前言:笔者之前是cv方向,因为工作原因需要学习NLP相关的模型,因此特意梳理一下关于NLP的几个经典模型,由于有基础,这一系列不会关注基础内容或者公式推导,而是更侧重对整体原理的理解。顺便推荐两个很不错的github项目——开箱即用的中文教程以及算法更全但是有些跑不通的英文教程。
一. fasttext模型的目的以及预备知识
fasttext是facebook提出的一个文本分类工具(也可用于词向量计算),优势是:
- 在浅层训练上取得了和一些深层网络类似的精度
- 训练速度比较快
1. 分层softmax
即YOLOv2中提过的类别数,主要为了解决词向量维度比较大的问题,如下图:
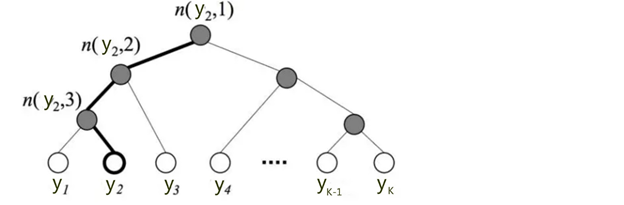
计算y2的类别只需要计算三次二分类逻辑回归然后把概率相乘即可,分层softmax计算的是条件概率
2. n-gram特征
文本特征生成的一种算法,即按照滑动窗口方法按照字节顺序滑动出长度为N的字节片段序列,例如取N=2,对今天天气非常晴朗,可以得到:
今天,天天,天气,气非,非常,常晴,晴朗(字粒度)
今天/天气,天气/非常,非常/晴朗(词粒度)
二. fasttext实现
- fasttext采用字符级别的n-gram去表示一个单词,例如apple就可以由如下特征组成:“<ap”, “app”, “ppl”, “ple”, “le>”,这样做的好处是:
- 对于一些高度类似的单词,比如apple和apples,它们的特征会有很多重叠的部分,可以复用;而且低频词可以由于特征重复获益
- 对于训练库以外的单词,也可以尝试构建词向量
- fasttext的一个网络结构的简单示意图如下,具体输入以及网络见下部分分析
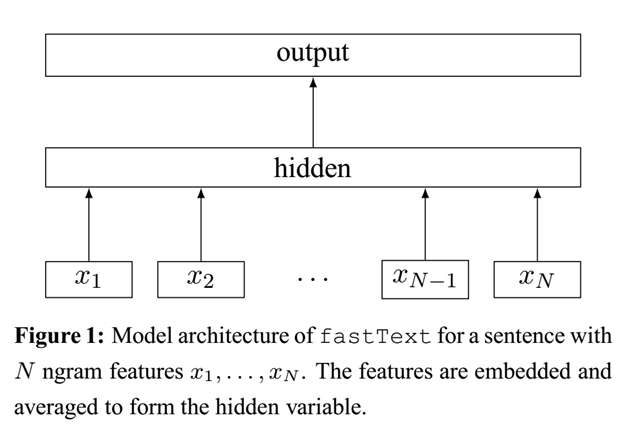
三. FastText的输入以及结构
- 获取词表,词表分为char级别和word级别,可以视作字典,其中key是所有可能的char或者word,而value则是其对应的id;假设此处词表的长度为D,即最多有D个不同的char或word
- 对输入语句进行分为1中的char或者word,即分词;根据1中每个char或者word的id,原句从文字转化为一串数字,称之为词向量,一般来说转化后的词向量是定长的,所以要短补长截
- n-gram特征的生成:
- n-gram特征也是向量,它的每个元素也是从一个n-gram词表中得到的,词表的大小是一个超参,假设n-gram词表的长度为B
- n-gram可以同时使用多个,比如n=2的bigram以及n=3的trigram
- 一般来说,n-gram词表的构建需要人为定义一个关系。以n=2的bigram为例,用一个大小为2的滑动窗口遍历词向量,窗口内是一个二维数组[a, b],其中a和b都是词向量中的元素,因此它们大于等于零小于D;我们要将[a, b]映射到一个整数b_id上,b_id大于等于零,小于B……映射方式可以自己定义,比如相乘取余等。滑动窗口如果需要应该在两边补零以保证生成的gram特征的长度和词向量特征的长度相同
- embedding:词向量和多个n-gram特征向量都需要做embedding,embedding可以使用预训练网络或者随机初始化;embedding会改变大小,以bs=128,词向量长度V=32为例,输入的特征都是128x32的,可以手动设定一个映射维数的超参,比如300,则映射后tensor大小变成128x32x300,元素也从原来的正整数变为小数
- 网络结构:连缀所有向量,并在词向量长度V的维度上取平均值作为特征表示;可以设定1~2个fc层和dropout层最后得到分类概率