一.一篇文档的信息量是否丰富,可以简单利用信息熵来衡量它,计算公式如下,其中p(x)表示word在整篇文档的出现概率(此word出现次数 / 总词数)。
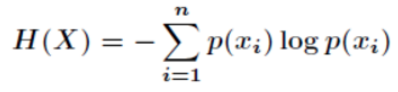
二.简单实现
public class DocEntropy { public static void main(String[] args) { DocEntropy docEntropy = new DocEntropy(); String doc = " 2019年10月21日外交部发言人华春莹主持例行记者会 问:第一,美国驻华大使表示," + "目前美国已对华实施“对等措施”,希望中国政府放松对美外交官会见中国地方官员的限制"; System.out.println(docEntropy.entropyCal(doc)); } /** * 熵 * @param doc * @return */ public double entropyCal(String doc) { List<String> wordsList = SegmentUtil.IKSegment(doc); Map<String, Long> wordCount = wordsList .stream() .collect(Collectors.groupingBy(Function.identity(), Collectors.counting())); long wordTotalCount = wordCount .values() .stream() .mapToLong(word -> word.longValue()) .sum(); double docEntropy = wordCount .entrySet() .stream() .mapToDouble(word -> { double pWord = 1.0 * word.getValue() / wordTotalCount; return - (pWord * Math.log(pWord)); }) .reduce(0, Double :: sum); return docEntropy; } }
public class SegmentUtil { static Set<String> stopWords = CollectionUtil.newHashset(); /** * load stop words * @param path */ private static void loadStopWords(String path) { path = PropertiesReader.class.getClassLoader().getResource(path).getFile(); try(BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(path),"utf-8"))){ String line; while((line = br.readLine()) != null){ stopWords.add(line); } }catch(IOException e){ e.printStackTrace(); } } /** * segment words * @param text * @return */ public static List<String> IKSegment(String text){ List<String> wordList = CollectionUtil.newArrayList(); Reader reader = new StringReader(text); IKSegmenter ik = new IKSegmenter(reader,true); Lexeme lex = null; try { while((lex = ik.next()) != null){ String word = lex.getLexemeText(); if(word.equals("nbsp") || stopWords.contains(word)) { continue; } if(word.length() > 1 && word != " ") { wordList.add(word); } } } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } return wordList; // return wordList.stream().map(String::trim).filter(w -> !w.isEmpty()).collect(Collectors.toList()); } static { loadStopWords(PropertiesReader.get("stopword_dic")); } }