Lambda架构
https://blog.csdn.net/rav009/article/details/85690985
从业务角度,数据的应用有实效性,常见电子商务。有的数据的应用对实效性要求比较低。比如客户画像分析。
所以lambda架构分为两种解决方法。
第一种是speed layer (快速的处理实时数据以供查询)。(Redis,Storm,Kafka,Spark Streaming)
第二种(Batch Layer&&Serving Layer)(处理时效性要求不高的应用)。(MR或Spark,Hive)
Lambda复杂性:
1:同步
2:错误难以判断
kudu架构
使用案例
案例一:移动服务监听与跟踪
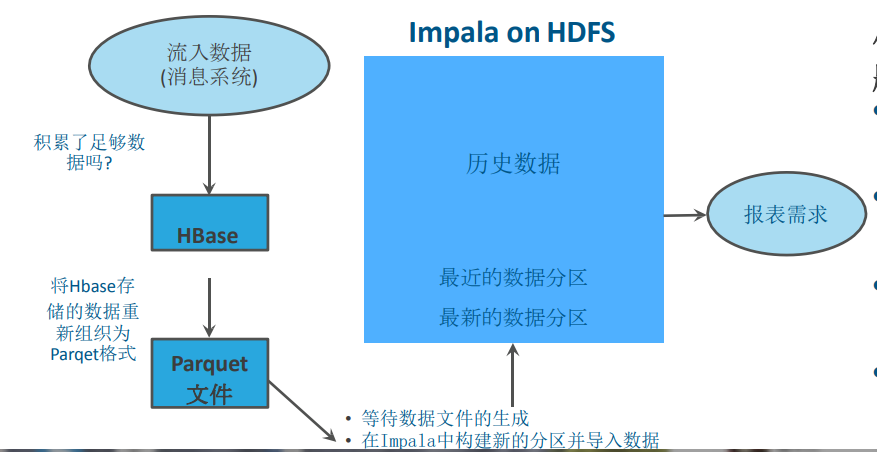
没有Kudu前
大数据pipeline:1.数据源-》2.HDFS-》3.MR/Hive/Spark-》HDFS Parquet-》Impala-》result
存在的问题:
1从生成到被高效查询的列存储,整个数据流延迟较大,一般是小时级别到一天
2数据日志到达时间和逻辑时间不一致。
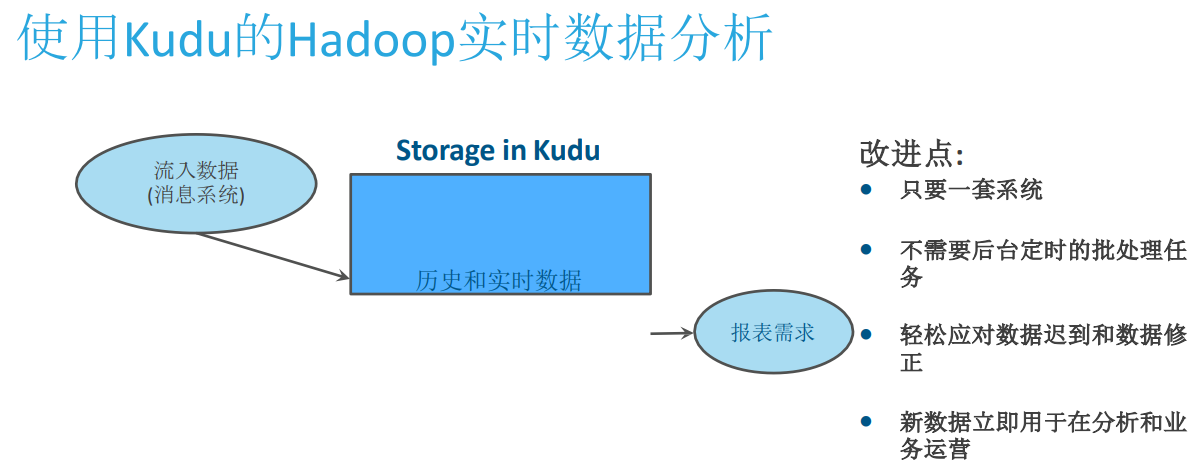
使用Kudu后
1.数据源-》kalfka-》ETL-》Kudu-》Impala
2.数据源-》Kudu-》Impala
案例二:京东案例分析
