介绍
当你有面对一大堆特征手无足措的时候,这时候你应该先考虑生成一个特征效用度量:
特征效用度量又叫互信息,互信息与相关系数类似,都是衡量两个数值的关系的,但区别是相关系数只能检测线性关系,而互信息可以检测任何一种关系。
用法:
当互信息等于0时,数值之间是没有关系的。不设上限,然而大于2.0的互信息一般不是很常见。
注意点:
mi(互信息)能帮助你找到对target(结果)具有潜在关系的特征。
mi无法找到两个特征之间的影响程度,原因是他是单变量度量。
即便特征mi很高,但也有可能对模型一点作用没有,因为模型学习的是跟结果有关的特征的关系。因此如果模型并未学到有关该特征的规律,再高的mi也没有用。
例子:
autos.csv:一个包含23个特征(make, body_style, and horsepower)的数据集
使用scikit-learn工具包:
由于scikit-learn对连续数据和离散数据做mi的方法是不同的,所以要把离散数据映射成一组数字:
for colname in X.select_dtypes("object"): X[colname], _ = X[colname].factorize()
在scikit-learn中有两套mi计算方法,一种是针对结果是实数的(mutual_info_regression),一种是针对结果是categorical targets 的(mutual_info_classif):
from sklearn.feature_selection import mutual_info_regression def make_mi_scores(X, y, discrete_features): mi_scores = mutual_info_regression(X, y, discrete_features=discrete_features) mi_scores = pd.Series(mi_scores, name="MI Scores", index=X.columns) mi_scores = mi_scores.sort_values(ascending=False) return mi_scores mi_scores = make_mi_scores(X, y, discrete_features)
结果:
curb_weight 1.526026
highway_mpg 0.958583
length 0.615287
bore 0.496247
为了看的更清楚一些,我们可以使用BAR图:
def plot_mi_scores(scores): scores = scores.sort_values(ascending=True) width = np.arange(len(scores)) ticks = list(scores.index) plt.barh(width, scores) plt.yticks(width, ticks) plt.title("Mutual Information Scores") plt.figure(dpi=100, figsize=(8, 5)) plot_mi_scores(mi_scores)
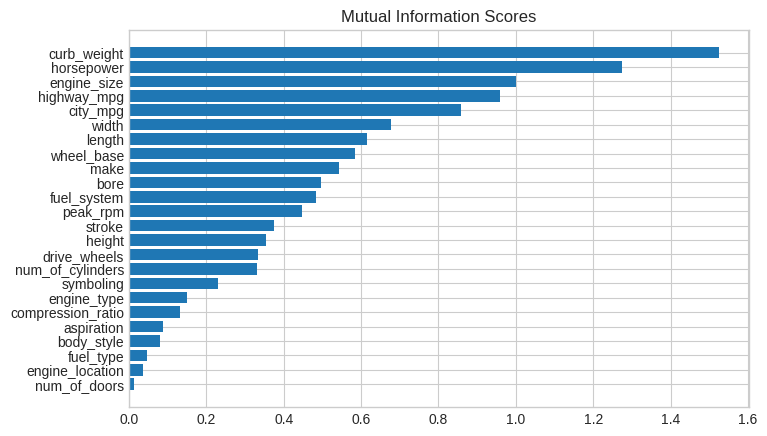
我们发现curb_weight的Mi Scores很高,因此,我们对curb_weight和price做图:
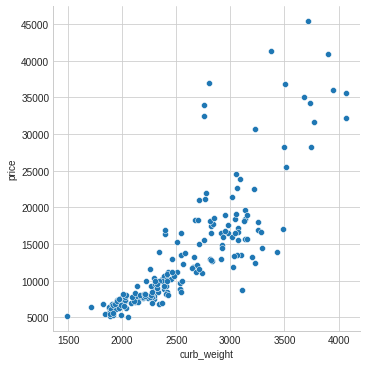
作图代码:
sns.relplot(x="curb_weight", y="price", data=df);
fuel_type的Mi Score很低,但通过做交互效应图后,发现fuel_type还是要保留的。
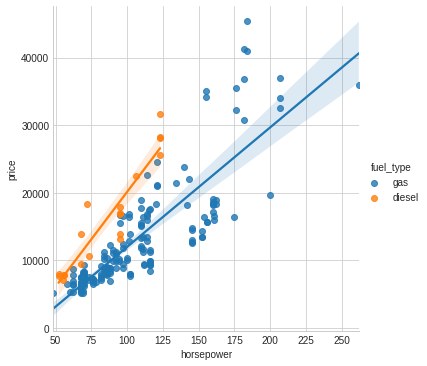
作图代码:
sns.lmplot(x="horsepower", y="price", hue="fuel_type", data=df);