Keras为方便用户使用数据集,提供了一个函数keras.dateset.调用这个函数方便的使用数据集。
但不幸的是,数据源的网址被墙了,但我找到了MNIST数据集。
详细网址见:
常用的数据集有MNIST,CIFAR10/100
MNIST
共有10个数字,每个图片像素是28*28,由于是灰度的图片,通道是1。
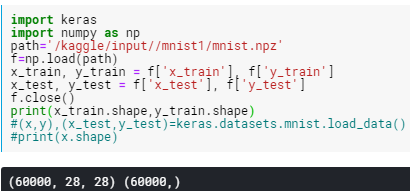
第一个元组代表一共有60k的图片,每个图片像素28*28
第二个元组代表这些图片分别编了9个码。
每个图片由numpy数组存储,每个像素点在0-255分布

把原本范围为1-9的y转成one_hot编码。
CIFAR10/100
参考代码:
https://blog.csdn.net/zxpcz/article/details/102690823?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522160510724919724836734903%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=160510724919724836734903&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~baidu_landing_v2~default-1-102690823.pc_first_rank_v2_rank_v28&utm_term=%E5%8A%A0%E8%BD%BDcifar&spm=1018.2118.3001.4449
这个数据集中,有10种图片,比如,猫,狗,每种图片有又有10个图片,所以叫CIFAR100
tf.data.DataSet
from_tensor_slices()
db=tf.data.Dataset.from_tensor_slices(x_test)
next(iter(db)).shape
from_tensor_slices()可以方便的将numpy类型转成tensor类型
shuffle
打散功能,为了防止机器学到一些奇奇怪怪的规律。
batch
读取数据一般是分批读取。
例子:
def prepare_mnist_features_and_labels(x,y): x=tf.cast(x,tf.float32)/255.0#将tensor x 转成0~1 y=tf.cast(y,int64) return x,y def mnist_dataset(): (x,y),(x_val,y_val) = datasets.fashion_mnist.load_data() y = tf.one_hot(y,depth=10) #将结果转成0~9 y_val=tf.one_hot(y,val,depth=10) ds = tf.data.Dataset.from_tensor_slices((x,y)) ds=ds.map(prepare_mnist_features_and_labels) ds=ds.shuffle(60000).batch(100) ds_val = tf.data.Dataset.from_tensor_slices((x_val,y_val)) ds_val=ds_val.map(prepare_mnist_features_and_labels) ds_val=ds_val.shuffle(60000).batch(100) return ds,ds_val