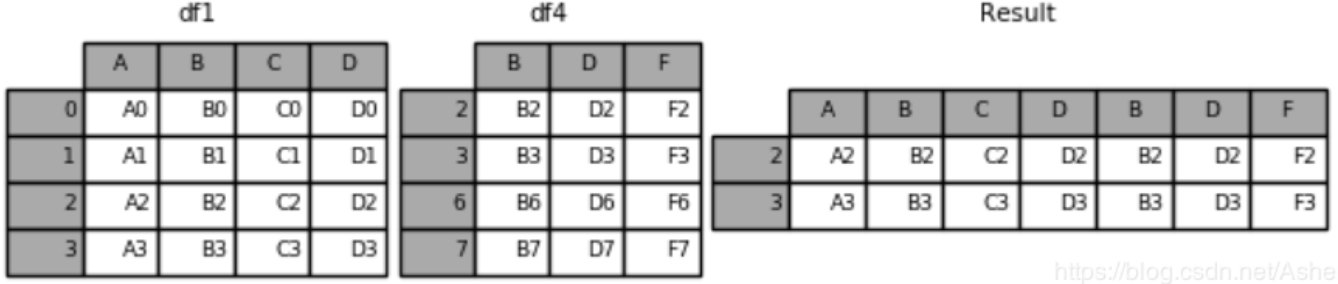
(3)pd.concat([df1, df4], axis=1, join=‘inner’)采用inner合并,join默认为outer外连接
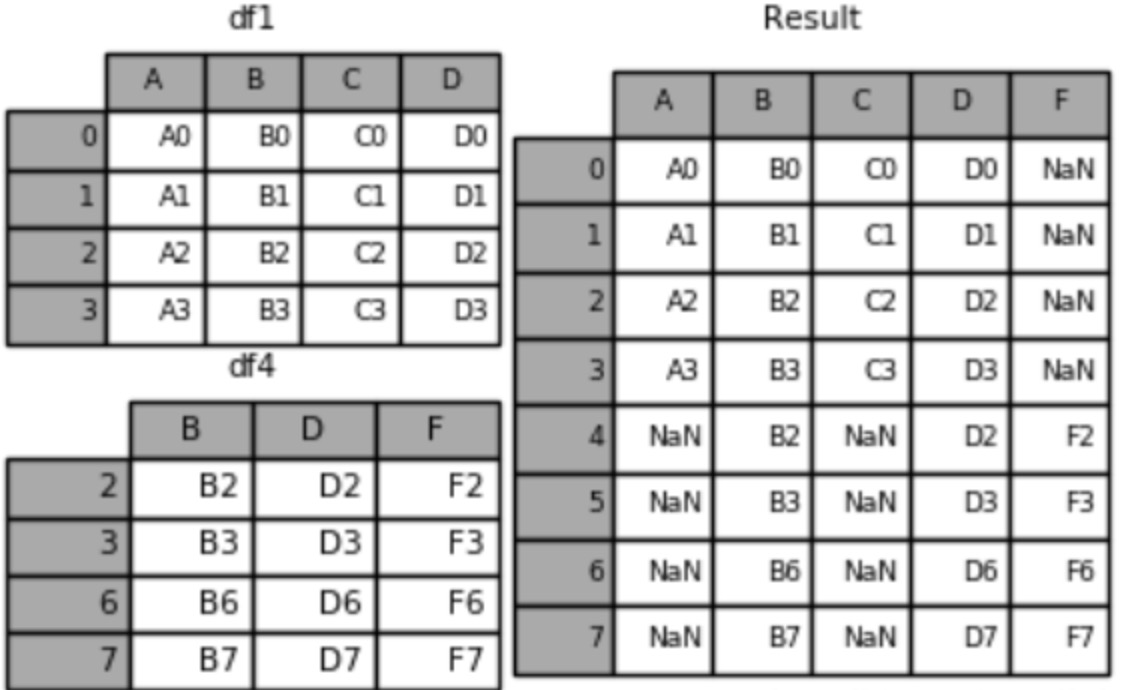
(4)pd.concat([df1, df4], ignore_index=True)当原来DataFrame的索引没有意义的时候,concat之后可以不需要原来的索引
3、merge(pd1,pd2,on=[列名],how=) 按列合并
how:left、right、inner(默认)、outer
merge(pd1,pd2,left_index=True,right_index=True,how) 按行合并