Spark(三)角色和搭建
一、Spark集群角色介绍
详见JerryLead/SparkInternals,他的图解介绍能清晰的讲清楚Spark集群
二、集群的搭建
2.1.架构(图片来源,Spark官网)
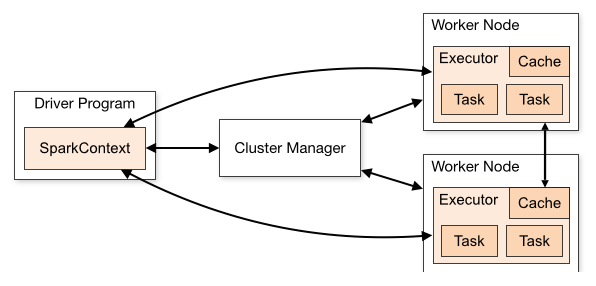
一个Driver Program含有一个SparkContext,课由ClusterManager进行通讯到Worker节点,每个Application都有自己的Executor,与其他程序完全隔离
2.2.Spark-2.3.4 standlone搭建
1.获取
wget http://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.3.4/spark-2.3.4-bin-hadoop2.7.tgz
2.解压
tar -xf spark-2.3.4-bin-hadoop2.7.tgz
3.移动到/opt/bigdata中
mv spark-2.3.4-bin-hadoop2.7.tgz /opt/bigdata
4.修改环境变量SPARK_HOME
这步省略(如果不知道如何修改环境变量,参考我的Hadoop Ha搭建文章)
5.进入SPARK_HOME/bin/spark-shell,我们进入一个scala交互环境
这边可以测试wc代码,默认sparkContext自动为sc,所以wc代码如下
sc.textFile("/root/data.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).foreach(println);
2.3.Spark集群搭建
1.修改conf/spark-env.sh
export HADOOP_CONF_DIR=/opt/bigdata/hadoop-2.6.5
为了找到我们之前配置好的hadoop集群
export SPARK_MASTER_HOST=node01
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_WEBUI_PORT=8080
export SPARK_WORKER_CORES=2
export SPARK_WORKER_MEMORY=1g
2.修改slaves
node02
node03
node04
拷贝这两个配置到其他三个节点
3.spark-shell集群式启动
start-all.sh
spark-shell --master spark://node01:7077
进入scala的交互环境,运行一下wc
sc.textFile("hdfs://mycluster/sparktest/data.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).foreach(println)
发现没有输入,因为在分区上输出了,所以我们需要一个回收算子
sc.textFile("hdfs://mycluster/sparktest/data.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect().foreach(println)
2.3.Spark高可用处理
1.spark-defaults.conf修改
这边的配置可以向zookeeper上面进行注册发现
spark.deploy.recoveryMode ZOOKEEPER
spark.deploy.zookeeper.url node02:2181,node03:2181,node04:2181
spark.deploy.zookeeper.dir /littlepagespark
2.启动流程
./spark-shell --master spark://node01:7077,node02:7077
提示:node02的master需要自行启动,所以我们需要更改node02的conf/env文件
三、history服务
1.配置spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://mycluster/shared/spark-logs
spark.history.fs.logDirectory hdfs://mycluster/spark_log
手动开启历史服务./start-history-server.sh
之后访问node01:18080端口即可
四、使用spark-submit进行计算Pi
代码参照官网
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
// scalastyle:off println
package org.apache.spark.examples
import scala.math.random
import org.apache.spark.sql.SparkSession
/** Computes an approximation to pi */
object SparkPi {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.appName("Spark Pi")
.getOrCreate()//创建一个spark pi
//如果参数大于0,则返回切片数量为args,否则返回2
val slices = if (args.length > 0) args(0).toInt else 2
//n为切片乘100000L和Int最大值的最大,转为Int,避免溢出
val n = math.min(100000L * slices, Int.MaxValue).toInt // avoid overflow
//计算随机数,是否落到圆上
val count = spark.sparkContext.parallelize(1 until n, slices).map { i =>
val x = random * 2 - 1
val y = random * 2 - 1
if (x*x + y*y <= 1) 1 else 0
}.reduce(_ + _)
//打印
println(s"Pi is roughly ${4.0 * count / (n - 1)}")
spark.stop()
}
}
// scalastyle:on println
使用Spark-submit运行
spark-submit --master spark://node01:7077,node02:7077 --class org.apache.spark.examples.SparkPi ./spark-examples_2.11-2.3.4.jar 1000
spark-submit --master url --class [package.class] [jar] [args]
spark-submit参数
--deploy-mode cluster #部署模式,默认cluster
--driver-memory 1024m #driver内存
--total-executor-cores 6 #总共6核心
--executor-cores 1 #每个executor1个核
--executor-memory 1024m #executor内存1024m
五、Spark On Yarn
在hadoop-env.sh仅需要配置export hadoop_conf_dir的目录即可,worker和master均不需要,slaves也不需要了,zk的配置也不需要了
1.hadoop-env.sh修改
export HADOOP_CONF_DIR=/opt/bigdata/hadoop-2.6.5/etc/hadoop
2.spark-defaults.conf修改
spark.eventLog.enabled true
spark.eventLog.dir hdfs://namenode/shared/spark-logs
spark.history.fs.logDirectory hdfs://mycluster/spark_log
3.yarn-site.xml
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>4</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
4.mapred-site.xml
mr-jobhistory-daemon.sh start historyserver
<property>
<name>mapred.job.history.server.embedded</name>
<value>true</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node03:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node03:50060</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/work/mr_history_tmp</value>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/work/mr-history_done</value>
</property>
启动历史服务
mr-jobhistory-daemon.sh start historyserver
启动spark-yarn
./spark-shell --master yarn
六、shell脚本
class=org.apache.spark.examples.SparkPi
jar=$SPARK_HOME/examples/jars/spark-examples_2.11-2.3.4.jar
master=yarn
$SPARK_HOME/bin/spark-submit
--master $master
--class $class
--deploy-mode cluster
$jar
100
七、调优
spark-defaults.conf增加配置
spark.yarn.jars hdfs://mycluster/work/spark_lib/jars/*
把spark jars目录完全上传
hdfs dfs -put ./* /work/spark_lib/jars/
其余调优详见四的参数