总结

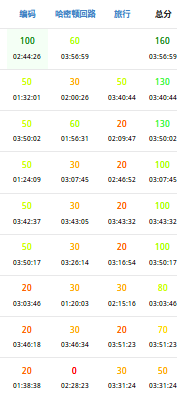
这个名次已经是倒数了
感觉整场考试不是很在状态,正解想不到,暴力分也没有打满
其实前两道题仔细推一下还是能想出来的
(T1 2-sat) 有一段时间没有打了
优化建图的方式和之前的某道题挺像的,但是当时那道题没改
这次算是补了一个锅
(T2) 的数据范围折半枚举也不难想,实现时注意一下细节就行了
(T3) 有一定的思维量
A. 编码
分析
对于每一个字符串,我们把它拆成两个状态
一个代表问号处填 (0) 的方案,一个代表问号处填 (1) 的方案
对于每一个字符串,枚举其它会与它产生冲突的字符串,向其反状态连边
然后跑一个 (2-sat) 就行了
这样建图的复杂度是 (n^2) 的
上述做法问题在于边数太多,因此我们考虑先枚举问号,然后把所有可能串建成一棵 (Trie)
在 (Trie) 树上,我们只需要由当前的节点向其反状态的所有祖先和儿子连边
具体的做法是多开两条链来辅助我们进行连边优化
就是图中右面的节点两边的边
链上反映的就是 (Trie) 上的父子关系
在两条链上又都有多个节点,和我们需要连边的节点连在一起
那么我们连边时就可以这样连
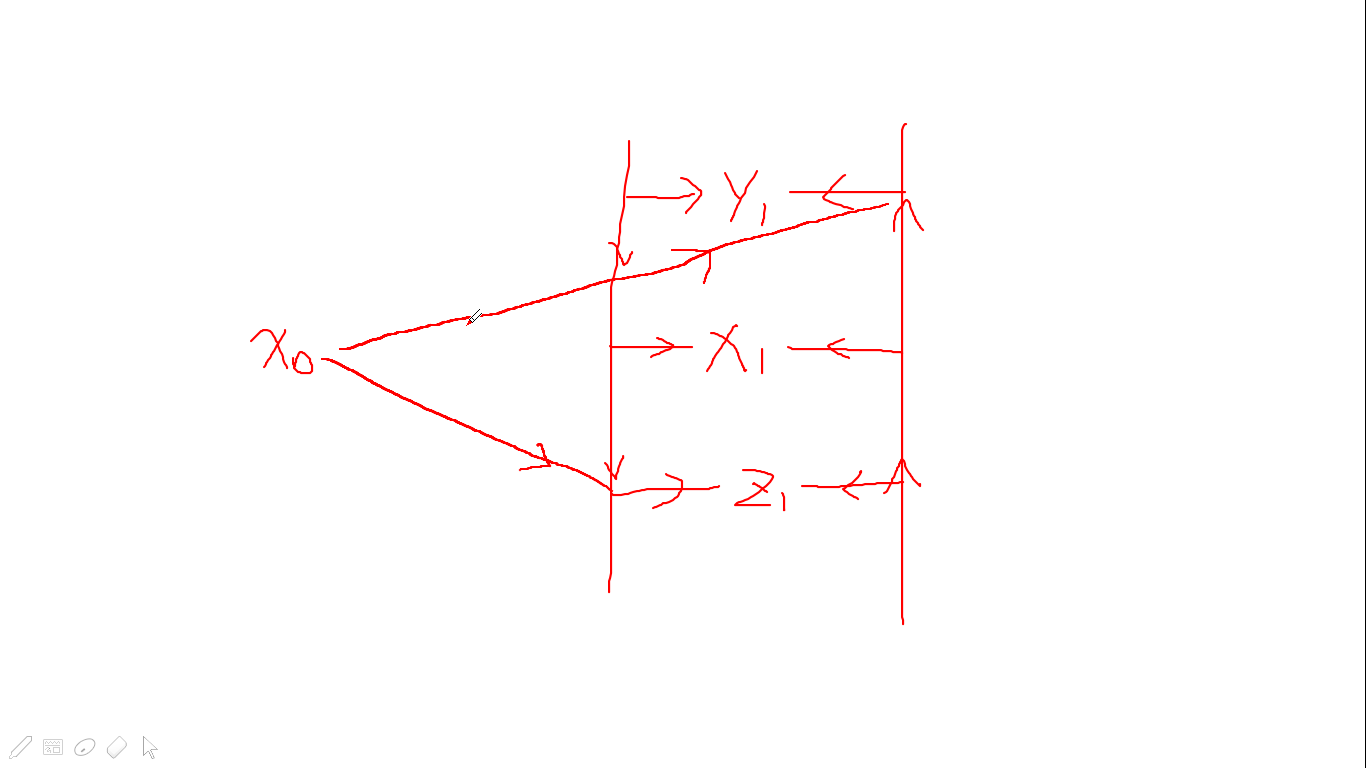
最终建出来的图就是这个样子的

图是嫖ljh巨佬的
还有一个问题就是 (Trie) 树上一个节点可能包含多个不同的字符串
我们需要强行规定一个父子关系
代码
#include<cstdio>
#include<algorithm>
#include<vector>
#include<cstring>
#define rg register
const int maxn=4e6+5;
int n,len[maxn],h[maxn],tot=1,cnt=1,tr[maxn][2];
struct asd{
int to,nxt;
}b[maxn];
void ad(rg int aa,rg int bb){
if(aa==0 || bb==0) return;
b[tot].to=bb;
b[tot].nxt=h[aa];
h[aa]=tot++;
}
int dfn[maxn],dfnc,low[maxn],shuyu[maxn],scc,sta[maxn],tp,wz[maxn];
void tar(rg int now){
sta[++tp]=now;
dfn[now]=low[now]=++dfnc;
for(rg int i=h[now];i!=-1;i=b[i].nxt){
rg int u=b[i].to;
if(!dfn[u]){
tar(u);
low[now]=std::min(low[now],low[u]);
} else if(!shuyu[u]){
low[now]=std::min(low[now],dfn[u]);
}
}
if(dfn[now]==low[now]){
scc++;
while(1){
rg int y=sta[tp--];
shuyu[y]=scc;
if(y==now) break;
}
}
}
char s[maxn];
std::vector<char> g[maxn];
std::vector<int> Node[maxn];
int fa[maxn];
void insert(rg int id,rg int op){
rg int now=1;
for(rg int i=0;i<len[id];i++){
rg int p=g[id][i]-'0';
if(!tr[now][p]){
tr[now][p]=++cnt;
fa[cnt]=now;
}
now=tr[now][p];
}
Node[now].push_back(id+n*op);
}
int getup(rg int id){
if(id>n) return id+4*n;
else return id+3*n;
}
int getdown(rg int id){
if(id>n) return id+3*n;
else return id+2*n;
}
void solvezx(rg int id){
rg int tmp1=id;
if(id>n) id-=n;
else id+=n;
rg int tmp2=getup(id);
for(rg int i=h[tmp2];i!=-1;i=b[i].nxt) if(b[i].to!=id) ad(tmp1,b[i].to);
}
void solvech(rg int id){
rg int tmp1=id;
if(id>n) id-=n;
else id+=n;
rg int tmp2=getdown(id);
for(rg int i=h[tmp2];i!=-1;i=b[i].nxt) if(b[i].to!=id) ad(tmp1,b[i].to);
}
void build(rg int da,rg int fa){
rg int mmax=Node[da].size(),now;
for(rg int i=0;i<mmax;i++){
now=Node[da][i];
ad(getdown(now),now),ad(getup(now),now);
if(fa) ad(getup(now),getup(fa)),ad(getdown(fa),getdown(now));
fa=now;
}
if(tr[da][0]) build(tr[da][0],fa);
if(tr[da][1]) build(tr[da][1],fa);
}
int main(){
memset(h,-1,sizeof(h));
memset(wz,-1,sizeof(wz));
scanf("%d",&n);
for(rg int i=1;i<=n;i++){
scanf("%s",s+1);
len[i]=strlen(s+1);
for(rg int j=1;j<=len[i];j++){
g[i].push_back(s[j]);
if(s[j]=='?') wz[i]=j;
}
}
for(rg int i=1;i<=n;i++){
if(wz[i]==-1){
insert(i,0),insert(i,1);
} else {
g[i][wz[i]-1]='0',insert(i,0);
g[i][wz[i]-1]='1',insert(i,1);
}
}
build(1,0);
for(rg int i=1;i<=2*n;i++) solvezx(i),solvech(i);
for(rg int i=1;i<=6*n;i++) if(!shuyu[i]) tar(i);
for(rg int i=1;i<=n;i++){
if(shuyu[i]==shuyu[i+n]){
printf("NO
");
return 0;
}
}
printf("YES
");
return 0;
}
B. 哈密顿回路
分析
(n=14) 的数据范围很适合折半枚举
我们从 (1) 号节点开始 (dfs) ,只搜一半的深度
用 (vector) 存一下搜到了哪些节点以及当前的状态
然后把两个状态拼在一起
排序后双指针实现即可
代码
#include<cstdio>
#include<cstring>
#include<algorithm>
#include<iostream>
#include<vector>
#define rg register
const int maxn=23,maxm=2e4+5;
int n,dep1,dep2,mmax;
std::vector<long long> g[maxn][maxm];
std::vector<int> tmp[maxn];
long long l,dis[maxn][maxn];
void dfs(rg int now,rg int zt,rg long long val,rg int cnt){
if(val+dis[1][now]>l) return;
if(cnt>dep1 && cnt>dep2) return;
if(cnt==dep1 || cnt==dep2){
g[now][zt].push_back(val);
}
rg int cs=mmax^zt;
for(rg int i=0;i<tmp[cs].size();i++){
dfs(tmp[cs][i],zt|(1<<(tmp[cs][i]-1)),val+dis[now][tmp[cs][i]],cnt+1);
}
}
void updat(std::vector<long long>&v1,std::vector<long long>&v2,rg long long val){
if(!v1.size() || !v2.size()) return;
if(v1[v1.size()-1]+v2[v2.size()-1]<val) return;
rg int tail=v2.size()-1;
for(rg int i=0;i<v1.size();i++){
while(v1[i]+v2[tail]>val && tail>=0){
tail--;
}
if(v1[i]+v2[tail]==val){
printf("possible
");
std::exit(0);
}
}
}
int main(){
scanf("%d%lld",&n,&l);
for(rg int i=1;i<=n;i++){
for(rg int j=1;j<=n;j++){
scanf("%lld",&dis[i][j]);
if(i==j) continue;
}
}
mmax=(1<<n)-1;
for(rg int i=1;i<=mmax;i++){
for(rg int j=1;j<=n;j++){
if(i&(1<<(j-1))) tmp[i].push_back(j);
}
}
dep1=n/2;
dep2=n-dep1;
dep1++;
dfs(1,1,0,1);
for(rg int i=1;i<=n;i++){
for(rg int j=0;j<=mmax;j++){
std::sort(g[i][j].begin(),g[i][j].end());
}
}
rg int ncnt=0,cs;
for(rg int i=1;i<=mmax;i++){
ncnt=0;
if(!i&1) continue;
for(rg int j=1;j<=n;j++){
if(i&(1<<(j-1))) ncnt++;
}
cs=mmax^i^1;
if(ncnt==dep1){
for(rg int o=1;o<=n;o++){
if(i&(1<<(o-1)) && g[o][i].size()){
for(rg int p=1;p<=n;p++){
if(cs&(1<<(p-1)) && g[p][cs].size()){
updat(g[o][i],g[p][cs],l-dis[o][p]);
}
}
}
}
}
}
printf("impossible
");
return 0;
}
C. 旅行
分析
首先容易想到二分答案
因此现在的问题是选取一个叶子遍历顺序
使得中间叶子间距离都 (leq mid)
由于每条树边最多经过两次,所以这是一个 (dfs)
每棵子树都是一进一出
对于有儿子的节点,它要在两个儿子的进出中分别选择一个进行合并更新答案,剩余两个加上边权后上传
设进出中较大的一个为 (a),设较小的一个为 (b),左儿子为 (lc),右儿子为 (rc)
如果 (lc.a+rc.a leq lim),肯定要把较大的在当前节点合并,然后把较小的上传
如果 (lc.a+rc.b > lim) 并且 (lc.b+rc.a>lim),此时只能把较大的两个上传,把较小的两个合并
对于其它的情况,我们分类讨论能不能上传 (lc.a+rc.b) 和 (lc.b+rc.a) 即可
如果一个答案的 (a) 和 (b) 比另一个答案的 (a) 和 (b) 都大,这个答案肯定是没有用的,直接把它排除就行了
最终的状态数不会很多,大概是 (nlogn) 级别的
代码
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<vector>
#define rg register
inline int read(){
rg int x=0,fh=1;
rg char ch=getchar();
while(ch<'0' || ch>'9'){
if(ch=='-') fh=-1;
ch=getchar();
}
while(ch>='0' && ch<='9'){
x=(x<<1)+(x<<3)+(ch^48);
ch=getchar();
}
return x*fh;
}
const int maxn=1e6+5;
int h[maxn],tot=1,n,fa[maxn],lim,tag,lc[maxn],rc[maxn],w[maxn];
struct asd{
int to,nxt;
}b[maxn];
void ad(rg int aa,rg int bb){
b[tot].to=bb;
b[tot].nxt=h[aa];
h[aa]=tot++;
}
void dfs(rg int now){
for(rg int i=h[now];i!=-1;i=b[i].nxt){
rg int u=b[i].to;
if(u==fa[now]) continue;
dfs(u);
if(!lc[now]) lc[now]=u;
else if(!rc[now]) rc[now]=u;
}
}
struct Node{
int a,b;
Node(){}
Node(rg int aa,rg int bb){
a=aa,b=bb;
}
};
std::vector<Node> g[maxn];
bool cmp(rg Node aa,rg Node bb){
if(aa.a==bb.a) return aa.b<bb.b;
return aa.a<bb.a;
}
Node init(rg int aa,rg int bb){
return Node(std::max(aa,bb),std::min(aa,bb));
}
std::vector<Node> tmp;
void solve(rg int now){
if(!tag) return;
if(!lc[now] && !rc[now]){
g[now].push_back(Node(w[now],w[now]));
return;
}
solve(lc[now]);
solve(rc[now]);
for(rg int i=0;i<g[lc[now]].size();i++){
for(rg int j=0;j<g[rc[now]].size();j++){
if(g[lc[now]][i].a+g[rc[now]][j].a<=lim){
g[now].push_back(init(g[lc[now]][i].b+w[now],g[rc[now]][j].b+w[now]));
} else if(g[lc[now]][i].a+g[rc[now]][j].b>=lim && g[lc[now]][i].b+g[rc[now]][j].a>=lim){
if(g[lc[now]][i].b+g[rc[now]][j].b<=lim){
g[now].push_back(init(g[lc[now]][i].a+w[now],g[rc[now]][j].a+w[now]));
}
} else {
if(g[lc[now]][i].a+g[rc[now]][j].b<=lim) g[now].push_back(init(g[lc[now]][i].b+w[now],g[rc[now]][j].a+w[now]));
if(g[lc[now]][i].b+g[rc[now]][j].a<=lim) g[now].push_back(init(g[lc[now]][i].a+w[now],g[rc[now]][j].b+w[now]));
}
}
}
if(g[now].size()==0){
tag=0;
return;
}
std::sort(g[now].begin(),g[now].end(),cmp);
tmp.clear();
for(rg int i=0;i<g[now].size();i++) tmp.push_back(g[now][i]);
g[now].clear();
g[now].push_back(tmp[0]);
rg int cs=tmp[0].b;
for(rg int i=1;i<tmp.size();i++){
if(tmp[i].b<cs){
g[now].push_back(tmp[i]);
cs=tmp[i].b;
}
}
}
bool jud(rg int mids){
lim=mids,tag=1;
for(rg int i=1;i<=n;i++) g[i].clear();
solve(1);
return tag;
}
int main(){
memset(h,-1,sizeof(h));
n=read();
for(rg int i=2;i<=n;i++){
fa[i]=read(),w[i]=read();
ad(i,fa[i]);
ad(fa[i],i);
}
dfs(1);
rg int l=0,r=2147483647,mids;
while(l<=r){
mids=(l+r)>>1;
if(jud(mids)) r=mids-1;
else l=mids+1;
}
printf("%d
",l);
return 0;
}