Apache的Hadoop是可靠的、可扩展的开发开源软件,分布式计算。
Apache Hadoop软件库是一个框架,允许使用简单的编程模型在计算机集群中对大型数据集进行分布式处理。它被设计成从单个服务器扩展到数千台机器,每个机器都提供本地计算和存储。而不是依靠硬件来提供高可用性,库本身的目的是检测和处理应用层的故障,因此在一组计算机上提供高可用性服务,每一台计算机都容易出现故障。
该项目包括这些模块:
Hadoop通用:支持其他Hadoop模块的通用实用程序。
Hadoop分布式文件系统(HDFS):分布式文件系统,提供了高吞吐量的访问应用程序数据。
Hadoop YARN:作业调度和集群资源管理的框架。
Hadoop MapReduce:基于MapReduce的大数据集并行处理系统。
准备工作
首先我们准备一台云服务器 内存1G 操作系统 centos7
软件有
hadoop-2.6.0-cdh5.7.0(推荐使用,目前生产环境中占比最高的)
jdk-7u67-linux-x64.tar.gz
查看主机名
[root@VM_57_70_centos ~]# vim /etc/hosts
修改文件为一下内容:

然后输入reboot重启机器。
二、配置ssh免密码登录
接着输入:
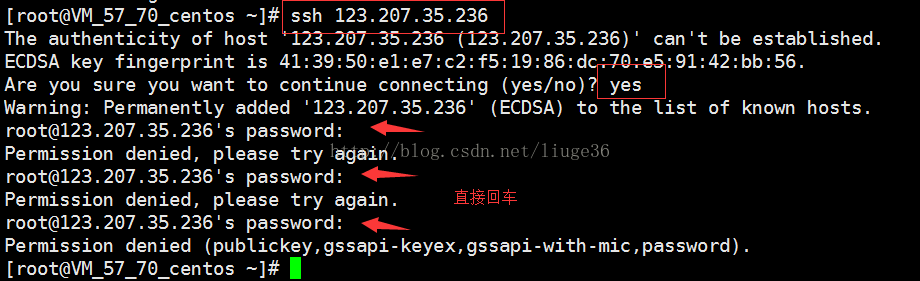
[root@VM_57_70_centos ~]# ssh-keygen -t rsa

复制密钥:

直接登录:

这样,我们登录到本机就不用输密码了
因为hadoop是java写的,所以在这里要配置JAVA的环境变量,
先创建几个目录,用来存放后面的文件
ps:(使用规范的操作,这样我们的软件才不会更加乱,以后维护起来也是会更加的容易)
直接上代码:
[root@VM_57_70_centos ~]# cd /home/
[root@VM_57_70_centos home]# ls
[root@VM_57_70_centos home]# mkdirsoftwares
[root@VM_57_70_centos home]# mkdir tools
[root@VM_57_70_centos home]# mkdir datas
[root@VM_57_70_centos home]# cd tools
看一下系统是否安装了java
[root@VM_57_70_centos tools]# rpm -qa |grep jdk
[root@VM_57_70_centos tools]# rpm -qa |grep java
输入这两句啥都没有说明系统没有安装jdk,开始安装jdk,
三、安装JDK
Tips:1.这里我们可以安装vsftpd服务来上传文件
[root@VM_57_70_centos ~]# yum -y install vsftpd
结果:
Installed:
vsftpd.x86_64 0:3.0.2-22.el7
Complete!
[root@VM_57_70_centos ~]#
简单修改配置文件:
[root@VM_57_70_centos ~]# vim/etc/vsftpd/vsftpd.conf
设置为禁止匿名登录:
anonymous_enable=NO
保存退出
创建用户:
[root@VM_57_70_centos ~]# useradd csy -d/tmp/ftp
[root@VM_57_70_centos ~]# passwd csy
Changing password for user csy.
New password:
BAD PASSWORD: The password is shorter than8 characters
Retype new password:
passwd: all authentication tokens updatedsuccessfully.
[root@VM_57_70_centos ~]#
这样我们就可以把本地的文件通过ftp传到服务器上了,很简单是吧!!哈哈!!!
Tips:2.
在线下载:
hadoop-2.6.0-cdh5.7.0.tar.gz:
Wget http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.7.0.tar.gz
这样的方式也是比较快的
Jdk.7:
http://www.oracle.com/technetwork/java/javase/downloads/java-archive-downloads-javase7-521261.html
(这里为了使用上一步,我们安装的vsftpd服务,我们可以下载到本地,使用ftp上传上去)
下载完成之后,放在/home/tools下
效果图:

之后我们解压在/home/sodtwares/目录下
[root@VM_57_70_centos tools]# tar -zxvfhadoop-2.6.0-cdh5.7.0.tar.gz -C ../softwares/
[root@VM_57_70_centos tools]# tar -zxvfjdk-7u80-linux-x64.tar.gz -C ../softwares/

接下来开始环境变量的配置:
[root@VM_57_70_centos ~]#
[root@VM_57_70_centos ~]# vim /etc/profile
#添加上:
export JAVA_HOME=/home/softwares/jdk1.7.0_80
export PATH=$JAVA_HOME/bin:$PATH
保存退出
让我们的配置生效
[root@VM_57_70_centos ~]# source/etc/profile
测试环境变量,

到这里,说明你的java环境配置成功
然后,开始配置hadoop:
继续修改/etc/profile文件:
[root@VM_57_70_centos ~]# vim /etc/profile
添加:
exportHADOOP_HOME=/home/softwares/hadoop-2.6.0-cdh5.7.0
export PATH=$HADOOP_HOME/bin:$PATH
保存退出
测试环境变量,
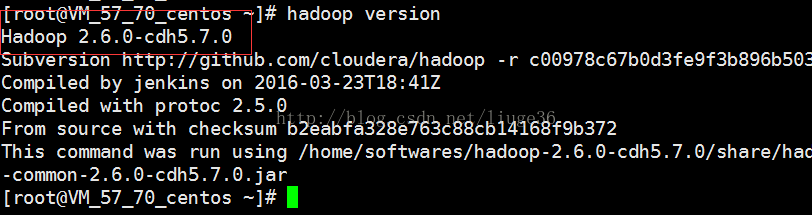
hadoop目录,来对其进行配置hadoop-env.sh,主要是配置java的环境变量
[root@VM_57_70_centos ~]#
[root@VM_57_70_centos ~]# cd/home/softwares/hadoop-2.6.0-cdh5.7.0/
[root@VM_57_70_centoshadoop-2.6.0-cdh5.7.0]# cd etc/hadoop
[root@VM_57_70_centos hadoop]# vim hadoop-env.sh
更改:
exportJAVA_HOME=/home/softwares/jdk1.7.0_80
(即:JAVA_HOME=${JAVA_HOME}为exportJAVA_HOME=/home/softwares/jdk1.7.0_67)
保存退出
回到hadoop主目录然后创建data目录,来存放我们hadoop的缓存目录。
[root@VM_57_70_centoshadoop-2.6.0-cdh5.7.0]# mkdir data
[root@VM_57_70_centoshadoop-2.6.0-cdh5.7.0]# cd data
[root@VM_57_70_centos data]# mkdir tmp
回到hadoop主目录,
[root@VM_57_70_centoshadoop-2.6.0-cdh5.7.0]# cd etc/hadoop
[root@VM_57_70_centos hadoop]# vim co
configuration.xsl container-executor.cfg core-site.xml
[root@VM_57_70_centos hadoop]# vimcore-site.xml

说明:hadoop.tmp.dir: //Hadoop的默认临时路径,这个最好配置,然后在新增节点或者其他情况下莫名其妙的DataNode启动不了,就删除此文件中的tmp目录即可。
不过如果删除了NameNode机器的此目录,那么就需要重新执行NameNode格式化的命令了。
[root@VM_57_70_centos hadoop]# vim hdfs-site.xml

说明:hadoop默认是数量3,由于我们是伪分布式,所以设置为1
然后开始格式化文件系统
[root@VM_57_70_centosbin]# hadoop namenode –format
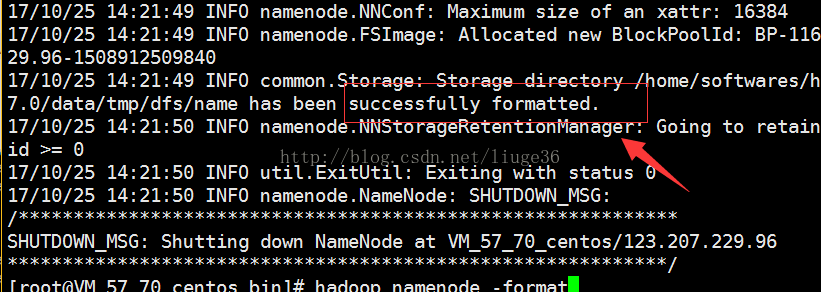
看到successfullyformatted说明格式化成功
然后启动我们的进程
遇到选项就输入yes
[root@VM_57_70_centos hadoop-2.6.0-cdh5.7.0]#cd sbin/
[root@VM_57_70_centos sbin]#
[root@VM_57_70_centos sbin]# ./start-dfs.sh
查看进程jps
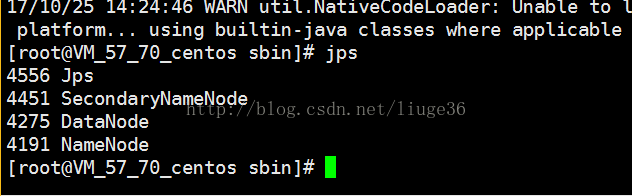
出现上面的说明启动成功。
补充:如果出现错误:可以观察输出的日志信息:

在浏览器输入
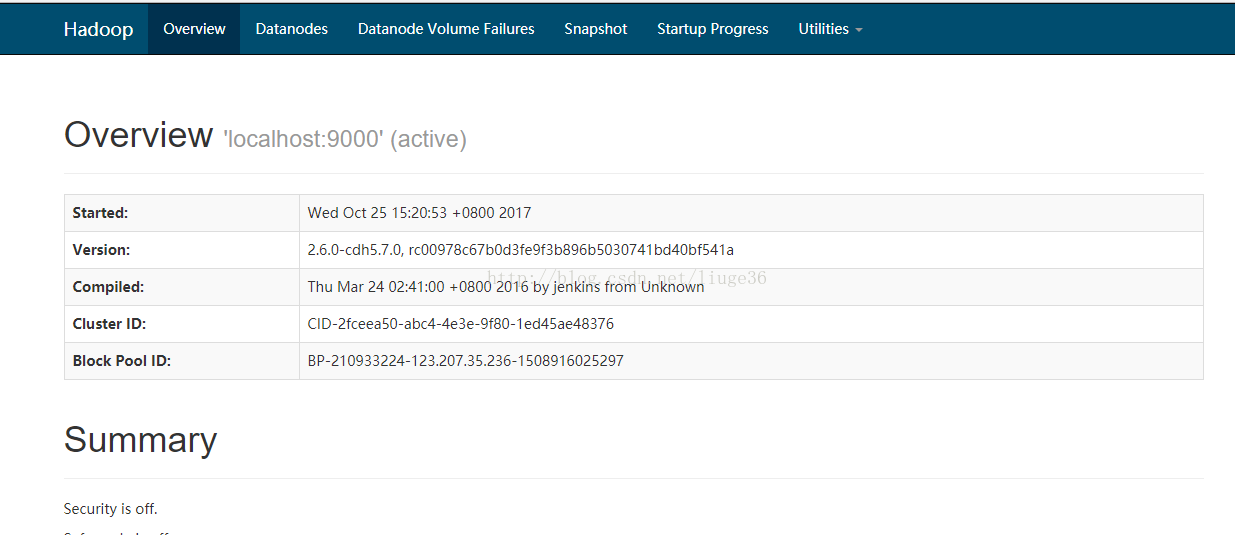
安装yarn,hadoop中的资源调度。
然后修改hadoop目录下:
mapred-site.xml.template(主要是让咋们的mapreduce服从yarn的调度)
[root@VM_57_70_centos hadoop]# vim mapred-site.xml
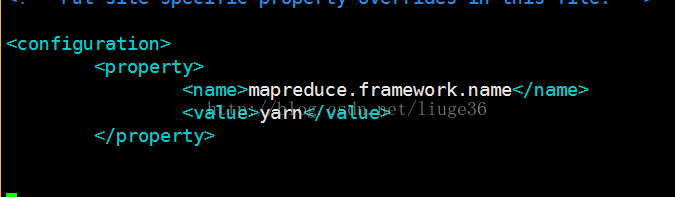
配置yarn-site.xml(配置mapreduce去数据的方式)
[root@VM_57_70_centos hadoop]#
vim yarn-site.xml
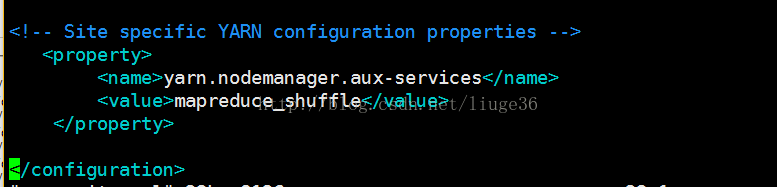
[root@VM_57_70_centos sbin]# ./start-yarn.sh
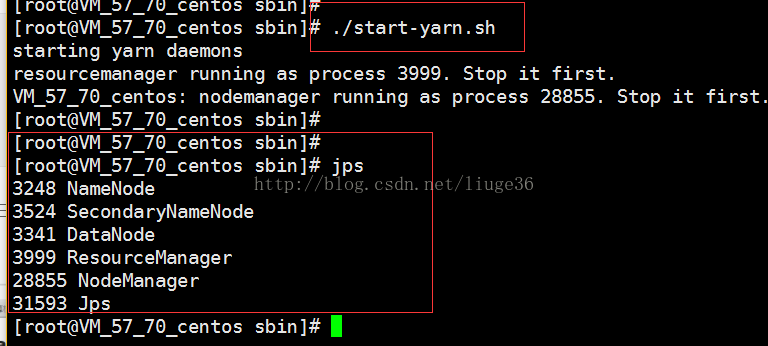
五个进程都启动成功,说明咋们的配置正确,
启动中有什么错误请查看日志文件。
在浏览器输入
到这里,你已经完成了,伪分布式的搭建。祝你学习愉快!!
更多精彩,,待续。。。