一.简单介绍
此模型是对Convolutional Sequence to Sequence Learning中的encoder部分进行的改进。
原模型是用于机器翻译,这里我将稍加修改用来做问答中的slot filling和intent detection联合建模。
整体修改主要有以下几点:
1.使用多个size的卷积核进行多特征提取。
2.加入了多头attention进行特征提取。
3.增加了池化。
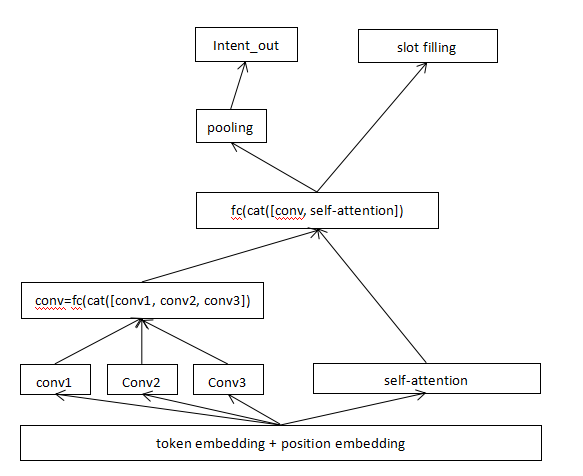
说明:
1.句子token和其对应的position进行embedding。
2.embedding进入几个不同size卷积核,这时是3个。将这些卷积后的特征进行拼接。
3.embedding进入一个多头attention层。
4.以上2,3的输出进行拼接。
5.经过一层池化后进行意图识别。
6.直接槽识别。
原模型的encoder的部分可参考:https://www.cnblogs.com/little-horse/p/14462023.html
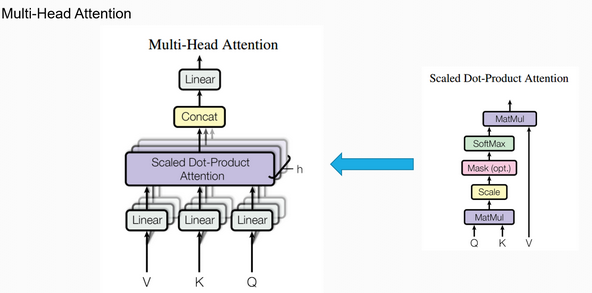
multi-head attention部分:
二.代码
完整项目见:(https://github.com/jiangnanboy/intent_detection_and_slot_filling/blob/master/model5)
''' 这里将卷积后的特征与经过多头注意力后的特征进行融合 ''' class CNNAttention(nn.Module): def __init__(self, input_dim, intent_out, slot_out, hid_dim, n_layers, kernel_size, dropout, src_pad_idx, n_heads, max_length=50): super(CNNAttention, self).__init__() for kernel in kernel_size: assert kernel % 2 == 1,'kernel size must be odd!' # 卷积核size为奇数,方便序列两边pad处理 self.src_pad_idx = src_pad_idx self.scale = torch.sqrt(torch.FloatTensor([0.5])).to(device) # 确保整个网络的方差不会发生显著变化 self.tok_embedding = nn.Embedding(input_dim, hid_dim) # token编码 self.pos_embedding = nn.Embedding(max_length, hid_dim) # token的位置编码 self.hid2hid = nn.Linear(hid_dim * 2, hid_dim) # 线性层,从2 * hid_dim转为hid_dim # 不同的kernel_size self.conv_1 = nn.ModuleList([nn.Conv1d(in_channels=hid_dim, out_channels=2*hid_dim, # 卷积后输出的维度,这里2*hid_dim是为了后面的glu激活函数 kernel_size=kernel_size[0], padding=(kernel_size[0] - 1)//2) # 序列两边补0个数,保持维度不变 for _ in range(n_layers)]) self.conv_2 = nn.ModuleList([nn.Conv1d(in_channels=hid_dim, out_channels=2*hid_dim, # 卷积后输出的维度,这里2*hid_dim是为了后面的glu激活函数 kernel_size=kernel_size[1], padding=(kernel_size[1] - 1)//2) # 序列两边补0个数,保持维度不变 for _ in range(n_layers)]) self.conv_3 = nn.ModuleList([nn.Conv1d(in_channels=hid_dim, out_channels=2*hid_dim, # 卷积后输出的维度,这里2*hid_dim是为了后面的glu激活函数 kernel_size=kernel_size[2], padding=(kernel_size[2] - 1)//2) # 序列两边补0个数,保持维度不变 for _ in range(n_layers)]) # 几个卷积模块转换维度 self.convhid2hid = nn.Linear(len(kernel_size) * hid_dim, hid_dim) # 多头注意力模块 self.self_attention = MultiHeadAttentionLayer(hid_dim, n_heads, dropout) self.dropout = nn.Dropout(dropout) # intent detection 意图识别 self.intent_output = nn.Linear(hid_dim, intent_out) # slot filling,槽填充 self.slot_out = nn.Linear(hid_dim, slot_out) def make_src_mask(self, src): # src: [batch_size, src_len] src_mask = (src != self.src_pad_idx).unsqueeze(1).unsqueeze(2) # [batch_size, 1, 1, src_len] return src_mask def forward(self, src): # src: [batch_size, src_len] # src_mask: [batch_size, src_len] batch_size = src.shape[0] src_len = src.shape[1] src_mask = self.make_src_mask(src) # [batch_size, 1, 1, src_len] # 创建token位置信息 pos = torch.arange(src_len).unsqueeze(0).repeat(batch_size, 1).to(device) # [batch_size, src_len] # 对token与其位置进行编码 tok_embedded = self.tok_embedding(src) # [batch_size, src_len, hid_dim] pos_embedded = self.pos_embedding(pos.long()) # [batch_size, src_len, hid_dim] # 对token embedded和pos_embedded逐元素加和 embedded = self.dropout(tok_embedded + pos_embedded) # [batch_size, src_len, hid_dim] # 转变维度,卷积在输入数据的最后一维进行 conv_input = embedded.permute(0, 2, 1) # [batch_size, hid_dim, src_len] # 第一个kernel_size conved_input = conv_input for i, conv in enumerate(self.conv_1): # 进行卷积 conved1 = conv(self.dropout(conved_input)) # [batch_size, 2*hid_dim, src_len] # 进行激活glu conved1 = F.glu(conved1, dim=1) # [batch_size, hid_dim, src_len] # 进行残差连接 conved1 = (conved1 + conved_input) * self.scale # [batch_size, hid_dim, src_len] # 作为下一个卷积块的输入 conved_input = conved1 combine_conv_module = conved1 # 第二个kernel_size conved_input = conv_input for i, conv in enumerate(self.conv_2): # 进行卷积 conved2 = conv(self.dropout(conved_input)) # [batch_size, 2*hid_dim, src_len] # 进行激活glu conved2 = F.glu(conved2, dim=1) # [batch_size, hid_dim, src_len] # 进行残差连接 conved2 = (conved2 + conved_input) * self.scale # [batch_size, hid_dim, src_len] # 作为下一个卷积块的输入 conved_input = conved2 combine_conv_module = torch.cat([combine_conv_module, conved2], dim = 1) # 第三个kernel_size conved_input = conv_input for i, conv in enumerate(self.conv_3): # 进行卷积 conved3 = conv(self.dropout(conved_input)) # [batch_size, 2*hid_dim, src_len] # 进行激活glu conved3 = F.glu(conved3, dim=1) # [batch_size, hid_dim, src_len] # 进行残差连接 conved3 = (conved3 + conved_input) * self.scale # [batch_size, hid_dim, src_len] # 作为下一个卷积块的输入 conved_input = conved3 combine_conv_module = torch.cat([combine_conv_module, conved3], dim = 1) conved = self.convhid2hid(combine_conv_module.permute(0, 2, 1)) # [batch_size, src_len, hid_dim] # 这里在所有卷积之后增加了一个多头自注意力层,它的输入是 self_attention, _ = self.self_attention(embedded, embedded, embedded, src_mask) # [batch_size, query_len, hid_dim] # 拼接卷积后的特征与多头注意力后的特征 combined_conv_attention = torch.cat([conved, self_attention], dim=2) # [batch_size, query_len, 2*hid_dim] # 经过一线性层,将2*hid_dim转为hid_dim,作为输出的特征 conved = self.hid2hid(combined_conv_attention) # [batch_size, query_len, hid_dim] # 又是一个残差连接,逐元素加和输出,作为encoder的联合输出特征 combined = (conved + embedded) * self.scale # [batch_size, src_len, hid_dim] # 意图识别,加一个平均池化,池化后的维度是:[batch_size, hid_dim] intent_output = self.intent_output(self.dropout(F.max_pool1d(combined.permute(0, 2, 1), combined.shape[1]).squeeze())) # [batch_size, intent_dim] # 槽填充 slot_output = self.slot_out(self.dropout(combined)) # [batch_size, trg_len, output_dim] return intent_output, slot_output ''' 多头注意力multi-head attention ''' class MultiHeadAttentionLayer(nn.Module): def __init__(self, hid_dim, n_heads, dropout): super(MultiHeadAttentionLayer, self).__init__() assert hid_dim % n_heads == 0 self.hid_dim = hid_dim self.n_heads = n_heads self.head_dim = hid_dim // n_heads self.fc_q = nn.Linear(hid_dim, hid_dim) self.fc_k = nn.Linear(hid_dim, hid_dim) self.fc_v = nn.Linear(hid_dim, hid_dim) self.fc_o = nn.Linear(hid_dim, hid_dim) self.dropout = nn.Dropout(dropout) self.scale = torch.sqrt(torch.FloatTensor([self.hid_dim])).to(device) # 缩放因子 def forward(self, query, key, value, mask=None): ''' query: [batch_size, query_len, hid_dim] key: [batch_size, key_len, hid_dim] value: [batch_size, value_len, hid_dim] ''' batch_size = query.shape[0] Q = self.fc_q(query) # [batch_size, query_len, hid_dim] K = self.fc_k(key) # [batch_size, key_len, hid_dim] V = self.fc_v(value) # [batch_size, value_len, hid_dim] Q = Q.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3) # [batch_size, n_heads, query_len, head_dim] K = K.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3) # [batch_size, n_heads, key_len, head_dim] V = V.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3) # [batch_size, n_heads, value_len, head_dim] # [batch_size, n_heads, query_len, head_dim] * [batch_size, n_heads, head_dim, key_len] energy = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scale # [batch_size, n_heads, query_len, key_len] if mask != None: energy = energy.masked_fill(mask == 0, -1e10) attention = torch.softmax(energy, dim=-1) # [batch_size, n_heads, query_len, key_len] # [batch_size, n_heads, query_len, key_len] * [batch_size, n_heads, value_len, head_dim] x = torch.matmul(self.dropout(attention), V) # [batch_size, n_heads, query_len, head_dim] x = x.permute(0, 2, 1, 3).contiguous() # [batch_size, query_len, n_heads, head_dim] x = x.view(batch_size, -1, self.hid_dim) # [batch_size, query_len, hid_dim] x = self.fc_o(x) # [batch_size, query_len, hid_dim] return x, attention
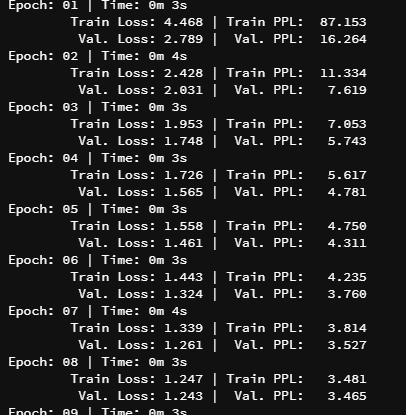
loss:
predict:
