一、字符串哈希
定义
字符串哈希实质上就是把每个不同的字符串转成不同的整数
这样相对于存储整个字符串来说占用的空间更少,而且也便于比较
实现
我们可以把每一个字符想象成一个数字,然后确立一个进制(bas)
比如一个字符串(abc)
我们可以把它表示为((c-a+1) imes bas^{0} + (b-a+1) imes bas^{1} +(a-a+1) imes bas^{2})
这里有几个需要注意的地方
首先进制的选择要大于字符的种类数,否则会有很大的概率出现冲突
还有就是我们在把字符转成整形的时候,可以直接使用它的(ASCII)码值,也可以用它减去一个字符
但是在使用第二种方法的时候,减去一个字符后要加上一个(1),否则会出现错误
比如字符串(aaa)和(aa),如果我们将每一个字符减去(a)后不把它加上(1)的话
最后两个字符串的哈希值都会变成(0),也就是说会把这两个字符串判成相等,会出现错误的结果
由于字符串的长度可能很大,因此如果我们一直把它的哈希值累加的话,很有可能会溢出
因此,我们要对某个字符串的哈希值取模,方法有两种
一种是选取一个较大的质数
比如(19260817)、(19660813)、(1222827239)、(212370440130137957)
另一种是使用(unsigned long long)使其自然溢出
其实后一种方法就相当于对(2^{64}-1)取模
还有一种操作是取出字符串中某一段字符([l,r])的(hash)值
这时我们要用到一个公式(ha[r]-ha[l-l]*pw[r-l+1])
其中(ha[i])为该字符串前(i)位的(hash)值,(pw[i])为进制(bas)的(i)次方
代码实现
我们拿洛谷P3370来举例子
这里我用的是自然溢出
#include<bits/stdc++.h>
using namespace std;
typedef unsigned long long ll;
const int maxn=1e5+5;
ll f[maxn];
ll bas=233,cnt=0;
ll get_hash(char s[]){
ll ans=0,len=strlen(s);
for(ll i=0;i<len;i++){
ans=ans*bas+s[i];
}
return ans;
}
char s[maxn];
int main(){
int n;
scanf("%d",&n);
while(n--){
scanf("%s",s);
f[++cnt]=get_hash(s);
}
sort(f+1,f+1+cnt);
int now=1;
for(ll i=2;i<=cnt;i++){
if(f[i]!=f[i-1]) now++;
}
printf("%d
",now);
}
二、KMP字符串匹配
定义
(KMP)算法是一种改进的字符串匹配算法,由(D.E.Knuth,J.H.Morris)和(V.R.Pratt)提出的,因此人们称它为克努特—莫里斯—普拉特操作(简称(KMP)算法)。(KMP)算法的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是通过一个(next())函数实现,函数本身包含了模式串的局部匹配信息。(KMP)算法的时间复杂度(O(m+n))
通俗的来说就是在需要匹配的那个串上给每个位置一个失配指针(fail[j]),表示在当前位置j失配的时候需要返回到(fail[j])位置继续匹配,而这就是KMP算法优秀复杂度的核心。
实现
我们设(fail[i])为第(1)-第(i)位中前缀与后缀相同的部分最长是多长。
这样,即可以理解为,若第(i)位失配了,则至少要往前跳多少步,才可能重新匹配得上。
我们拿实际的图来演示一下
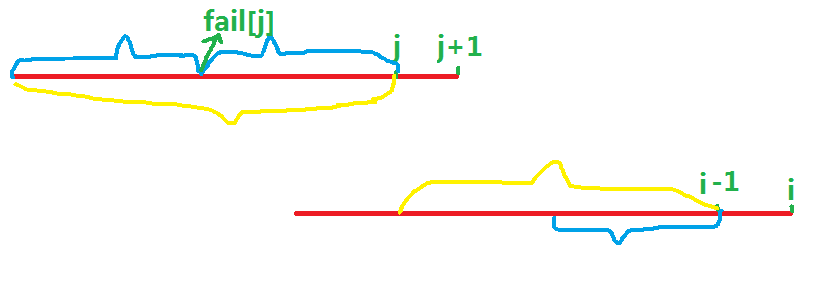
目前,我们匹配到了(i-1)的位置,(fail[i-1]=j)
即图中划黄色线的部分完全相同
我们拿当前的(fail[i-1])去继续匹配
如果(s[i]=s[j+1])那么(fail[i])更新为(j+1)即可
如果(s[i]
eq s[j+1])那么如果按照暴力的思路,我们会把(j--)继续匹配
但是实际上,我们可以直接从(fial[j])的位置开始匹配
因为图中两个蓝色的部分完全相等,而根据黄色的部分完全相等
我们又可以知道从(i-1)开始也有一个蓝色的部分和它相等
这时我们只需要判断(s[i])与(s[fail[j]+1])的关系就可以了
如果不存在,则继续跳(fail)
易证当前一定是次优解
代码实现
我们拿洛谷P3375来举例子
#include<bits/stdc++.h>
using namespace std;
const int maxn=1e6+5;
char s[maxn],s1[maxn];
int f[maxn];
int main(){
scanf("%s%s",s+1,s1+1);
int l=strlen(s+1);
int l1=strlen(s1+1);
for(int i=2,j=0;i<=l1;i++){
while(j && s1[i]!=s1[j+1]) j=f[j];
if(s1[i]==s1[j+1]) f[i]=++j;
}
for(int i=1,j=0;i<=l;i++){
while(j && s[i]!=s1[j+1]) j=f[j];
if (s[i]==s1[j+1]) j++;
if(j==l1){
printf("%d
",i-l1+1);
j=f[j];
}
}
for(int i=1;i<=l1;i++){
printf("%d ",f[i]);
}
printf("
");
return 0;
}
三、manacher算法
定义
马拉车((Manacher))算法是在(O(n))时间内解决寻找源字符串的最长回文子串(S)的问题的算法。
实现
首先我们要知道,回文串分为奇回文串和偶回文串
像(aaaa)这样的就是偶回文串,而(aba)则是奇回文串
不难发现,奇回文串都有一个回文中心,因此在查找时可以由中心向两边扩展
但是偶回文串则没有这一个性质,因此查找起来不如奇回文串方便
为了使查找更方便,我们可以让所有的偶回文串都变成奇回文串
操作实现也很简单,就是将原字符串的首部和尾部以及每两个字符之间插入一个特殊字符,这个字符是什么不重要,不会影响最终的结果
同时还要在队首之前再插入另一种特殊字符,防止运算时越界
比如(abaca)扩展后变为(#*a*b*a*c*a*)
在进行马拉车算法时,我们要维护一个已经确定的右侧最靠右的回文串的右边界(r)和回文中心(mids)
同时定义一个数组(f[i])为以(i)为中心的最大回文半径
当我们遍历到(i)时,如果(i)在右边界之内
那么根据对称性,有(f[i]=f[s*mids-i])
同时,(i)所扩展的范围必须在(r)之内,因此结果还要与(r-i+1)取(min)
扩展完已知的区域,我们再向两边扩展未知的区域
最后我们更新(mids)和(r)即可
最后的答案就是最大回文半径减去一,手模一下即可
代码实现
我们拿洛谷P3805来举例子
#include<bits/stdc++.h>
using namespace std;
const int maxn=22e6+5;
char s1[maxn],s[maxn];
int f[maxn],ans,n,cnt;
int main(){
scanf("%s",s1+1);
n=strlen(s1+1);
cnt=2*n+1;
for(int i=1;i<=cnt;i++){
if(i&1) s[i]='&';
else s[i]=s1[i/2];
}
s[0]='%';
for(int i=1,mids=0,r=0;i<=cnt;i++){
if(i<=r) f[i]=min(f[2*mids-i],r-i+1);
while(s[i+f[i]]==s[i-f[i]]) f[i]++;
if(i+f[i]>r) r=i+f[i]-1,mids=i;
if(f[i]>ans) ans=f[i];
}
printf("%d
",ans-1);
return 0;
}
下接字符串学习笔记二