本章的作业依旧包括两部分,1.阅读学习教材「Linux内核设计与实现 (Linux Kernel Development)」第教材第11,12章。
2.学习MOOC「Linux内核分析」第六讲「进程的执行和进程的切换」,并完成实验楼上配套实验六。
在本次试验中,我们首先新建了一个hello.c的文件,并在里面编辑简单的输出hello world的代码。
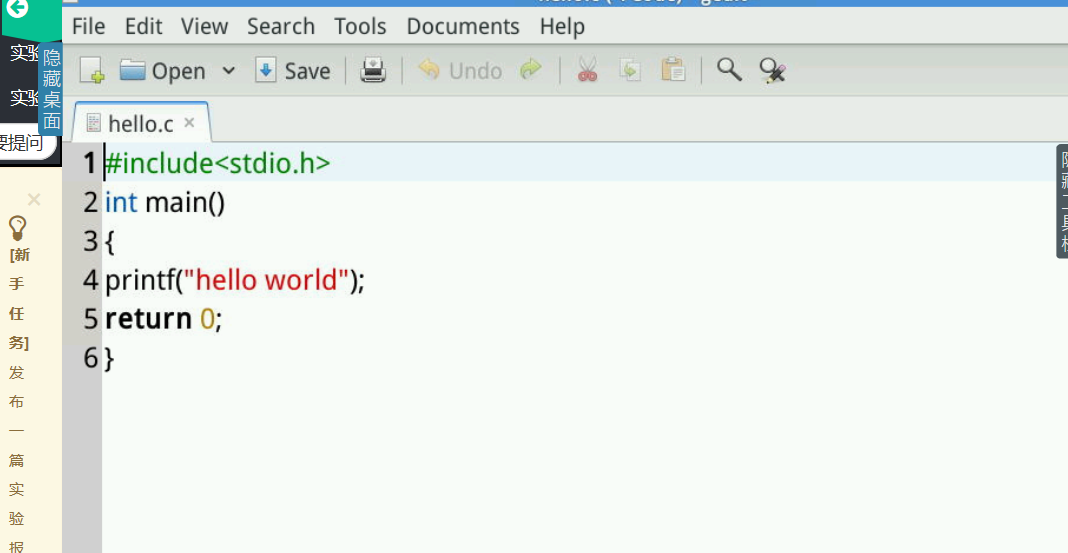
调用命令gcc -E -o hello.cpp hello.c -m32编辑出预处理的中间文件hello.cpp.预处理负责把include的文件包含进来及宏替换等工作

然后我们调用命令gcc -x cpp-output -S -o hello.s hello.cpp -m32编译hello.cpp为代码目标代码hello.s。ELF格式,二进制文件,有一些机器指令,只是还不能运行

接着继续调用gcc -x assmebler -c hello.s -o hello.o -m32汇编成他的二进制文件。ELF格式,二进制文件,有一些机器指令,只是还不能运行

接下来调用gcc -o hello hello.o -m32链接成它的可执行文件并运行。(ELF格式,二进制文件)
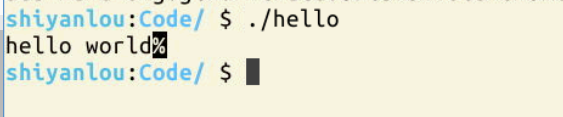

这里的可执行文件已经链接成功了,我们打开hello查看数据,发现开头有elf,这里的elf就是指的它的文件格式。在hello可执行文件里面使用了共享库,会调用printf,libc库里的函数
这里的printf使用的是共享库,我们试着使用静态编译。gcc -o hello.static hello.o -m32 -static 把执行所需要依赖的东西都放在程序内部

接下来我们了解了具体命令的含义。
-c
只激活预处理,编译,和汇编,也就是他只把程序做成obj文件
例子用法:
gcc -c hello.c
他将生成.o的obj文件
-S
只激活预处理和编译,就是指把文件编译成为汇编代码。
例子用法
gcc -S hello.c
他将生成.s的汇编代码,你可以用文本编辑器察看
-E
只激活预处理,这个不生成文件,你需要把它重定向到一个输出文件里
面.
例子用法:
gcc -E hello.c > pianoapan.txt
gcc -E hello.c | more
慢慢看吧,一个hello word 也要与处理成800行的代码
-o
制定目标名称,缺省的时候,gcc 编译出来的文件是a.out,很难听,如果
你和我有同感,改掉它,哈哈
例子用法
gcc -o hello.exe hello.c (哦,windows用习惯了)
gcc -o hello.asm -S hello.c
接下来使用ls -l查看每一个文件的属性。
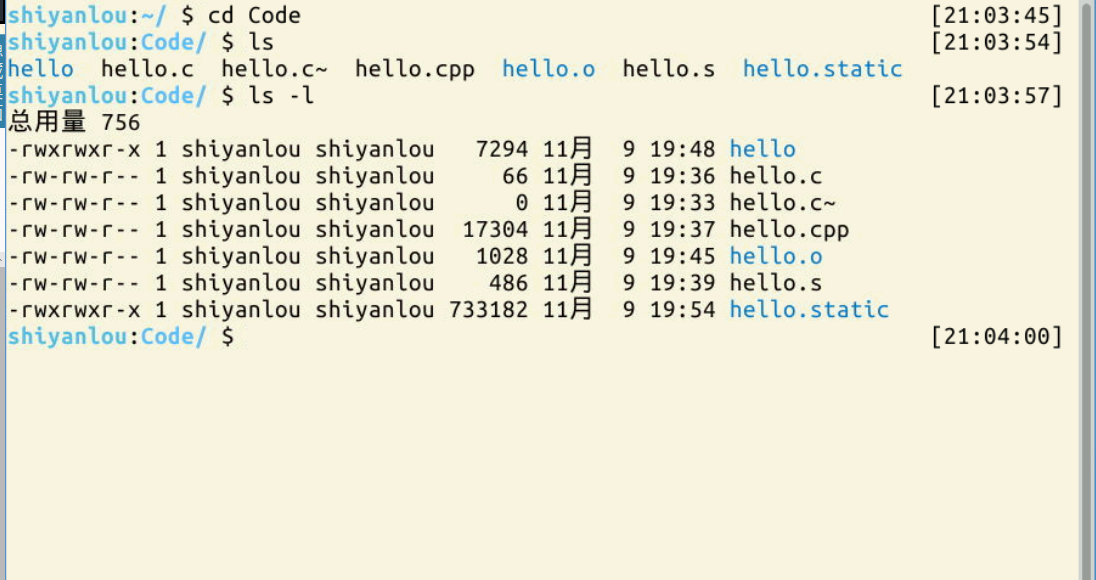
从这里可以看出动态链接的可执行文件hello的内存远远小于静态链接的hello.static。
为了更清楚的了解程序执行的过程,我们调用readelf -h hello来查看hello的文件。

这里面包含程序运行的所有信息,包括版本号,兼容格式,ABI的版本,是不是可执行文件,入口地址,数据段的原数据。
下面使用gdb跟踪分析一个execve系统调用内核处理函数sys_execve。


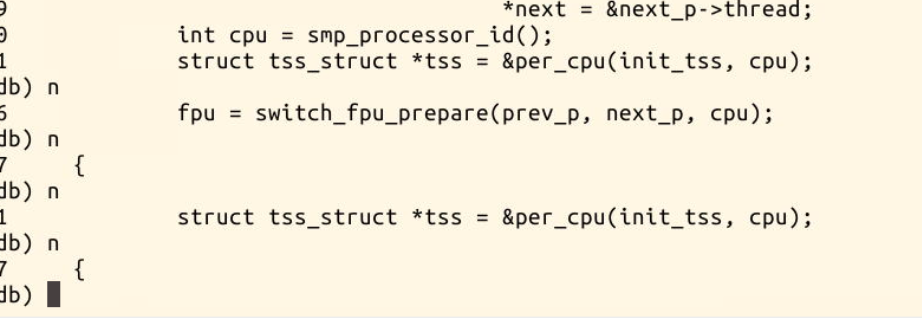




在他里面我们对三个函数打上断点进行观察,分别是sys_execve,load_elf_binary,start_thread.
通过gdb调试分析可以知道对于execve系统调用的执行流程是
sys_execve
do_execve
do_execve_common
exec_binprm ->
search_binary_handler
load_binary
load_elf_binary (也执行了elf_format)
start_thread。
当系统调用execve时,系统陷入内核,这时会创建一个新的用户态堆栈,把命令行参数的内容和环境变量的内容通过指针的方式传递给系统调用内核处理函数的,然后内核处理函数在创建可执行程序新的用户态堆栈的时候,会把这些拷贝到用户态堆栈初始化新的可执行程序的执行上下文环境。这时就加载了新的可执行程序。系统调用exceve返回用户态的时候,就变成了被exceve加载的可执行程序。
首先sys_execve调用了do_execve,该函数将参数和环境变量的数据结构进行修改后调用了do_execve_common。
SYSCALL_DEFINE3(execve,
const char __user *, filename,
const char __user *const __user *, argv,
const char __user *const __user *, envp)
{
return do_execve(getname(filename), argv, envp);//其中,filenamei是可执行文件路径名的地址,argv是命令行参数指针数组(最后一个元素为NULL)的地址,envp是环境变量指针数组(最后一个元素也为NULL)的地址。
}
int do_execve(struct filename *filename,
const char __user *const __user *__argv,
const char __user *const __user *__envp)
{
struct user_arg_ptr argv = { .ptr.native = __argv };
struct user_arg_ptr envp = { .ptr.native = __envp };
return do_execve_common(filename, argv, envp);//其中,filenamei是可执行文件路径名的地址,argv是命令行参数指针数组(最后一个元素为NULL)的地址,envp是环境变量指针数组(最后一个元素也为NULL)的地址。
}
继续看,do_execve_common函数可以抽象为下面的结构:
int do_execve_common()
{
file = do_open_exec(filename); //打开要加载的可执行文件
...
各种初始化bprm//初始化linux_binprm结构体变量*bprm的file、filename和interp三个字段。
...
exec_binprm(bprm); //加载程序
}
其中加载程序的exec_binprm函数中,调用了关键的search_binary_handler(bprm),该函数遍历链表来尝试加载目标文件,找到了则执行load_binary.
list_for_each_entry(fmt, &formats, lh) {
if (!try_module_get(fmt->module))
continue;
read_unlock(&binfmt_lock);
bprm->recursion_depth++;
retval = fmt->load_binary(bprm);
read_lock(&binfmt_lock);
put_binfmt(fmt);
bprm->recursion_depth--;
...
目标文件的格式是ELF,所以相应的load_binary为load_elf_binary,该函数可以抽象如下:
load_elf_binary()
{
...
解析ELF文件
...
elf_map(bprm->file, load_bias + vaddr,...) //把目标文件映射到地址空间中
...
if (elf_interpreter) {把elf_entry设置为动态链接器ld的起点}
else {目标文件的入口赋值给elf_entry}
...
start_thread(..., elf_entry, ...);
}
该函数的核心工作一是解析ELF文件,二是把目标文件映射到进程空间中,三是调用start_thread。start_thread实际上在修改了内核堆栈后调用iret返回用户态,把我们返回用户态的位置从int 0x80的下一条指令的位置变成新加载的可执行文件的entry位置(new_ip)。
start_thread(struct pt_regs *regs, unsigned long new_ip, unsigned long new_sp)
{
set_user_gs(regs, 0);
regs->fs = 0;
regs->ds = __USER_DS;
regs->es = __USER_DS;
regs->ss = __USER_DS;
regs->cs = __USER_CS;
regs->ip = new_ip;
regs->sp = new_sp;
regs->flags = X86_EFLAGS_IF;
/*
* force it to the iret return path by making it look as if there was
* some work pending.
*/
set_thread_flag(TIF_NOTIFY_RESUME);
}
Linux任务切换是通过switch_to实现的。switch_to本身是一个宏,通过利用长跳指令,当长跳指令的操作数是TSS描述符的时候,就会引起CPU的任务的切换,此时,cpu将所有寄存器的状态保存到当前任务寄存器TR所指向的TSS段(当前任务的任务状态段)中,然后利用长跳指令的操作数(TSS描述符)找到新任务的TSS段,然后将其中的内容填写到各个寄存器中,最后,将新任务的TSS选择符更新到TR中。这样系统就正式开始运行新切换的任务了。
在MenOS中对schedule、context_switch、switch_to设置断点,
进程切换调用的是schedule()函数,该函数调用了__schedule().
asmlinkage __visible void __sched schedule(void)
{
struct task_struct *tsk = current;
sched_submit_work(tsk);
__schedule();
}
static void __sched __schedule(void)
{
...
next = pick_next_task(rq, prev);
if (likely(prev != next)) {
...
context_switch(rq, prev, next); /* unlocks the rq */
...
} else {
...
raw_spin_unlock_irq(&rq->lock);
...
}
...
post_schedule(rq);
...
}
对于其中的context_switch()
context_switch {
...
mm = next->mm;
if(!mm) {
next->active_mm = oldmm;
...
}
else
switch_mm(oldmm, mm, next);
...
switch_to(prev, next, prev);
...
}
该函数做了两件事情,第一是切换页表switch_mm,当next进程mm为空(next是内核线程)时,则使用当前进程的页表,否则切换成新进程的页表(用户态地址空间);第二是切换进程switch_to
#define switch_to(prev, next, last) do { unsigned long ebx, ecx, edx, esi, edi; asm volatile("pushfl " /*保存当前进程的flag */ "pushl %%ebp " /* 保存当前进程EBP */ "movl %%esp,%[prev_sp] " /* 保存当前的内核栈顶 */ "movl %[next_sp],%%esp " /* 恢复下一个进程的内核栈顶 */ //内核堆栈角度,这里已经切换到next的内核堆栈了 "movl $1f,%[prev_ip] " /*将标号1放入当前进程的EIP*/ "pushl %[next_ip] " /* 恢复下一个进程的EIP,next内核堆栈的栈顶 */ "jmp __switch_to " /*寄存器传递参数,jmp不压栈EIP*/ //EIP角度,这里是新的进程的执行入口 "1: " /*switch_to 返回到这里*/ "popl %%ebp " /* restore EBP */ "popfl " /* restore flags */ /* output parameters */ : [prev_sp] "=m" (prev->thread.sp), /*字符串标号*/ [prev_ip] "=m" (prev->thread.ip), "=a" (last), /* clobbered output registers: */ "=b" (ebx), "=c" (ecx), "=d" (edx), "=S" (esi), "=D" (edi) __switch_canary_oparam /* input parameters: */ : [next_sp] "m" (next->thread.sp), [next_ip] "m" (next->thread.ip), /* regparm parameters for __switch_to(): */ [prev] "a" (prev), [next] "d" (next) __switch_canary_iparam : /* reloaded segment registers */ "memory"); } while (0)对于其中的switch_to函数其执行步骤大致为 (1)复制两个变量到寄存器[prev]"a" (prev)[next]"d" (next) (2)保存进程A的ebp和eflags (3)保存当前esp到A进程内核描述符中 (4)从next(进程B)的描述符中取出之前从B切换出去时保存的esp_B (5)把标号为1的指令地址保存到A进程描述符的ip域 (6)将返回地址保存到堆栈,然后调用switch_to()函数,switch_to()函数完成硬件上下文切换 (7)从switch_to()返回后继续从1:标号后面开始执行,修改ebp到B的内核堆栈,恢复B的eflags (8)将eax写入last,以在B的堆栈中保存正确的prev信息 第二部分主要是对课本知识点的掌握,阅读十一,十二章节,我有以下收获。 首先,系统定时器和时钟中断处理程序是Linux系统内核管理机制中的中枢。还有用来推迟执行程序的一种工具-动态定时器。 在我们利用时间中断周期执行工作时,下面几个工作会用到。1.更新系统运行时间。 2.更新实际时间。 3.在smp系统上,均衡调度程序中各处理器上的运行队列。 4.检查当前进程是否用尽了自己的时间片。 5.运行超时的动态定时器。 6.更新资源消耗和处理器时间的统计值。在节拍率小节,知道了高节拍率的好处:
1.更高的中断解析度可提高时间驱动时间的解析度。 2.提高了时间驱动的准确度。高HZ的优势:
1.内核定时器能够已更高的频度和更高的准确度运行。 2.依赖定时值执行的系统调用能够以更高的精度运行。 3.对诸如资源消耗和系统运行时间等的测量会有更精细的解析度。 4.提高进程抢占的准确度。高HZ的劣势:
节拍率越高,意味着时钟中断的频率越高,也意味着系统负担越重。因为处理器必须花时间来执行时钟中断处理程序,所以节拍率越高,中断处理程序占用的处理器的时间越多,这样不但减少了处理器处理其他工作的时间,而且还会更频繁地打乱处理器高速缓存并增加耗电。
处理程序的具体工作依赖于特定的体系结构,但是绝大多数处理程序最低限度也都要执行如下操作。1.获得xtime——lock锁,以便对访问jiffies_64和墙上时间xtime进行保护。 2.需要时应答或重新设置系统时钟。 3.周期性地使用墙上时间更新实时时钟。 4.调用体系结构无关的时钟例程:tick_periodic();本章节主要学习了时间的概念,并知道了墙上时钟与计算机的正常运行时间如何管理。在十二章内存管理章节,本章主要讲述了如何在内核中获取内存的方法,并学习Linux如何管理内存。我们首先看到了内存空间的各种不同的描述单位,包括字节,页面和区。还有内存分配机制,包括页分配器和slab分配器。
定时器和时间管理内核中大量函数都是基于时间驱动的。体系结构提供了两种设备进行计时——系统定时器和实时时钟。实时时钟(RTC)是用来持久存放系统时间的设备,系统关闭后靠主板上的微型电池供电,它在系统启动时初始化xtime变量。
系统定时器以某种频率自行触发时钟中断,该频率可通过编程预定,称作节拍率;连续两次时钟中断的时间间隔称为节拍。提高节拍率有利有弊,优点是:
•内核定时器能以更高的频度和更高的准确度运行;•依赖定时值执行的系统调用能够以更高的精度运行;
•对资源消耗和系统运行时间等的测量会有更精细的解析度;
•提高进程抢占的准确度。
缺点是:节拍率越高,时钟中断频率越高,处理器用来执行时钟中断处理程序的时间越多,系统负担就越重。
全局变量jiffies用来记录自系统启动以来产生的节拍总数。jiffies是无符号长整型数据,其他任何类型存放它都不正确。
内核定义了USER_HZ代表用户空间看到的HZ值,内核可以使用函数jiffies_to_clock_t()将一个由HZ表示的节拍数转换成一个由USER_HZ表示的节拍计数(如果是64位jiffies,则使用函数jiffies_64_to_clock_t())。tick_periodic()是调用体系结构无关的时钟例程。
do_timer()承担着对jiffies_64的实际增加操作;update_process_times()根据流逝的时间更新墙上时钟。do_timer()返回时调用update_process_times()更新所耗费的各种节拍数。
account_process_tick()函数对进程时间进行实质性更新;scheduler_tick()负责减少当前运行进程的时间片计数值并且在需要时设置need_resched标志。墙上时间就是当前实际时间,定义为xtime,读写xtime变量需要使用xtime_lock锁,该锁是一个seqlock锁。从用户空间取得墙上时间主要接口是gettimeofday(),对应的系统调用为sys_gettimeofday()。设置当前时间的系统调用是settimeofday()。
定时器是管理内核流逝的时间基础,由结构timer_list表示:
struct timer_list { struct list_head entry;//定时器链表入口 unsigned long expires;//以jiffies为单位的定时值 void (*function) (unsigned long);//定时器处理函数 unsigned long data;//传给处理函数的长整型参数 struct tvec_t_base_s *base;//定时器内部值,用户不要使用 }定时器其他函数:
add_timer(&my_timer);//激活定时器 mod_timer(&my_timer,jiffies+new_delay);//修改超时时间 del_timer(&my_timer);//停止定时器内存管理
内核把物理页作为内存管理的基本单位。内何用struct page结构表示系统中每个物理页。
struct page { unsigned long flags; atomic_t _count; atomic_t _mapcount; unsigned long private; struct address_space *mapping; pgoff_t index; struct list_head lru; void *virtual; }flags域存放页的状态,_count域存放页的引用计数,virtual域是页的虚拟地址。
获得页最核心的函数是:
struct page * alloc_pages(gft_t gfp_mask, unsigned int order);该函数分配2^order个连续的物理页并返回指向第一个页的page结构体的指针。可以通过下面函数把给定页换成逻辑地址:
void * page_address(struct page *page);slab是为了防止频繁的数据结构的分配和释放而提出的。当不需要一个数据结构实例时,是把它放入空闲链表等待下次分配,而不是释放它。