霍夫曼编码(Huffman Coding)是一种编码方法,霍夫曼编码是可变字长编码(VLC)的一种。
霍夫曼编码使用变长编码表对源符号(如文件中的一个字母)进行编码,其中变长编码表是通过一种评估来源符号出现机率的方法得到的,出现机率高的字母使用较短的编码,反之出现机率低的则使用较长的编码,这便使编码之后的字符串的平均长度、期望值降低,从而达到无损压缩数据的目的。
霍夫曼编码的具体步骤如下:
1)将信源符号的概率按减小的顺序排队。
2)把两个最小的概率相加,并继续这一步骤,始终将较高的概率分支放在右边,直到最后变成概率1。
3)画出由概率1处到每个信源符号的路径,顺序记下沿路径的0和1,所得就是该符号的霍夫曼码字。
4)将每对组合的左边一个指定为0,右边一个指定为1(或相反)。
例:现有一个由5个不同符号组成的30个符号的字符串:
BABACAC ADADABB CBABEBE DDABEEEBB
1首先计算出每个字符出现的次数(概率):
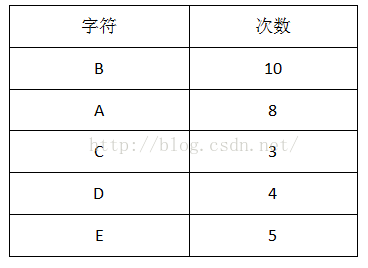
2把出现次数(概率)最小的两个相加,并作为左右子树,重复此过程,直到概率值为1

第一次:将概率最低值3和4相加,组合成7:
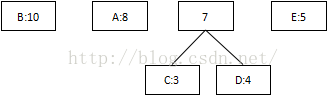
第二次:将最低值5和7相加,组合成12:

第三次:将8和10相加,组合成18:
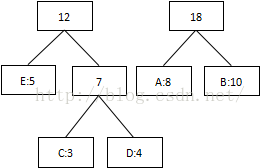
第四次:将最低值12和18相加,结束组合:
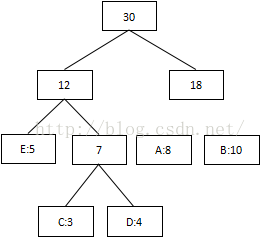
3 将每个二叉树的左边指定为0,右边指定为1

4 沿二叉树顶部到每个字符路径,获得每个符号的编码
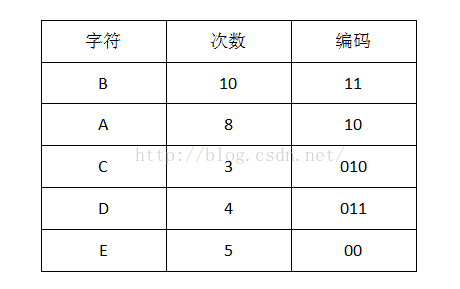
我们可以看到出现次数(概率)越多的会越在上层,编码也越短,出现频率越少的就越在下层,编码也越长。当我们编码的时候,我们是按“bit”来编码的,解码也是通过bit来完成,如果我们有这样的bitset “10111101100″ 那么其解码后就是 “ABBDE”。所以,我们需要通过这个二叉树建立我们Huffman编码和解码的字典表。
参考文献:https://blog.csdn.net/xgf415/article/details/52628073