引言
前面已经对市场上一些比较热门的性能测试工具进行了对比,这里主要介绍Locust性能测试框架的使用,如果你喜欢编码,学习Python自动化测试的时候,同时又能学习一款性能测试工具,何乐而不为呢。
https://github.com/locustio/locust 13000+星
简介
Locust是易于使用的分布式用户负载测试工具。它旨在对网站(或其他系统)进行负载测试,并确定系统可以处理多少个并发用户。
这个想法是,在测试期间,大量的模拟用户会攻击您的网站。您可以使用Python代码定义每个用户的行为,并且可以通过Web UI实时监视群集过程。这将帮助您在允许真正的用户进入之前测试测试并确定代码中的瓶颈。
Locust完全基于事件,因此可以在一台计算机上支持数千个并发用户。与许多其他基于事件的应用程序相比,它不使用回调。相反,它通过gevent使用轻量级进程。群集您站点的每个蝗虫实际上都在其自己的进程中运行(正确地说,是Greenlet)。
这使您可以在Python中编写非常有表现力的场景,而不会使回调复杂化代码。————官方文档:https://locust.io
简单来说:
1、支持分布式;
2、纯python脚本,易上手;
3、扩展性高;
4、单机支持高并发数;
5、WebUI可视化监控;
...
环境配置
python 3.6.5 pip3 IDE:Pycharm2019.3
安装locustio
pip install locustio
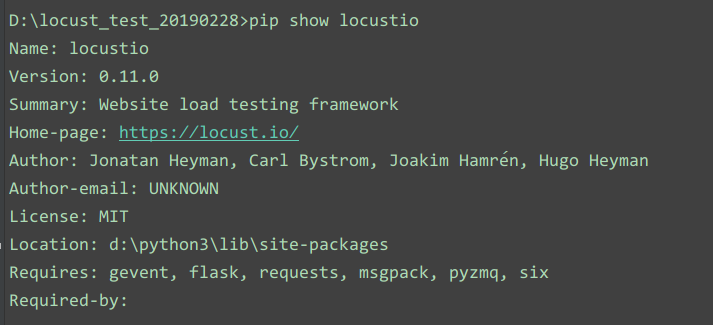
查看是否安装成功:

翻译:
-h, --help 查看帮助 -H HOST, --host=HOST 指定被测试的主机,采用以格式:http://10.21.32.33 --web-host=WEB_HOST 指定运行 Locust Web 页面的主机,默认为空 ''。 -P PORT, --port=PORT, --web-port=PORT 指定 --web-host 的端口,默认是8089 -f LOCUSTFILE, --locustfile=LOCUSTFILE 指定运行 Locust 性能测试文件,默认为: locustfile.py --csv=CSVFILEBASE, --csv-base-name=CSVFILEBASE 以CSV格式存储当前请求测试数据。 --master Locust 分布式模式使用,当前节点为 master 节点。 --slave Locust 分布式模式使用,当前节点为 slave 节点。 --master-host=MASTER_HOST 分布式模式运行,设置 master 节点的主机或 IP 地址,只在与 --slave 节点一起运行时使用,默认为:127.0.0.1. --master-port=MASTER_PORT 分布式模式运行, 设置 master 节点的端口号,只在与 --slave 节点一起运行时使用,默认为:5557。注意,slave 节点也将连接到这个端口+1 上的 master 节点。 --master-bind-host=MASTER_BIND_HOST Interfaces (hostname, ip) that locust master should bind to. Only used when running with --master. Defaults to * (all available interfaces). --master-bind-port=MASTER_BIND_PORT Port that locust master should bind to. Only used when running with --master. Defaults to 5557. Note that Locust will also use this port + 1, so by default the master node will bind to 5557 and 5558. --expect-slaves=EXPECT_SLAVES How many slaves master should expect to connect before starting the test (only when --no-web used). --no-web no-web 模式运行测试,需要 -c 和 -r 配合使用. -c NUM_CLIENTS, --clients=NUM_CLIENTS 指定并发用户数,作用于 --no-web 模式。 -r HATCH_RATE, --hatch-rate=HATCH_RATE 指定每秒启动的用户数,作用于 --no-web 模式。 -t RUN_TIME, --run-time=RUN_TIME 设置运行时间, 例如: (300s, 20m, 3h, 1h30m). 作用于 --no-web 模式。 -L LOGLEVEL, --loglevel=LOGLEVEL 选择 log 级别(DEBUG/INFO/WARNING/ERROR/CRITICAL). 默认是 INFO. --logfile=LOGFILE 日志文件路径。如果没有设置,日志将去 stdout/stderr --print-stats 在控制台中打印数据 --only-summary 只打印摘要统计 --no-reset-stats Do not reset statistics once hatching has been completed。 -l, --list 显示测试类, 配置 -f 参数使用 --show-task-ratio 打印 locust 测试类的任务执行比例,配合 -f 参数使用. --show-task-ratio-json 以 json 格式打印 locust 测试类的任务执行比例,配合 -f 参数使用. -V, --version 查看当前 Locust 工具的版本.
如果指定最新版本可以这样操作:
pip3 install -i https://pypi.douban.com/simple/ locustio==0.14.6
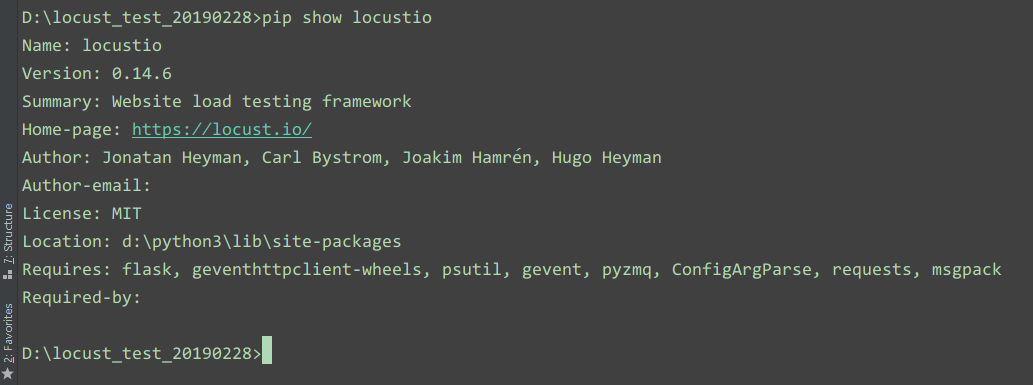
版本信息

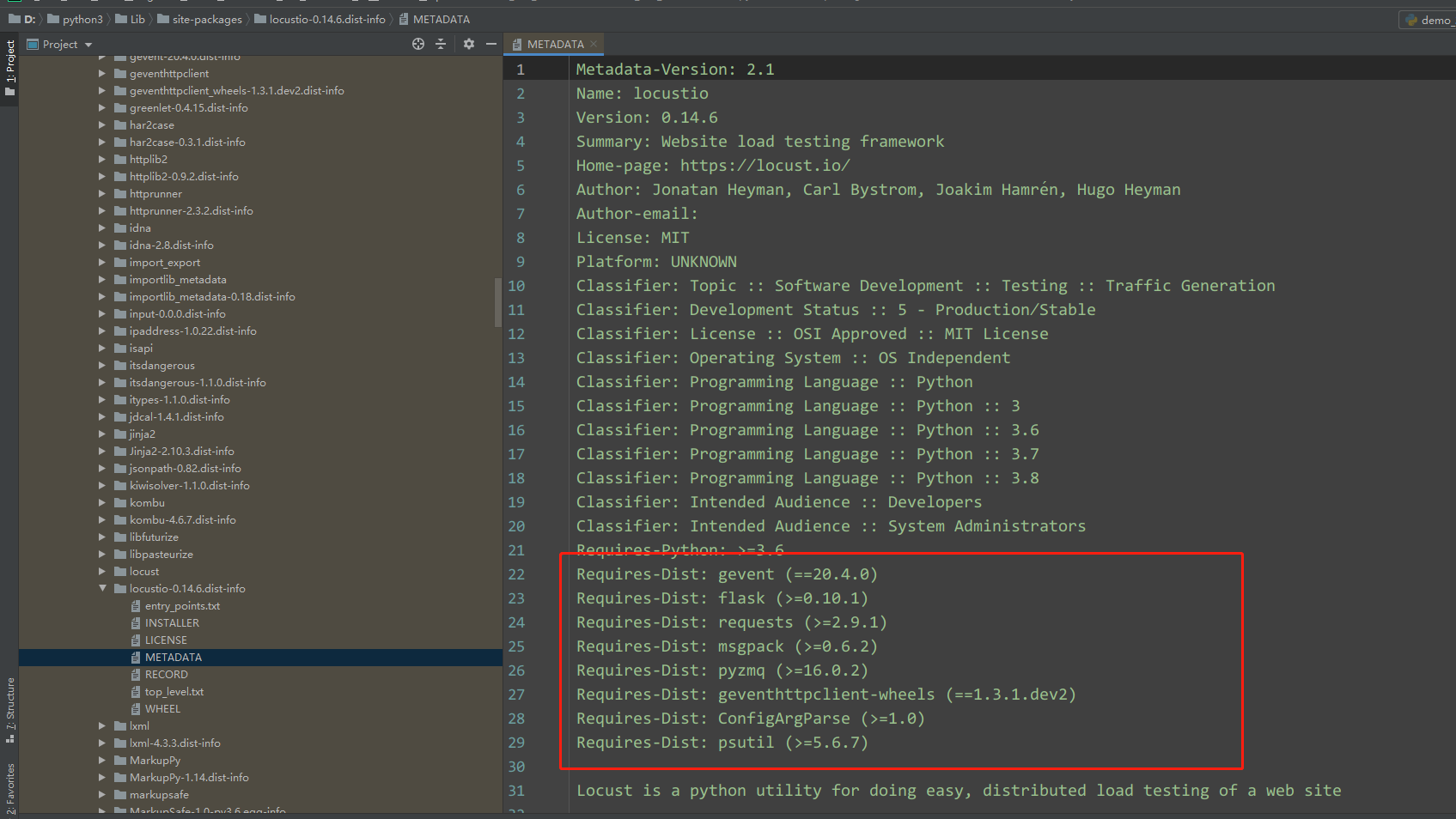
gevent 是在python中实现协程的第三方库,协程又叫微线程Coroutine。
flask 是python 的一个web开发框架。
requests 是python中可进行http(s)请求的操作库。
msgpack 是一种快速、紧凑的二进制序列化格式,适用于类似Json的数据。
pyzmq 可用于Locust分布运行在多个进程/机器上。
注意:版本version:0.11.0不支持between函数
案例
locust框架里面的请求跟python的requests库使用方法基本一致,对应关系如下:
requests.get 对应client.get requests.post 对应client.post
Locust 不同于 jmeter 可以用 GUI 来创建压测脚本。Locust 需要自己编写 python 脚本,压测负载脚本主要包含两个子类UserTask和WebsiteUser,一个用户行为类,用于定义用户的具体行为,一个设置用户性能测试类。
两个类分别继承TaskSet和Httplocust类,拥有这两个父类的公共属性和方法。
# -*- coding: utf-8 -*-
'''
@author: Leo
@software: pycharm
@file: demo_2.py
@time: 2020/6/12 0012 23:12
@Desc:
'''
__author__ = 'Leo'
import os
from locust import HttpLocust,TaskSet,task,between
import urllib3
"""
使用Python3 requests发送HTTPS请求,已经关闭认证(verify=False)情况下,控制台会输出以下错误, 忽略报错的方法如下:
InsecureRequestWarning: Unverified HTTPS request is being made.
Adding certificate verification is strongly advised.
See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings
"""
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
class Locust_baidu(TaskSet):
"""
定义Locust_baidu类,继承TaskSet类,用于定义测试任务
"""
# @task()装饰的方法为一个事务。方法的参数用于指定该行为的执行权重。参数越大每次被虚拟用户执行的概率越高。如果不设置默认为1,@task
@task(1)
def baidu(self):
"""
创建baidu方法,访问百度首页,并校验req返回值
task是任务装饰器,参数为运行次数的比例
即1表示一个Locust实例被挑选执行的权重,数值越大,执行频率越高
"""
req = self.client.get("/") # 访问百度首页,并获取对应的req
if req.status_code == 200: # 校验返回的status_code,成功则会返回200
print("success")
else:
print("fail")
class WebsiteUser(HttpLocust):
"""
HttpLocust类继承Locust类,而Locust类继承了HttpSession类,HttpSession使用率requests.Session,所以用client方法请求登录后,会保存登录状态,
具有session记忆功能
"""
# 指定定义用户行为的类,包含一组任务
task_set = Locust_baidu
# 设置用户执行任务之间等待的上下限,单位秒
wait_time = between(3,6)
# # 等同于上面wait_time,单位毫秒
# min_wait = 3000
# max_wait = 6000
if __name__ == '__main__':
os.system("locust -f demo_2.py --host=https://www.baidu.com")
运行结果:
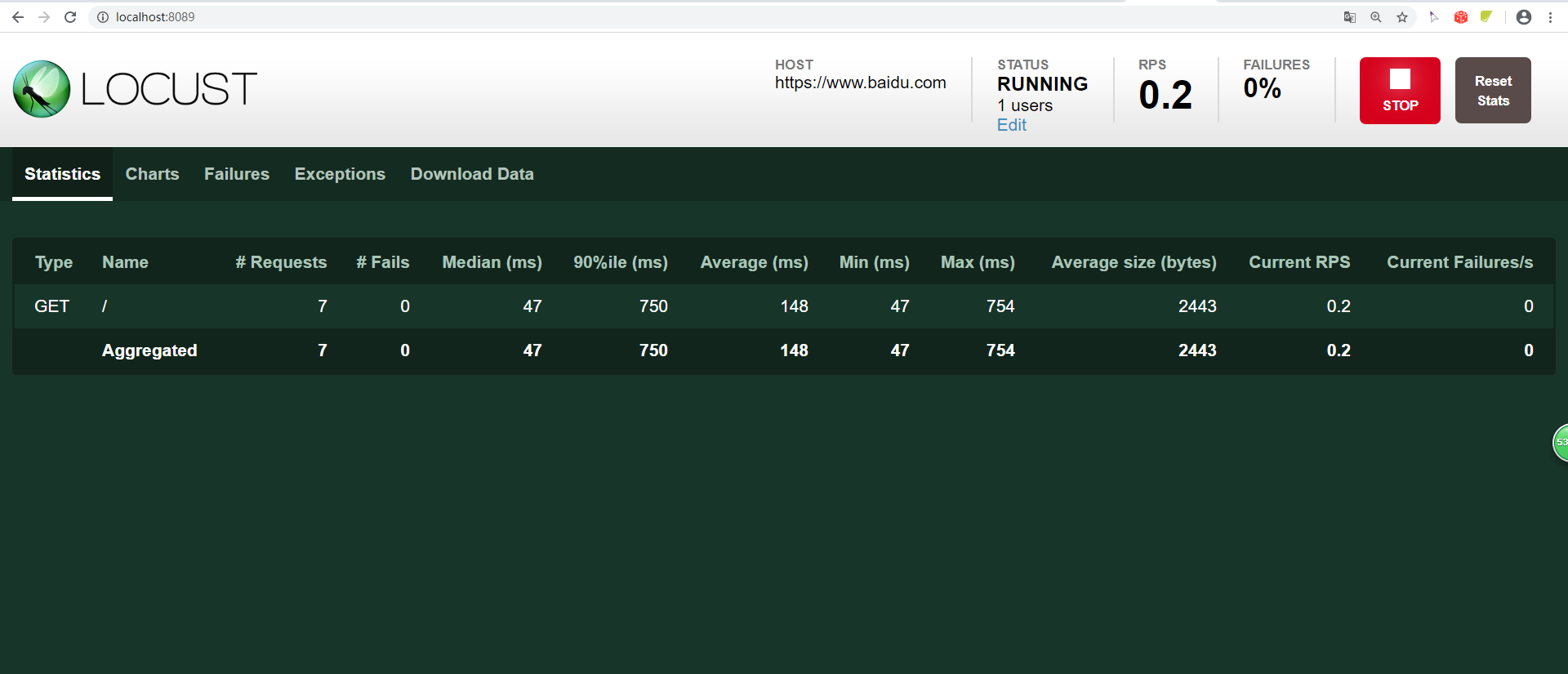
可以看出来,脚本主要包含两个类,一个是WebsiteUser(继承自HttpLocust,而HttpLocust继承自Locust),另一个是Locust_baidu(继承自TaskSet)。所以Locust性能测试脚本中主要是靠TaskSet类和Locust类来实现所有的业务场景。
Locust类其实好比一群蝗虫,每个蝗虫就是一个Locust类的实例,而TaskSet类就是蝗虫的大脑,控制着蝗虫的行为。也就是我们测试中实际场景中的任务集合。
总结
这就是Locust的最基本使用,感兴趣的可以了解一下。
如果对python测试开发相关技术感兴趣的伙伴,欢迎加入测试开发学习交流QQ群:696400122,不积跬步,无以至千里。