1. codecs字符串编码和解码
codecs模块提供了流接口和文件接口来完成文本数据不同表示之间的转换。通常用于处理Unicode文本,不过也提供了其他编码来满足其他用途。
1.1 Unicode入门
CPython 3.x区分了文本(text)和字节(byte)串。bytes实例使用一个8位字节值序列。与之不同,str串在内部作为一个Unicode码点(code point)序列来管理。码点值使用2字节或4字节表示,这取决于编译Python时指定的选项。
输出str值时,会使用某种标准机制编码,以后可以将这个字节序列重构为同样的文本串。编码值的字节不一定与码点值完全相同,编码只是定义了两个值集之间转换的一种方式。读取Unicode数据时还需要知道编码,这样才能把接收到的字节转换为unicode类使用的内部表示。
西方语言最常用的编码是UTF-8和UTF-16,这两种编码分别使用单字节和两字节值序列表示各个码点。对于其他语言,由于大多数字符都由超过两字节的码点表示,所以使用其他编码来存储可能更为高效。
要了解编码,最好的方法就是采用不同方法对相同的串进行编码,并查看所生成的不同的字节序列。下面的例子使用以下函数格式化字节串,使之更易读。
import binascii def to_hex(t, nbytes): """Format text t as a sequence of nbyte long values separated by spaces. """ chars_per_item = nbytes * 2 hex_version = binascii.hexlify(t) return b' '.join( hex_version[start:start + chars_per_item] for start in range(0, len(hex_version), chars_per_item) ) if __name__ == '__main__': print(to_hex(b'abcdef', 1)) print(to_hex(b'abcdef', 2))
这个函数使用binascii得到输入字节串的十六进制表示,在返回这个值之前每隔nbytes字节就插入一个空格。

第一个编码示例首先使用unicode类的原始表示来打印文本'francais',后面是Unicode数据库中各个字符的名。接下来两行将这个字符串分别编码为UTF-8和UTF-16,并显示编码得到的十六进制值。
import unicodedata import binascii def to_hex(t, nbytes): """Format text t as a sequence of nbyte long values separated by spaces. """ chars_per_item = nbytes * 2 hex_version = binascii.hexlify(t) return b' '.join( hex_version[start:start + chars_per_item] for start in range(0, len(hex_version), chars_per_item) ) text = 'français' print('Raw : {!r}'.format(text)) for c in text: print(' {!r}: {}'.format(c, unicodedata.name(c, c))) print('UTF-8 : {!r}'.format(to_hex(text.encode('utf-8'), 1))) print('UTF-16: {!r}'.format(to_hex(text.encode('utf-16'), 2)))
对一个str编码的结果是一个bytes对象。

给定一个编码字节序列(作为一个bytes实例),decode()方法将其转换为码点,并作为一个str实例返回这个序列。
import binascii def to_hex(t, nbytes): """Format text t as a sequence of nbyte long values separated by spaces. """ chars_per_item = nbytes * 2 hex_version = binascii.hexlify(t) return b' '.join( hex_version[start:start + chars_per_item] for start in range(0, len(hex_version), chars_per_item) ) text = 'français' encoded = text.encode('utf-8') decoded = encoded.decode('utf-8') print('Original :', repr(text)) print('Encoded :', to_hex(encoded, 1), type(encoded)) print('Decoded :', repr(decoded), type(decoded))
选择使用哪一种编码不会改变输出类型。

1.2 处理文件
处理I/O操作时,编码和解码字符串尤其重要。不论是写至一个文件、套接字还是其他流,数据都必须使用适当的编码。一般来讲,所有文本数据在读取时都需要由其字节表示解码,写数据时则需要从内部值编码为一种特定的表示。程序可以显式的编码和解码数据,不过取决于所用的编码,要想确定是否已经读取足够的字节来充分解码数据,这可能并不容易。codecs提供了一些类来管理数据编码和解码,所以应用不再需要做这个工作。
codecs提供的最简单的接口可以替代内置open()函数。这个新版本的函数与内置函数的做法很相似,不过增加了两个参数来指定编码和所需的错误处理技术。
import binascii import codecs def to_hex(t, nbytes): """Format text t as a sequence of nbyte long values separated by spaces. """ chars_per_item = nbytes * 2 hex_version = binascii.hexlify(t) return b' '.join( hex_version[start:start + chars_per_item] for start in range(0, len(hex_version), chars_per_item) ) encodings = ['utf-8','utf-16','utf-32'] for encoding in encodings: filename = encoding + '.txt' print('Writing to', filename) with codecs.open(filename, mode='w', encoding=encoding) as f: f.write('français') # Determine the byte grouping to use for to_hex() nbytes = { 'utf-8': 1, 'utf-16': 2, 'utf-32': 4, }.get(encoding, 1) # Show the raw bytes in the file print('File contents:') with open(filename, mode='rb') as f: print(to_hex(f.read(), nbytes))
这个例子首先处理一个包含ç的unicode串,使用指定的编码将这个文本保存到一个文件。

用open()读数据很简单,但有一点要注意:必须提前知道编码才能正确的建立解码器。尽管有些数据格式(如XML)会在文件中指定编码,但是通常都要由应用来管理。codecs只是取一个编码参数,并假设这个编码是正确的。
import binascii import codecs def to_hex(t, nbytes): """Format text t as a sequence of nbyte long values separated by spaces. """ chars_per_item = nbytes * 2 hex_version = binascii.hexlify(t) return b' '.join( hex_version[start:start + chars_per_item] for start in range(0, len(hex_version), chars_per_item) ) encodings = ['utf-8','utf-16','utf-32'] for encoding in encodings: filename = encoding + '.txt' print('Reading from', filename) with codecs.open(filename, mode='r', encoding=encoding) as f: print(repr(f.read()))
这个例子读取上一个程序创建的文件,并把得到的unicode对象的表示打印到控制台。

1.3 字节序
在不同的计算机系统之间传输数据时(可能直接复制一个文件,或者使用网络通信来完成传输),多字节编码(如UTF-16和UTF-32)会带来一个问题。不同系统中使用的高字节和低字节的顺序不同。数据的这个特性被称为字节序(endianness),这取决于硬件体系结构等因素,还取决于操作系统和应用开发人员做出的选择。通常没有办法提前知道给定的一组数据要使用哪一个字节序,所以多字节编码还包含一个字节序标志(Byte-Order Marker,BOM),这个标志出现在编码输出的前几个字节。例如,UTF-16定义0xFFFE和0xFEFF不是合法字符,可以用于指示字节序。codecs定义了UTF-16和UTF-32所用的字节序标志的相应常量。
import codecs import binascii def to_hex(t, nbytes): """Format text t as a sequence of nbyte long values separated by spaces. """ chars_per_item = nbytes * 2 hex_version = binascii.hexlify(t) return b' '.join( hex_version[start:start + chars_per_item] for start in range(0, len(hex_version), chars_per_item) ) BOM_TYPES = [ 'BOM', 'BOM_BE', 'BOM_LE', 'BOM_UTF8', 'BOM_UTF16', 'BOM_UTF16_BE', 'BOM_UTF16_LE', 'BOM_UTF32', 'BOM_UTF32_BE', 'BOM_UTF32_LE', ] for name in BOM_TYPES: print('{:12} : {}'.format( name, to_hex(getattr(codecs, name), 2)))
取决于当前系统的原生字节序,BOM、BOM_UTF16和BOM_UTF32会自动设置为适当的大端(big-endian)或小端(little-endian)值。

可以由codecs中的解码器自动检测和处理字节序,也可以在编码时显式的指定字节序。
import codecs import binascii def to_hex(t, nbytes): """Format text t as a sequence of nbyte long values separated by spaces. """ chars_per_item = nbytes * 2 hex_version = binascii.hexlify(t) return b' '.join( hex_version[start:start + chars_per_item] for start in range(0, len(hex_version), chars_per_item) ) # Pick the nonnative version of UTF-16 encoding if codecs.BOM_UTF16 == codecs.BOM_UTF16_BE: bom = codecs.BOM_UTF16_LE encoding = 'utf_16_le' else: bom = codecs.BOM_UTF16_BE encoding = 'utf_16_be' print('Native order :', to_hex(codecs.BOM_UTF16, 2)) print('Selected order:', to_hex(bom, 2)) # Encode the text. encoded_text = 'français'.encode(encoding) print('{:14}: {}'.format(encoding, to_hex(encoded_text, 2))) with open('nonnative-encoded.txt', mode='wb') as f: # Write the selected byte-order marker. It is not included # in the encoded text because the byte order was given # explicitly when selecting the encoding. f.write(bom) # Write the byte string for the encoded text. f.write(encoded_text)
首先得出原生字节序,然后显式的使用替代形式,以便下一个例子可以在展示读取时自动检测字节序。

程序打开文件时没有指定字节序,所以解码器会使用文件前两个字节中的BOM值来确定字节序。
import codecs import binascii def to_hex(t, nbytes): """Format text t as a sequence of nbyte long values separated by spaces. """ chars_per_item = nbytes * 2 hex_version = binascii.hexlify(t) return b' '.join( hex_version[start:start + chars_per_item] for start in range(0, len(hex_version), chars_per_item) ) # Look at the raw data with open('nonnative-encoded.txt', mode='rb') as f: raw_bytes = f.read() print('Raw :', to_hex(raw_bytes, 2)) # Re-open the file and let codecs detect the BOM with codecs.open('nonnative-encoded.txt', mode='r', encoding='utf-16', ) as f: decoded_text = f.read() print('Decoded:', repr(decoded_text))
由于文件的前两个字节用于字节序检测,所以它们并不包含在read()返回的数据中。

1.4 错误处理
前几节指出,读写Unicode文件时需要知道所使用的编码。正确的设置编码很重要,这有两个原因:首先,如果读文件时未能正确的配置编码,就无法正确的解释数据,数据有可能被破坏或无法解码,就会产生一个错误,可能丢失数据。
类似于str的encode()方法和bytes的decode()方法,codecs也使用了同样的5个错误处理选项。
| 错误模式 | 描述 |
|---|---|
strict |
如果无法转换数据,则会引发异常。 |
replace |
将特殊的标记字符替换为无法编码的数据。 |
ignore |
跳过数据。 |
xmlcharrefreplace |
XML字符(仅编码) |
backslashreplace |
转义序列(仅编码) |
1.4.1 编码错误
最常见的错误是在向一个ASCII输出流(如一个常规文件或sys.stdout)写Unicode数据时接收到一个UnicodeEncodeError。
import codecs error_handlings = ['strict','replace','ignore','xmlcharrefreplace','backslashreplace'] text = 'français' for error_handling in error_handlings: try: # Save the data, encoded as ASCII, using the error # handling mode specified on the command line. with codecs.open('encode_error.txt', 'w', encoding='ascii', errors=error_handling) as f: f.write(text) except UnicodeEncodeError as err: print('ERROR:', err) else: # If there was no error writing to the file, # show what it contains. with open('encode_error.txt', 'rb') as f: print('File contents: {!r}'.format(f.read()))
第一种选项,要确保应用显式的为所有I/O操作设置正确的编码,strict模式是最安全的选择,但是产生一个异常时,这种模式可能导致程序崩溃。
第二种选项,replace确保不会产生错误,其代价是一些无法转换为所需编码的数据可能会丢失。pi(π)的Unicode字符仍然无法用ASCII编码,但是采用这种错误处理模式时,并不是产生一个异常,而是会在输出中将这个字符替换为?。
第三种选项,无法编码的数据都会被丢弃。
第四种选项,会把字符替换为标准中定义的一个与该编码不同的候选表示。xmlcharrefreplace使用一个XML字符引用作为替代。
第五种选项,和第四种一样会把字符替换为标准中定义的一个与该编码不同的候选表示。它生成的输出格式类似于打印unicode对象的repr()时返回的值。Unicode字符会被替换为u以及码点的十六进制值。

1.4.2 编码错误
数据编码时也有可能遇到错误,特别是如果使用了错误的编码。
import codecs import binascii def to_hex(t, nbytes): """Format text t as a sequence of nbyte long values separated by spaces. """ chars_per_item = nbytes * 2 hex_version = binascii.hexlify(t) return b' '.join( hex_version[start:start + chars_per_item] for start in range(0, len(hex_version), chars_per_item) ) error_handlings = ['strict','ignore','replace'] text = 'français' for error_handling in error_handlings: print('Original :', repr(text)) # Save the data with one encoding with codecs.open('decode_error.txt', 'w', encoding='utf-16') as f: f.write(text) # Dump the bytes from the file with open('decode_error.txt', 'rb') as f: print('File contents:', to_hex(f.read(), 1)) # Try to read the data with the wrong encoding with codecs.open('decode_error.txt', 'r', encoding='utf-8', errors=error_handling) as f: try: data = f.read() except UnicodeDecodeError as err: print('ERROR:', err) else: print('Read :', repr(data))
与编码一样,如果不能正确的节码字节流,则strict错误处理模式会产生一个异常。在这里,产生UnicodeDecodeError的原因是尝试使用UTF-8解码器将UTF-16BOM部分转换为一个字符。
切换到ignore会让解码器跳过不合法的字节。不过,结果仍然不是原来指望的结果,因为其中包括嵌入的null字节。
采用replace模式时,非法的字节会被替换为uFFFD,这是官方的Unicode替换字符,看起来像是一个有黑色背景的菱形,其中包含一个白色的问号。

1.5 编码转换
尽管大多数应用都在内部处理str数据,将数据解码或编码作为I/O操作的一部分,但有些情况下,可能需要改变文件的编码而不继续坚持这种中间数据格式,这可能很有用。EncodedFile()取一个使用某种编码打开的文件句柄,用一个类包装这个文件句柄,有I/O操作时它会把数据转换为另一种编码。
import binascii import codecs import io def to_hex(t, nbytes): """Format text t as a sequence of nbyte long values separated by spaces. """ chars_per_item = nbytes * 2 hex_version = binascii.hexlify(t) return b' '.join( hex_version[start:start + chars_per_item] for start in range(0, len(hex_version), chars_per_item) ) # Raw version of the original data. data = 'français' # Manually encode it as UTF-8. utf8 = data.encode('utf-8') print('Start as UTF-8 :', to_hex(utf8, 1)) # Set up an output buffer, then wrap it as an EncodedFile. output = io.BytesIO() encoded_file = codecs.EncodedFile(output, data_encoding='utf-8', file_encoding='utf-16') encoded_file.write(utf8) # Fetch the buffer contents as a UTF-16 encoded byte string utf16 = output.getvalue() print('Encoded to UTF-16:', to_hex(utf16, 2)) # Set up another buffer with the UTF-16 data for reading, # and wrap it with another EncodedFile. buffer = io.BytesIO(utf16) encoded_file = codecs.EncodedFile(buffer, data_encoding='utf-8', file_encoding='utf-16') # Read the UTF-8 encoded version of the data. recoded = encoded_file.read() print('Back to UTF-8 :', to_hex(recoded, 1))
这个例子显示了如何读写EncodedFile()返回的不同句柄。不论这个句柄用于读还是写,file_encoding总是指示总是指示打开文件句柄所用的编码(作为第一个参数传入),data_encoding值则指示通过read()和write()调用传递数据时所用的编码。

1.6 非Unicode编码
尽管之前大多数例子都使用Unicode编码,但实际上codecs还可以用于很多其他数据转换。例如,Python包含了处理base-64、bzip2、ROT-13、ZIP和其他数据格式的codecs。
import codecs import io buffer = io.StringIO() stream = codecs.getwriter('rot_13')(buffer) text = 'abcdefghijklmnopqrstuvwxyz' stream.write(text) stream.flush() print('Original:', text) print('ROT-13 :', buffer.getvalue())
如果转换可以被表述为有单个输入参数的函数,并且返回一个字节或Unicode串,那么这样的转换都可以注册为一个codec。对于'rot_13'codec,输入应当是一个Unicode串;输出也是一个Unicode串。
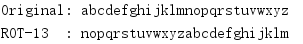
使用codecs包装一个数据流,可以提供比直接使用zlib更简单的接口。
import codecs import io buffer = io.BytesIO() stream = codecs.getwriter('zlib')(buffer) text = b'abcdefghijklmnopqrstuvwxyz ' * 50 stream.write(text) stream.flush() print('Original length :', len(text)) compressed_data = buffer.getvalue() print('ZIP compressed :', len(compressed_data)) buffer = io.BytesIO(compressed_data) stream = codecs.getreader('zlib')(buffer) first_line = stream.readline() print('Read first line :', repr(first_line)) uncompressed_data = first_line + stream.read() print('Uncompressed :', len(uncompressed_data)) print('Same :', text == uncompressed_data)
并不是所有压缩或编码系统都支持使用readline()或read()通过流接口读取数据的一部分,因为这需要找到压缩段的末尾来完成解压缩。如果一个程序无法在内存中保存整个解压缩的数据集,那么可以使用压缩库的增量访问特性,而不是codecs。

1.7 增量编码
目前提供的一些编码(特别是bz2和zlib)在处理数据流时可能会显著改变数据流的长度。对于大的数据集,这些编码采用增量方式可以更好的处理,即一次只处理一个小数据块。IncrementalEncoder/IncreamentalDecoder API就是为此而设计。
import codecs import sys text = b'abcdefghijklmnopqrstuvwxyz ' repetitions = 50 print('Text length :', len(text)) print('Repetitions :', repetitions) print('Expected len:', len(text) * repetitions) # Encode the text several times to build up a # large amount of data encoder = codecs.getincrementalencoder('bz2')() encoded = [] print() print('Encoding:', end=' ') last = repetitions - 1 for i in range(repetitions): en_c = encoder.encode(text, final=(i == last)) if en_c: print(' Encoded : {} bytes'.format(len(en_c))) encoded.append(en_c) else: sys.stdout.write('.') all_encoded = b''.join(encoded) print() print('Total encoded length:', len(all_encoded)) print() # Decode the byte string one byte at a time decoder = codecs.getincrementaldecoder('bz2')() decoded = [] print('Decoding:', end=' ') for i, b in enumerate(all_encoded): final = (i + 1) == len(text) c = decoder.decode(bytes([b]), final) if c: print(' Decoded : {} characters'.format(len(c))) print('Decoding:', end=' ') decoded.append(c) else: sys.stdout.write('.') print() restored = b''.join(decoded) print() print('Total uncompressed length:', len(restored))
每次将数据传递到编码器或解码器时,其内部状态都会更新。状态一致时(按照codec的定义),会返回数据并重置状态。在此之前,encode()或decode()调用并不返回任何数据。传入最后一位数据时,参数final应当设置为True,这样codec就能知道需要刷新输出所有余下的缓冲数据。

1.8 定义定制编码
由于Python已经提供了大量标准codecs,所以应用一般不太可能需要定义定制的编码器或解码器。不过,如果确实有必要,codecs中的很多基类可以帮助你更容易的定义定制编码。
第一步是了解编码描述的转换性质。这一节中的例子将使用一个“invertcaps”编码,它把大写字母转换为小写,把小写字母转换为大写。下面是一个编码函数的简单定义,它会对输入字符串完成这个转换。
import string def invertcaps(text): """Return new string with the case of all letters switched. """ return ''.join( c.upper() if c in string.ascii_lowercase else c.lower() if c in string.ascii_uppercase else c for c in text ) if __name__ == '__main__': print(invertcaps('ABCdef')) print(invertcaps('abcDEF'))
在这里,编码器和解码器都是同一个函数(与ROT-13类似)。

尽管很容易理解,但这个实现效率不高,特别是对于非常大的文本串。幸运的是,codecs包含一些辅助函数,可以创建基于字符映射(character map)的codecs,如invertcaps。字符映射编码由两个字典构成。编码映射(encoding map)将输入串的字符值转换为输出中的字节值,解码映射(decoding map)则相反。首先创建解码映射,然后使用make_encoding_map()把它转换为一个编码映射。C函数charmap_encode()和charmap_decode()可以使用这些映射高效的转换输入数据。
import codecs import string # Map every character to itself decoding_map = codecs.make_identity_dict(range(256)) # Make a list of pairs of ordinal values for the lower # and uppercase letters pairs = list(zip( [ord(c) for c in string.ascii_lowercase], [ord(c) for c in string.ascii_uppercase], )) # Modify the mapping to convert upper to lower and # lower to upper. decoding_map.update({ upper: lower for (lower, upper) in pairs }) decoding_map.update({ lower: upper for (lower, upper) in pairs }) # Create a separate encoding map. encoding_map = codecs.make_encoding_map(decoding_map) if __name__ == '__main__': print(codecs.charmap_encode('abcDEF', 'strict', encoding_map)) print(codecs.charmap_decode(b'abcDEF', 'strict', decoding_map)) print(encoding_map == decoding_map)
尽管invertcaps的编码和解码映射是一样的,但并不总是如此。有时会把对各输入字符编码为相同的输出字节,make_encoding_map()会检测这些情况,并把编码值替换为None,以标志编码为未定义。

字符映射编码器和解码器支持前面介绍的所有标准错误处理方法,所以不需要做任何额外的工作来支持这部分API。
import codecs import string # Map every character to itself decoding_map = codecs.make_identity_dict(range(256)) # Make a list of pairs of ordinal values for the lower # and uppercase letters pairs = list(zip( [ord(c) for c in string.ascii_lowercase], [ord(c) for c in string.ascii_uppercase], )) # Modify the mapping to convert upper to lower and # lower to upper. decoding_map.update({ upper: lower for (lower, upper) in pairs }) decoding_map.update({ lower: upper for (lower, upper) in pairs }) # Create a separate encoding map. encoding_map = codecs.make_encoding_map(decoding_map) text = 'pi: u03c0' for error in ['ignore', 'replace', 'strict']: try: encoded = codecs.charmap_encode( text, error, encoding_map) except UnicodeEncodeError as err: encoded = str(err) print('{:7}: {}'.format(error, encoded))
由于π的Unicode码点不再编码映射中,所以采用strict错误处理模式时会产生一个异常。

定义了编码和解码映射之后,还需要建立一些额外的类,另外要注册编码。register()向注册表增加一个搜索函数,使得当用户希望使用这种编码时,codecs能够找到它。这个搜索函数必须有一个字符串参数,其中包含编码名,如果它知道这个编码则返回一个CodecInfo对象,否则返回None。
import codecs def search1(encoding): print('search1: Searching for:', encoding) return None def search2(encoding): print('search2: Searching for:', encoding) return None codecs.register(search1) codecs.register(search2) utf8 = codecs.lookup('utf-8') print('UTF-8:', utf8) try: unknown = codecs.lookup('no-such-encoding') except LookupError as err: print('ERROR:', err)
可以注册多个搜索函数,每个搜索函数将依次调用,直到一个搜索函数返回一个CodecInfo,或者所有搜索函数都已经调用。codecs注册的内部搜索函数知道如何加装标准codecs,如encodings的UTF-8,所以这些编码名不会传递到定制搜索函数。

搜索函数返回的CodecInfo实例告诉codecs如何使用所支持的各种不同机制来完成编码和解码,包括:无状态编码、增量式编码和流编码。codecs包括一些基类来帮助建立字符映射编码。下面这个例子集成了所有内容,它会注册一个搜索函数,并返回为invertcaps codec配置的一个CodecInfo实例。
import codecs import string # Map every character to itself decoding_map = codecs.make_identity_dict(range(256)) # Make a list of pairs of ordinal values for the lower # and uppercase letters pairs = list(zip( [ord(c) for c in string.ascii_lowercase], [ord(c) for c in string.ascii_uppercase], )) # Modify the mapping to convert upper to lower and # lower to upper. decoding_map.update({ upper: lower for (lower, upper) in pairs }) decoding_map.update({ lower: upper for (lower, upper) in pairs }) # Create a separate encoding map. encoding_map = codecs.make_encoding_map(decoding_map) class InvertCapsCodec(codecs.Codec): "Stateless encoder/decoder" def encode(self, input, errors='strict'): return codecs.charmap_encode(input, errors, encoding_map) def decode(self, input, errors='strict'): return codecs.charmap_decode(input, errors, decoding_map) class InvertCapsIncrementalEncoder(codecs.IncrementalEncoder): def encode(self, input, final=False): data, nbytes = codecs.charmap_encode(input, self.errors, encoding_map) return data class InvertCapsIncrementalDecoder(codecs.IncrementalDecoder): def decode(self, input, final=False): data, nbytes = codecs.charmap_decode(input, self.errors, decoding_map) return data class InvertCapsStreamReader(InvertCapsCodec, codecs.StreamReader): pass class InvertCapsStreamWriter(InvertCapsCodec, codecs.StreamWriter): pass def find_invertcaps(encoding): """Return the codec for 'invertcaps'. """ if encoding == 'invertcaps': return codecs.CodecInfo( name='invertcaps', encode=InvertCapsCodec().encode, decode=InvertCapsCodec().decode, incrementalencoder=InvertCapsIncrementalEncoder, incrementaldecoder=InvertCapsIncrementalDecoder, streamreader=InvertCapsStreamReader, streamwriter=InvertCapsStreamWriter, ) return None codecs.register(find_invertcaps) if __name__ == '__main__': # Stateless encoder/decoder encoder = codecs.getencoder('invertcaps') text = 'abcDEF' encoded_text, consumed = encoder(text) print('Encoded "{}" to "{}", consuming {} characters'.format( text, encoded_text, consumed)) # Stream writer import io buffer = io.BytesIO() writer = codecs.getwriter('invertcaps')(buffer) print('StreamWriter for io buffer: ') print(' writing "abcDEF"') writer.write('abcDEF') print(' buffer contents: ', buffer.getvalue()) # Incremental decoder decoder_factory = codecs.getincrementaldecoder('invertcaps') decoder = decoder_factory() decoded_text_parts = [] for c in encoded_text: decoded_text_parts.append( decoder.decode(bytes([c]), final=False) ) decoded_text_parts.append(decoder.decode(b'', final=True)) decoded_text = ''.join(decoded_text_parts) print('IncrementalDecoder converted {!r} to {!r}'.format( encoded_text, decoded_text))
无状态编码器/解码器的基类是Codec,要用新实现来覆盖encode()和decode()(在这里分别调用了charmap_encode()和charmap_decode())。这些方法必须分别返回一个元组,其中包含转换的数据和已消费的输入字节或字符数。charmap_encode()和charmap_decode()已经返回了这个消息,所以很方便。
IncrementalEncoder和incrementalDecoder可以作为增量式编码接口的基类。增量来的encode()和decode()方法被定义为只返回真正的转换数据。缓冲的有关消息都作为内部状态来维护。invertcaps编码不需要缓冲数据(它使用一种一对一映射)。如果编码根据所处理的数据会生成不同数量的输出,如压缩算法,那么对于这些编码,BufferedIncrementalEncoder和BufferedIncrementalDecoder将是更合适的基类,因为它们可以管理输入中未处理的部分。
StreamReader和StreamWriter也需要encode()和decode()方法,而且因为它们往往返回与Codec中相应方法同样的值,所以实现时可以使用多重继承。
