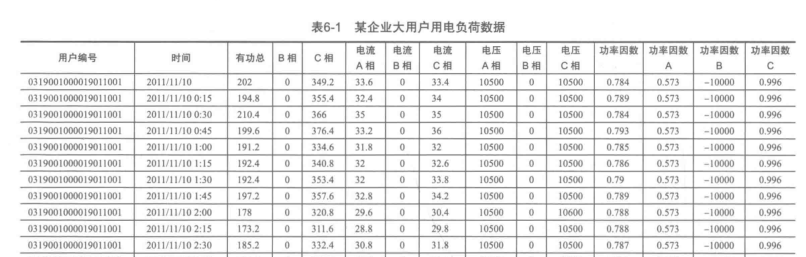
一、背景与挖掘目标
相关背景自查
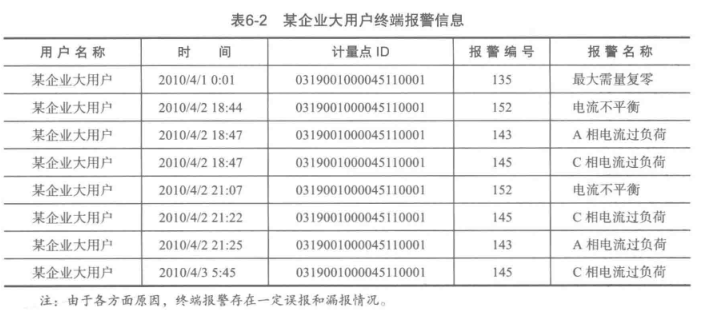
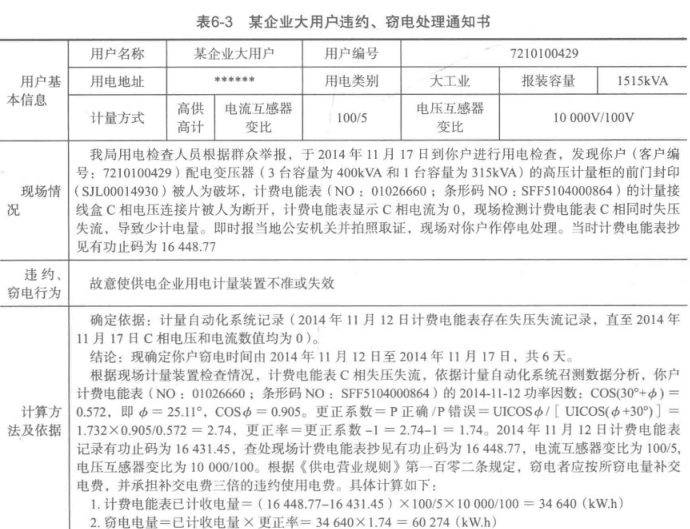

二、分析方法与过程

1、EDA(探索性数据分析)
1.分布分析
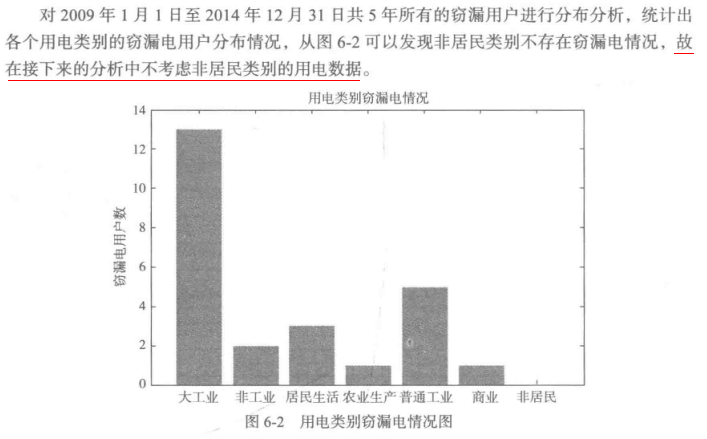
2.周期性分析
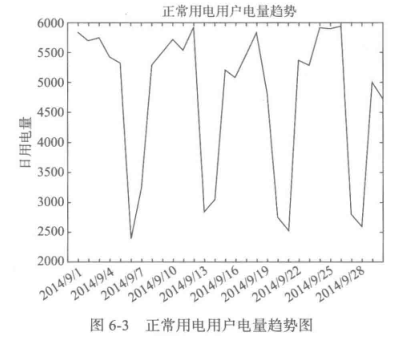
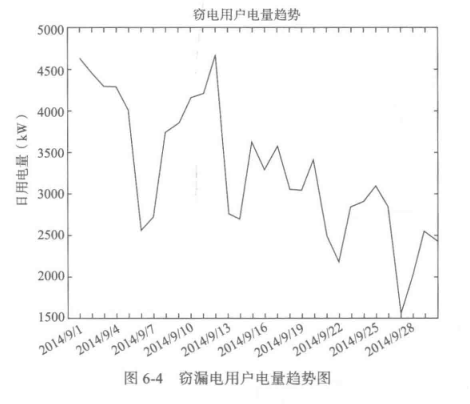
2、数据预处理
1.数据清洗
过滤非居民用电数据,过滤节假日用电数据(节假日用电量明显低于工作日)
2.缺失值处理


#拉格朗日插值代码 import pandas as pd #导入数据分析库Pandas from scipy.interpolate import lagrange #导入拉格朗日插值函数 data = pd.read_excel('data/missing_data.xls', header = None) #读取数据 #自定义列向量插值函数 #s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5 def ployinterp_column(s, n, k=5): y = s[list(range(n-k, n)) + list(range(n+1, n+1+k))] #取数 y = y[y.notnull()] #剔除空值 return lagrange(y.index, list(y))(n) #插值并返回插值结果 #逐个元素判断是否需要插值 for i in data.columns: for j in range(len(data)): if (data[i].isnull())[j]: #如果为空即插值。 data[i][j] = ployinterp_column(data[i], j) data.to_excel('tmp/missing_data_processed.xls', header=None, index=False) #输出结果
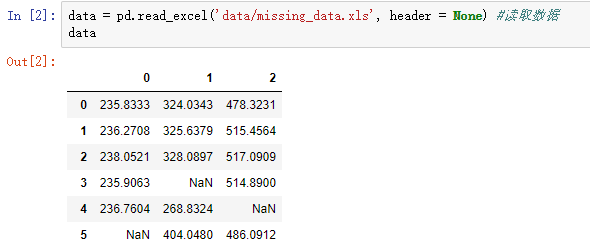
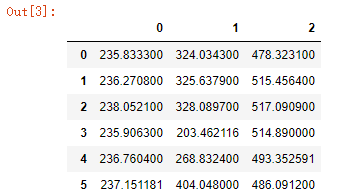
3.数据变换
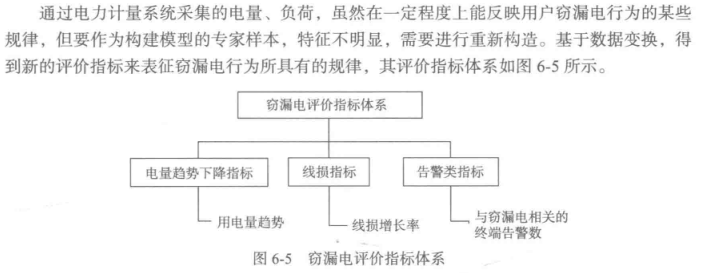
以线损指标为例,可自定义为

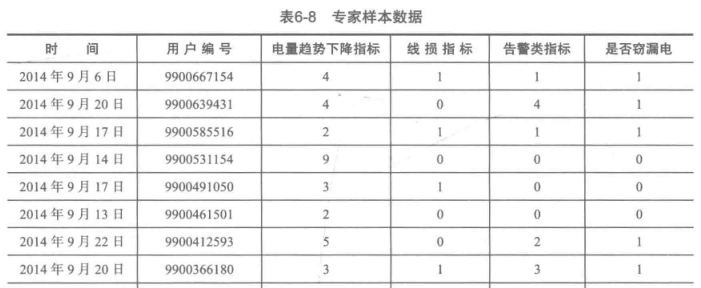
通过这种方式,将上面各种复杂繁多的数据变换为三项指标的简单数据
结果如下:
4.模型构建及模型评价
(1)LM神经网络
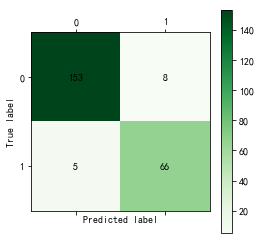
import pandas as pd from random import shuffle import matplotlib.pyplot as plt #导入作图库 from keras.models import Sequential #导入神经网络初始化函数 from keras.layers.core import Dense, Activation #导入神经网络层函数、激活函数 from sklearn.metrics import roc_curve #导入ROC曲线函数 from sklearn.metrics import confusion_matrix #导入混淆矩阵函数 def cm_plot(y, yp): cm = confusion_matrix(y, yp) #混淆矩阵 plt.matshow(cm, cmap=plt.cm.Greens) #画混淆矩阵图,配色风格使用cm.Greens,更多风格请参考官网。 plt.colorbar() #颜色标签 for x in range(len(cm)): #数据标签 for y in range(len(cm)): plt.annotate(cm[x,y], xy=(x, y), horizontalalignment='center', verticalalignment='center') plt.ylabel('True label') #坐标轴标签 plt.xlabel('Predicted label') #坐标轴标签 return plt data = pd.read_excel('data/model.xls') data = data.as_matrix() shuffle(data) p = 0.8 #设置训练数据比例 train = data[:int(len(data)*p),:] test = data[int(len(data)*p):,:] #构建LM神经网络模型 net = Sequential() #建立神经网络 net.add(Dense(input_dim = 3, output_dim = 10)) #添加输入层(3节点)到隐藏层(10节点)的连接 net.add(Activation('relu')) #隐藏层使用relu激活函数 net.add(Dense(input_dim = 10, output_dim = 1)) #添加隐藏层(10节点)到输出层(1节点)的连接 net.add(Activation('sigmoid')) #输出层使用sigmoid激活函数 net.compile(loss = 'binary_crossentropy', optimizer = 'adam') #编译模型,使用adam方法求解 net.fit(train[:,:3], train[:,3], nb_epoch=1000, batch_size=1) #训练模型,循环1000次 net.save_weights('tmp/net.model') #保存模型 predict_result = net.predict_classes(train[:,:3]).reshape(len(train)) #预测结果变形 '''这里要提醒的是,keras用predict给出预测概率,predict_classes才是给出预测类别,而且两者的预测结果都是n x 1维数组,而不是通常的 1 x n''' cm_plot(train[:,3], predict_result).show() #显示混淆矩阵可视化结果 predict_result = net.predict(test[:,:3]).reshape(len(test)) fpr, tpr, thresholds = roc_curve(test[:,3], predict_result, pos_label=1) plt.plot(fpr, tpr, linewidth=2, label = 'ROC of LM') #作出ROC曲线 plt.xlabel('False Positive Rate') #坐标轴标签 plt.ylabel('True Positive Rate') #坐标轴标签 plt.ylim(0,1.05) #边界范围 plt.xlim(0,1.05) #边界范围 plt.legend(loc=4) #图例 plt.show() #显示作图结果

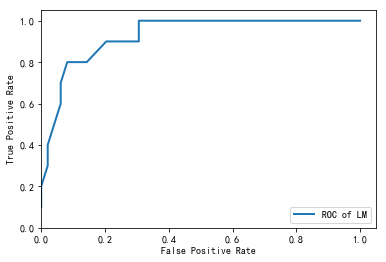
(2)CART决策树
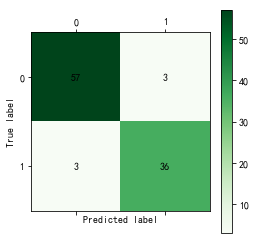
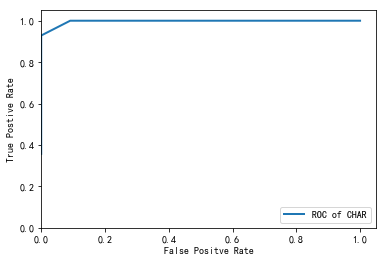
#构建并测试CART决策树模型 import pandas as pd import matplotlib.pyplot as plt #导入作图库 from random import shuffle from sklearn.tree import DecisionTreeClassifier #导入决策树模型 from sklearn.metrics import roc_curve #导入ROC曲线函数 from sklearn.metrics import confusion_matrix #导入混淆矩阵函数 def cm_plot(y, yp): cm = confusion_matrix(y, yp) #混淆矩阵 plt.matshow(cm, cmap=plt.cm.Greens) #画混淆矩阵图,配色风格使用cm.Greens,更多风格请参考官网。 plt.colorbar() #颜色标签 for x in range(len(cm)): #数据标签 for y in range(len(cm)): plt.annotate(cm[x,y], xy=(x, y), horizontalalignment='center', verticalalignment='center') plt.ylabel('True label') #坐标轴标签 plt.xlabel('Predicted label') #坐标轴标签 return plt data = pd.read_excel('data/model.xls') data = data.as_matrix() shuffle(data) p = 0.8 #设置训练数据比例 train = data[:int(len(data)*p),:] #前80%为训练集 test = data[int(len(data)*p):,:] #后20%为测试集 #构建CART决策树模型 tree = DecisionTreeClassifier() #建立决策树模型 tree.fit(train[:,:3], train[:,3]) #训练 #保存模型 from sklearn.externals import joblib joblib.dump(tree, 'tmp/tree.pkl') cm_plot(train[:,3], tree.predict(train[:,:3])).show() #显示混淆矩阵可视化结果 #注意到Scikit-Learn使用predict方法直接给出预测结果。 fpr, tpr, thresholds = roc_curve(test[:,3], tree.predict_proba(test[:,:3])[:,1], pos_label=1) plt.plot(fpr, tpr, linewidth=2, label = 'ROC of CART', color = 'green') #作出ROC曲线 plt.xlabel('False Positive Rate') #坐标轴标签 plt.ylabel('True Positive Rate') #坐标轴标签 plt.ylim(0,1.05) #边界范围 plt.xlim(0,1.05) #边界范围 plt.legend(loc=4) #图例 plt.show() #显示作图结果

三、【拓展思考】汽车行业偷漏税行为识别
参考自 https://www.jianshu.com/p/5dbb818cd7b5
1、背景和目标
企业做假账偷税漏税的行为普遍存在,汽车行业通过“多开发票”、“做双份报表”、“减少支出”等方式进行偷漏税。随着企业偷漏税现在泛滥,也影响国家经济基础。通过数据挖掘能自动识别企业偷漏税行为,提高稽查效率减少经济损失。
汽车销售行业在税收上存在少开发票金额、少记收入,上牌、按揭、保险不入账,不及时确认保修索赔款等情况,导致政府损失大量税收。汽车销售企业的部分经营指标数据能在一定程度上评估企业的偷漏税倾向。样本数据提供了汽车销售行业纳税人的各种属性和是否偷漏税标识,提取纳税人经营特征可以建立偷漏税行为识别模型。
2、分析过程
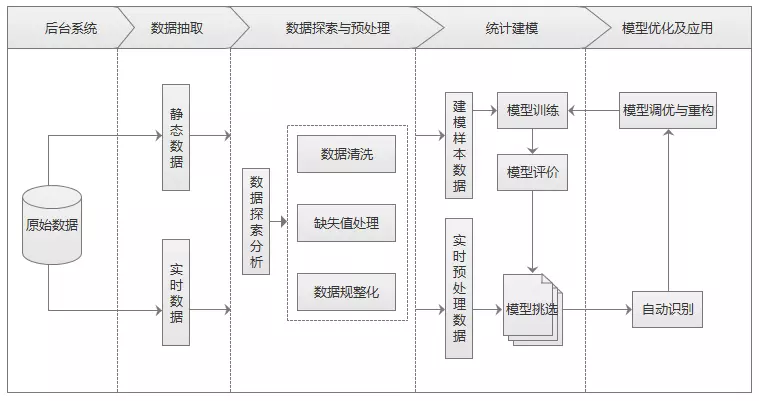
- 从后台业务系统抽取企业经营指标静态数据,保证建模样本数据稳定性。
- 对样本数据进行探索性分析,查看指标分布情况。
- 对样本数据进行预处理,包括数据集清洗、缺失值处理和数据规则化。
- 选取特征建立样本集和测试集。
- 构建识别模型对样本数据进行模型训练,并对模型进行评价。
- 使用多种模型并挑选最优模型进行自动识别。
2.EDA
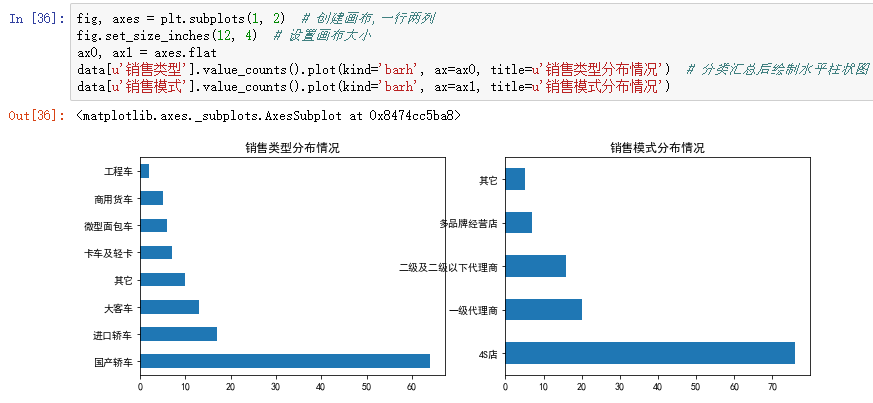
3.数据预处理

4.构建模型
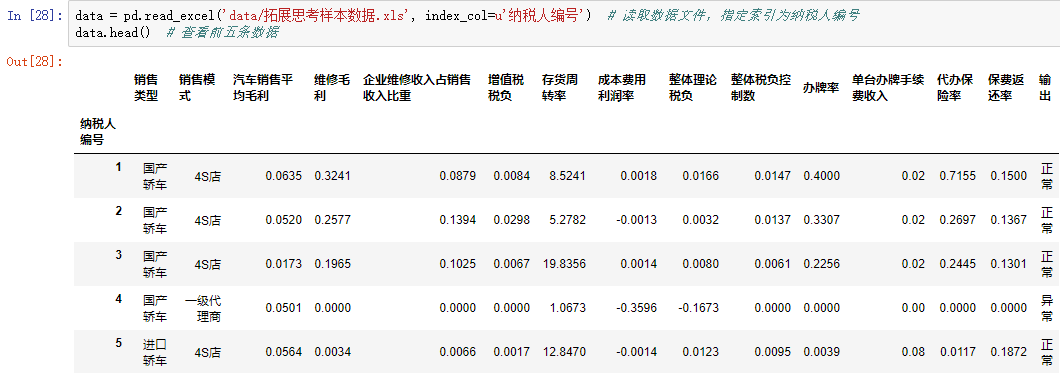
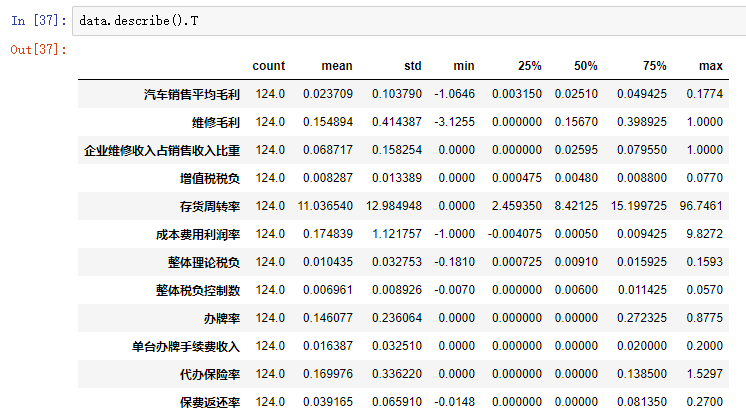
import numpy as np import matplotlib.pyplot as plt import pandas as pd from sklearn.cross_validation import train_test_split from sklearn.metrics import roc_curve # 导入ROC曲线函数 %matplotlib inline plt.rcParams['axes.unicode_minus']=False #正常显示负号 #定义混淆矩阵绘图函数 def cm_plot(y, yp): cm = confusion_matrix(y, yp) #混淆矩阵 plt.matshow(cm, cmap=plt.cm.Greens) #画混淆矩阵图,配色风格使用cm.Greens,更多风格请参考官网。 plt.colorbar() #颜色标签 for x in range(len(cm)): #数据标签 for y in range(len(cm)): plt.annotate(cm[x,y], xy=(x, y), horizontalalignment='center', verticalalignment='center') plt.ylabel('True label') #坐标轴标签 plt.xlabel('Predicted label') #坐标轴标签 return plt data = pd.read_excel('data/拓展思考样本数据.xls', index_col=u'纳税人编号') # 读取数据文件,指定索引为纳税人编号 #查看销售类型和销售模式的分布情况 fig, axes = plt.subplots(1, 2) # 创建画布,一行两列 fig.set_size_inches(12, 4) # 设置画布大小 ax0, ax1 = axes.flat data[u'销售类型'].value_counts().plot(kind='barh', ax=ax0, title=u'销售类型分布情况') # 分类汇总后绘制水平柱状图 data[u'销售模式'].value_counts().plot(kind='barh', ax=ax1, title=u'销售模式分布情况') #数据变换:将分类型数据转换成数值型数据,方便建模 data[u'输出'] = data[u'输出'].map({u'正常': 0, u'异常': 1}) data[u'销售类型'] = data[u'销售类型'].map({u'国产轿车': 1, u'进口轿车': 2, u'大客车': 3,u'卡车及轻卡': 4, u'微型面包车': 5, u'商用货车': 6,u'工程车': 7, u'其它': 8}) data[u'销售模式'] = data[u'销售模式'].map({u'4S店': 1, u'一级代理商': 2, u'二级及二级以下代理商': 3,u'多品牌经营店': 4, u'其它': 5}) p = 0.2 # 设置训练数据比例 data = data.as_matrix() # 将数据转化为矩阵 train_x, test_x, train_y, test_y = train_test_split(data[:, :14], data[:, 14], test_size=p) # 设置20%的数据为测试集,其余的为训练集 #Model1:LM神经网络 from keras.models import Sequential # 导入神经网络初始函数 from keras.layers.core import Dense, Activation # 导入神经网络网络层函数及激活函数 net = Sequential() #建立神经网络 net.add(Dense(input_dim = 14, output_dim = 10)) #添加输入层(14节点)到隐藏层(10节点)的连接 net.add(Activation('relu')) #隐藏层使用relu激活函数 net.add(Dense(input_dim = 10, output_dim = 1)) #添加隐藏层(10节点)到输出层(1节点)的连接 net.add(Activation('sigmoid')) #输出层使用sigmoid激活函数 net.compile(loss = 'binary_crossentropy', optimizer = 'adam') #编译模型,使用adam方法求解 net.fit(train_x, train_y, nb_epoch=1000, batch_size=10) #训练模型,循环1000次 net.save_weights('tmp/car_lm.model') #保存模型 predict_result_train = net.predict_classes(train_x).reshape(len(train_x)) # 预测结果 cm_plot(train_y, predict_result_train).show() # 显示混淆矩阵可视化图 #LM模型评估 predict_result = net.predict(test_x).reshape(len(test_x)) # 预测结果 fpr, tpr, thresholds = roc_curve(test_y, predict_result, pos_label=1) plt.plot(fpr, tpr, linewidth=2, label='ROC of LM') # 绘制ROC曲线 plt.xlabel('False Positive Rate') # 坐标轴标签 plt.ylabel('True POstive Rate') plt.xlim(0, 1.05) # 设定边界范围 plt.ylim(0, 1.05) plt.legend(loc=4) # 设定图例位置 plt.show() # 显示绘图结果 #Model2:CART决策树 from sklearn.tree import DecisionTreeClassifier # 导入决策树模型 from sklearn.externals import joblib tree = DecisionTreeClassifier(criterion='entropy', max_depth=3) # 建立决策树模型 tree.fit(train_x, train_y) # 训练模型 joblib.dump(tree, 'car_tree.pkl') # 保存模型 cm_plot(train_y, tree.predict(train_x)).show() # 显示混淆矩阵可视化图 # 绘制决策树模型的ROC曲线 fpr, tpr, thresholds = roc_curve(test_y, tree.predict_proba(test_x)[:,1], pos_label=1) plt.plot(fpr, tpr, linewidth=2, label='ROC of CHAR') # 绘制ROC曲线 plt.xlabel('False Positve Rate') # 坐标轴标签 plt.ylabel('True Postive Rate') plt.xlim(0, 1.05) # 设定边界范围 plt.ylim(0, 1.05) plt.legend(loc=4) # 设定图例位置 plt.show() # 显示绘图结果
LM结果如下
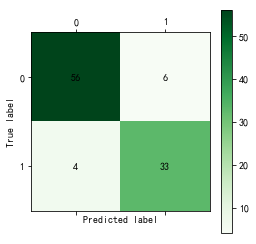
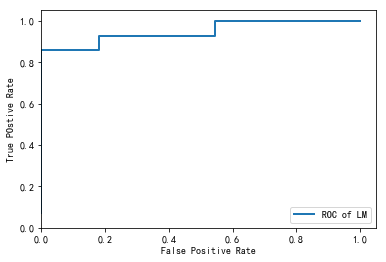
决策树结果如下