今天晚上整理了两道比较简单关于搜索引擎的题目,所有题均是Iveely搜索引擎中遇到的,与大家分享你的智慧吧!都不难,但是希望能够找到一种最佳的解决办法。
问题一:
背景介绍:
问题二:
背景介绍:
搜索引擎中,每一个关键字都对应了无数张网页,每一张网页都对应着若干的关键字,搜索引擎在获取到关键字后,一定要在尽可能快的时间内获取出拥有该 关键字的网页集合,目前最常用的做法是倒排序,然而倒排序文件中,虽然能够很快的提取出网页的关键字,但是网页的权重却不定相同。也就是到排文件的结构是无序的。
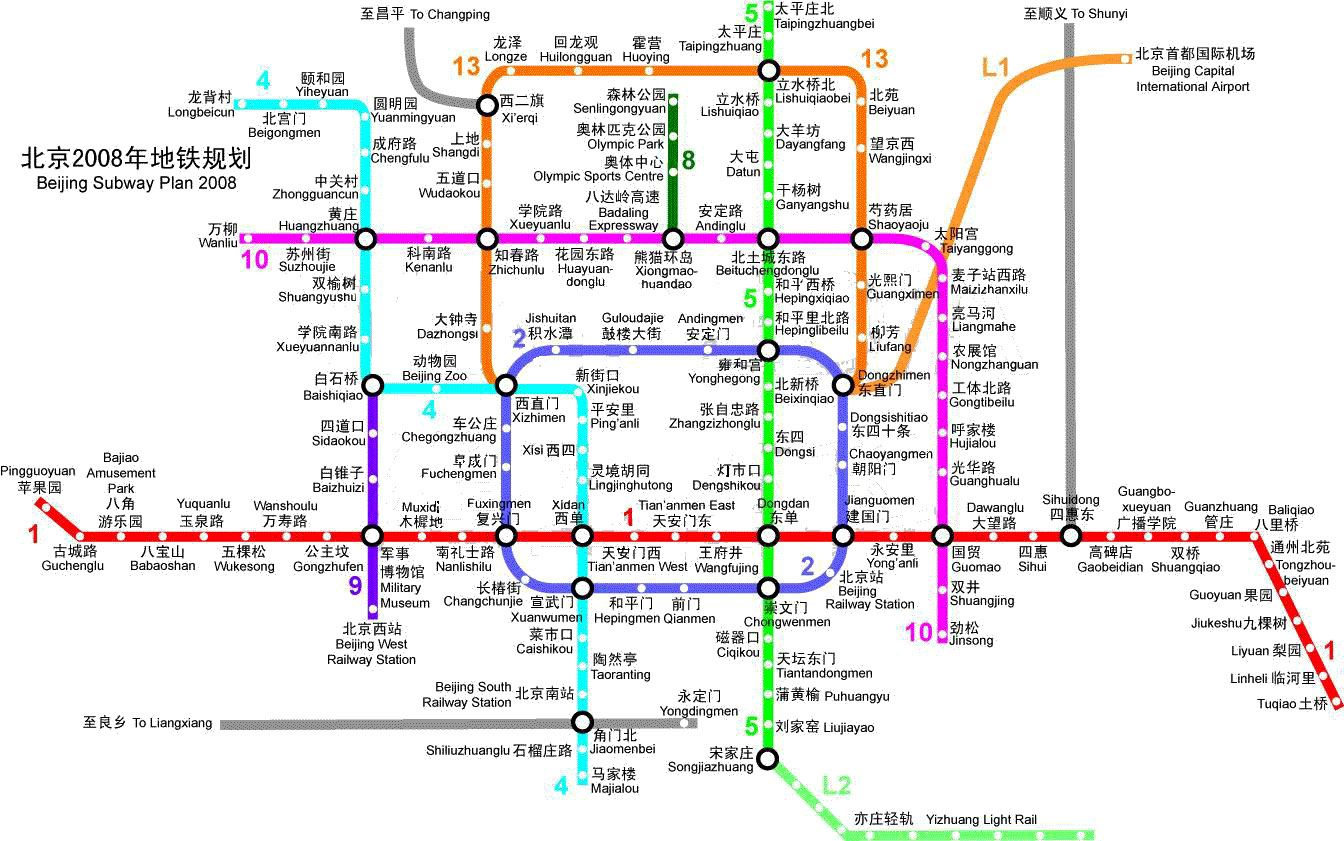
下面我们把问题抽象为北京地铁站信息,每一个站点都是关键字,每一条线路都是网页。每一个站点被多条线路包含(每一个关键字被若干网页包含),每一 条线路包含多个站点(每一张网页包含多个关键字)。
问题的产生:
倒排文件已经让我们可以很快的提取出站点对应的线路,但是遗憾的是,例如:用户搜索西直门,那么将返回地铁2号线,地铁4号线以及地铁13号线。然而,地铁4号线和地铁2号线又有另外一个交集站点:宣武门。我们为什么需要知道宣武门呢?因为在Iveely的设计当中,认为:当搜索结果中的交集 站点越集中,当达到一个程度时,这个站点也可能是用户比较感兴趣的站点(数学证明:略),例如上图中,若用户换乘地铁时,可能是想在西直门换乘地铁,如果结果中的地铁线路集合中包含宣武门的也很多,那么我们假设宣武门也可以是一个很好的换乘地铁方案。
需要解决的问题:
请设计一种数据结构,在尽可能廉价的时间复杂度和空间复杂度下,计算出,搜索结果中包含相同站点的排序集合(按照出现的结果中包含的次数)。最简单的例如:输入西直门,可以返回推荐宣武门,如果还有包含的站点依次按照出现次数列出。
以上题目是我自己拟出来的,是我在开源Iveely过程中遇到的问题,我想这是比较有意义的题目,因为不仅仅是我们的思维,还有我们code技术,当然最重要的是我们的数学,陆续我也会将其它类似的问题发出来,让大家一起探讨,学习,欢迎您对Iveely搜索引擎的关注,如果您有什么好的意见或建议,可以邮件liufanping@iveely.com 或微薄联系我。