功能主要包括实体识别、实体查询、关系查询以及问答几个模块。
项目中用到的数据来自网上公开数据集
前端页面参考:https://github.com/qq547276542/Agriculture_KnowledgeGraph,在此表示非常感谢。
准备及构建实体及关系
note:以下数据导入是在Neo4j控制台上完成,将数据data/node与data/relation放入neo4j安装目录下import文件夹下:
一.为id创建唯一索引
1.create constraint on (c:Country) assert c.id is unique
2.create constraint on (m:Movie) assert m.id is unique
3.create constraint on (p:Person) assert p.id is unique
二.为name创建索引
1.create index on :Country(name)
2.create index on :Movie(name)
3.create index on :Person(name)
三.创建node
1.Country节点
call apoc.periodic.iterate(
'call apoc.load.csv("node/Country.csv",{header:true,sep:",",ignore:["label"]}) yield map as row return row',
'create(p:Country) set p=row',
{batchSize:1000,iterateList:true, parallel:true})
2.Movie节点
call apoc.periodic.iterate(
'call apoc.load.csv("node/Movie.csv",{header:true,sep:",",ignore:["label"]}) yield map as row return row',
'create(p:Movie) set p=row',
{batchSize:1000,iterateList:true, parallel:true})
3.Person节点
call apoc.periodic.iterate(
'call apoc.load.csv("node/Person.csv",{header:true,sep:",",ignore:["label"]}) yield map as row return row',
'create(p:Person) set p=row',
{batchSize:1000,iterateList:true, parallel:true})
四.创建relation
1.关系:Movie-[:ACTOR]->Person
call apoc.periodic.iterate(
'call apoc.load.csv( "relation/actor.csv",{header:true,sep:","}) yield map as row match (start:Movie{id:row.start_id}), (end:Person{id:row.end_id}) return start,end',
'create (start)-[:ACTOR]->(end)',
{batchSize:1000,iterateList:true, parallel:false})
2.关系:Movie-[:COMPOSER]->Person
call apoc.periodic.iterate(
'call apoc.load.csv( "relation/composer.csv",{header:true,sep:","}) yield map as row match (start:Movie{id:row.start_id}), (end:Person{id:row.end_id}) return start,end',
'create (start)-[:COMPOSER]->(end)',
{batchSize:1000,iterateList:true, parallel:false})
3.关系:Movie-[:DIRECTOR]->Person
call apoc.periodic.iterate(
'call apoc.load.csv( "relation/director.csv",{header:true,sep:","}) yield map as row match (start:Movie{id:row.start_id}), (end:Person{id:row.end_id}) return start,end',
'create (start)-[:DIRECTOR]->(end)',
{batchSize:1000,iterateList:true, parallel:false})
4.关系:Movie-[:DISTRICT]->Country
call apoc.periodic.iterate(
'call apoc.load.csv( "relation/district.csv",{header:true,sep:","}) yield map as row match (start:Movie{id:row.start_id}), (end:Country{id:row.end_id}) return start,end',
'create (start)-[:DISTRICT]->(end)',
{batchSize:1000,iterateList:true, parallel:false})
五.安装pyhanlp用作分词与实体识别
1.下载hanlp模型和hanlp的jar包放在目录Anaconda3Libsite-packagespyhanlpstatic
2.在路径Anaconda3Libsite-packagespyhanlpstaticdatadictionarycustom下放以下文件(data/custom_dict/演员名.txt,data/custom_dict/电影名.txt,data/custom_dict/电影类型.txt,data/custom_dict/other.txt),当自定义词典
演员名.txt
电影名.txt
电影类型.txt
other.txt
3.修改自定义词典配制D:Anaconda3Libsite-packagespyhanlpstatichanlp.properties
CustomDictionaryPath=data/dictionary/custom/CustomDictionary.txt; 现代汉语补充词库.txt; 全国地名大全.txt ns; 人名词典.txt; 机构名词典.txt; 上海地名.txt ns; 电影类型.txt ng; 电影名.txt nm; 演员名.txt nnt; other.txt;data/dictionary/person/nrf.txt nrf;
项目结构
.
├── data
│ ── custom_dict // 常规数据
│ ── node // 电影node数据
│ ── relation // 电影relation数据
│
├── intent_classification
│ ── classification_data //意图识别训练数据
│ ── pytorch // 神经网络分类模型
│ ── scikit_learn // 传统机器学习模型
│
├── movie_kg // django项目路径
│ ├── Model // 模型层,用于和neo4j交互,实现查询等核心功能
│ ├── movie_kg // 用于写页面的逻辑(View)
│ ├── static // 静态资源
│ ├── templates // html页面
│ └── util // 包括预加载一些数据和模型
.
功能模块
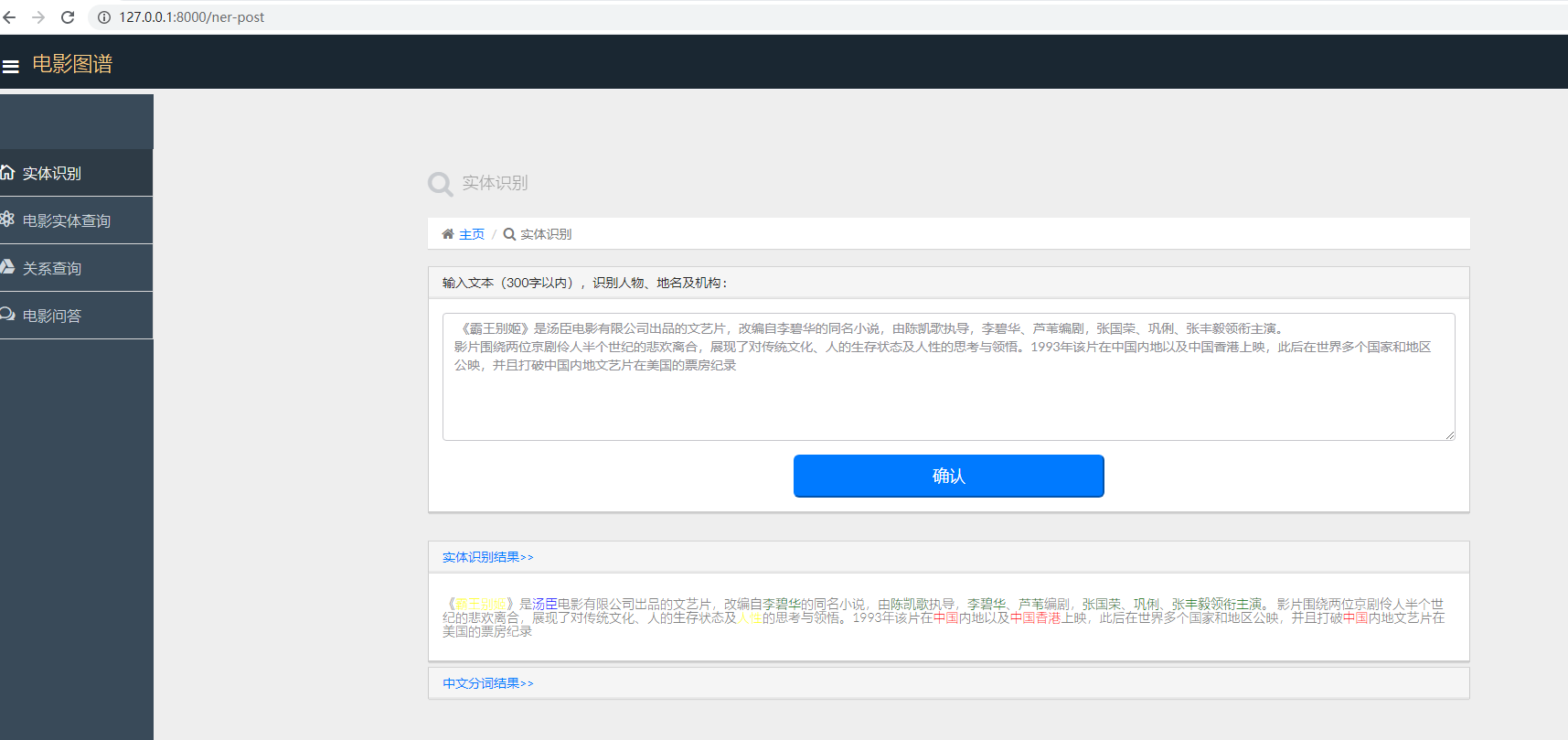
一.实体实别
主要识别人物、地名、机构、电影名以及明星名
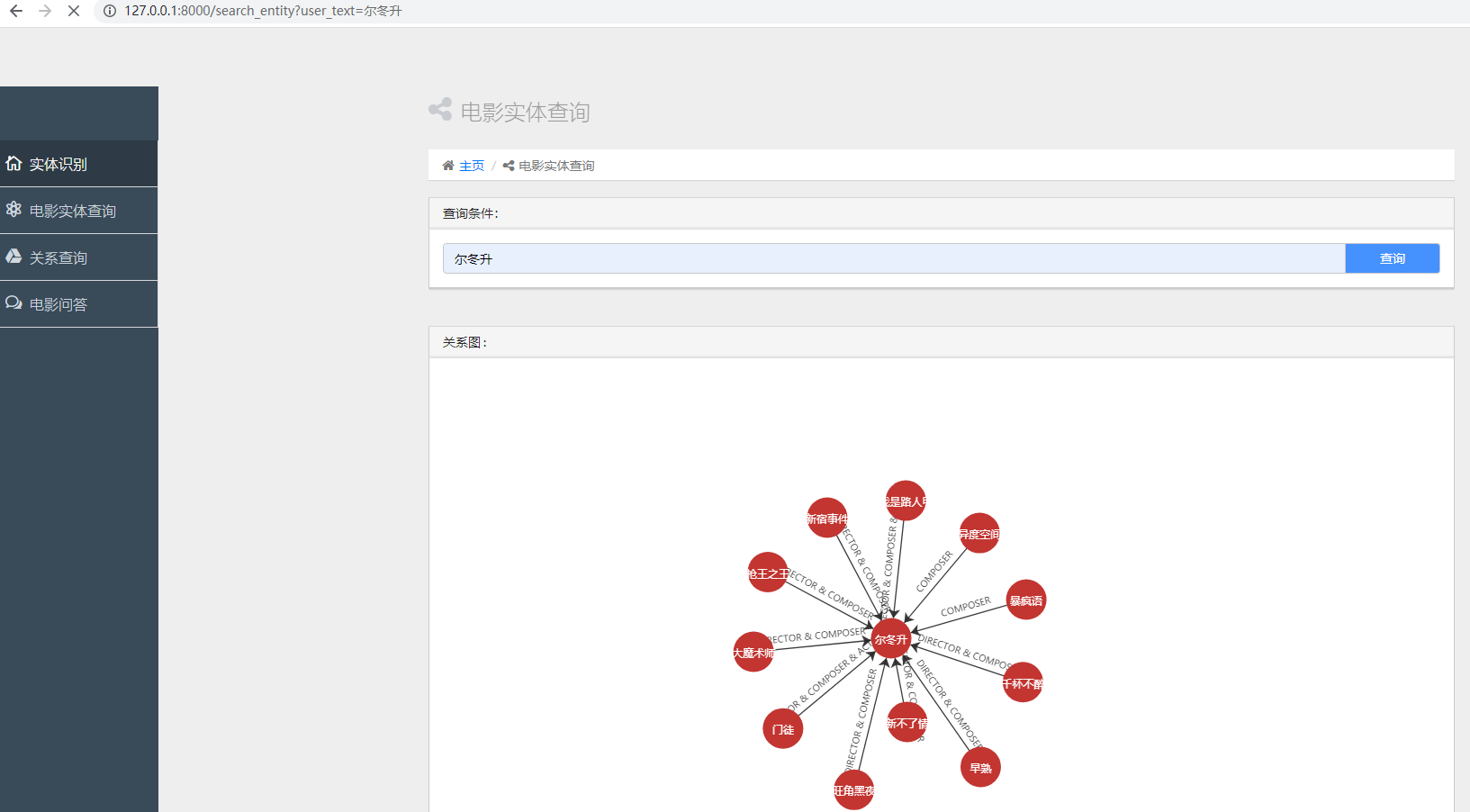
二.实体查询
输入电影名或演员名会图谱化展示直接关系
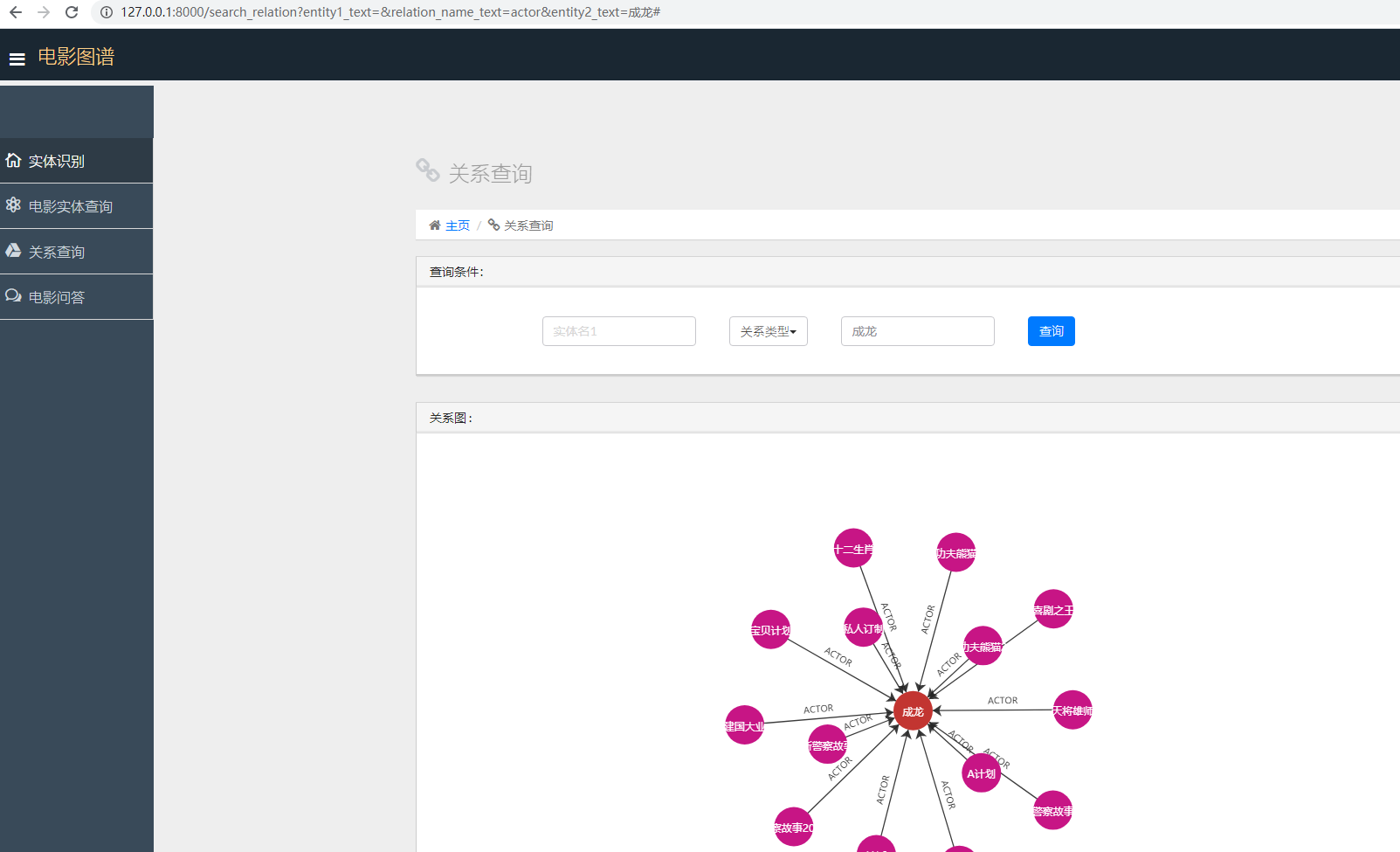
三.关系查询
4种主要实体关系:actor、composer、director、district
可以选择不同的关系类型,输入电影名或演员名,给个图谱展示
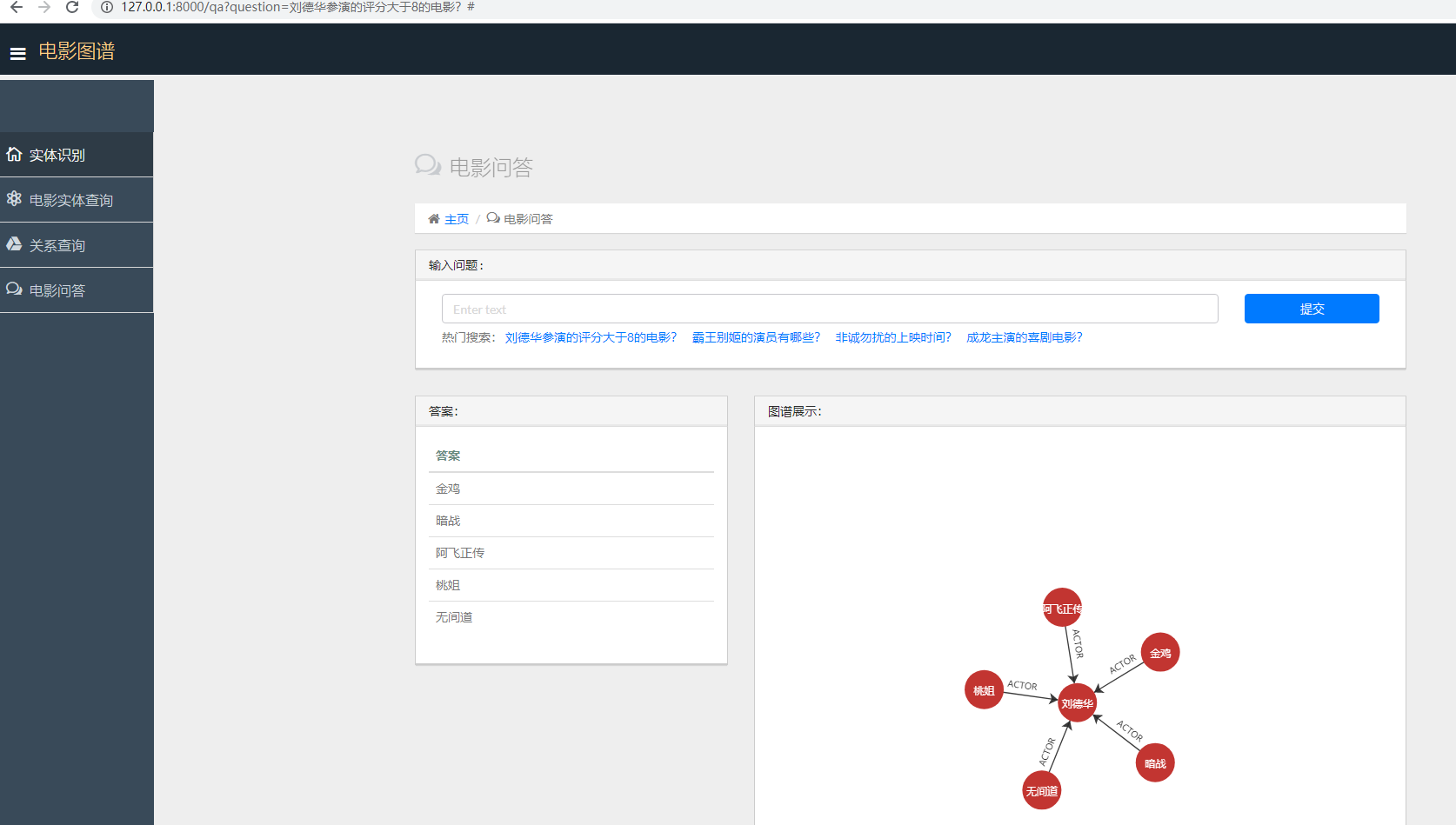
四.电影问答
1.利用分类模型对用户输入的问题进行意图识别
(1).训练数据在目录 intent_classificationclassification_dataclassification_segment_data.txt
(2).总共16个意图类别,见目录 intent_classificationclassification_dataquestion_classification.txt
(3).分类模型有很多,这里使用pytorch中的前馈网络进行分类训练
训练代码:intent_classificationpytorchfeedforward_network rain.ipynb
预测代码:intent_classificationpytorchfeedforward_networkpredict.ipynb
2.将识别的意图转为cypher语言,在neo4j中进行查询得到答案
利用分类模型预测用户提问的意图类别,将不同的意图类别转换为不同的cypher语言,从neo4j中查询得到答案。
后续......
1.利用pytorch的深度模型做实体识别
2.增加更多训练数据,尝试利用其它深度模型作意图识别,如textcnn,bert等
3.增加一个页面,给一篇关于电影的新闻,利用深度模型自动抽取实体和关系,并图谱化展示
4.增加多轮对话功能
5.增加闲聊功能
...
作者的qq,如您有什么想法可以和作者联系:2229029156
如果您支持作者继续开发更加完善的功能,请动一动手为此项目打个星吧或fork此项目,这是对作者最大的鼓励
完整项目见:https://github.com/jiangnanboy/movie_knowledge_graph_app