一.简单总结
其实相似度计算方法也是老生常谈,比如常用的有:
1.常规方法
a.编辑距离
b.Jaccard
c.余弦距离
d.曼哈顿距离
e.欧氏距离
f.皮尔逊相关系数
2.语义方法
a.LSA
b.Doc2Vec
c.DSSM
......
二.利用熵计算相似度
关于什么是熵、相对熵、交叉熵的概念,网上有很多,这里就不总结了。本篇主要关注工程方面,即怎么用代码实现,参考的论文来自《Content-based relevance estimation on the web using inter-document similarities》(2012-CIKM)。
利用熵计算query与文档相似度并排序的步骤分为召回和重排序,比如先从大规模文档中召回小部分子集再进行重排序。召回部分可以用一些简单的效率高的方法快速确定候选子集,再将这些子集进行重排序。本篇关注如何利用熵重排序相关文档。
召回后的排序公式如下:
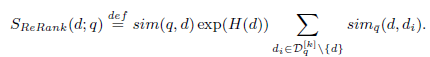
说明:
(1).H(d)表示文档d的熵
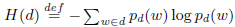
其中 =|w|/|d|,分子是词w个数,分母为文档d中的总词数
=|w|/|d|,分子是词w个数,分母为文档d中的总词数
(2).文档间的相似度

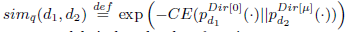
其中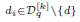 表示query的top-k个相关文档;利用交叉熵
表示query的top-k个相关文档;利用交叉熵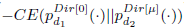 计算文档间的相似度,这里面的文档去除了query中的词。
计算文档间的相似度,这里面的文档去除了query中的词。
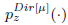 表示语言模型Dirichlet-smoothed,常见的平滑方法如下:
表示语言模型Dirichlet-smoothed,常见的平滑方法如下:

其中Dirichlet 方法:
a.首先计算最基本的最大的似然估计w|d 单词在单个文档出现的频率(有可能为0,所以就需要平滑,将所有f(w|d1), f(w|d2)....f(w|dn) 的所有频率加总
b.设定u值,根据实证研究: Dirichlet 方法的u值在100-200之间是最理想 ,但论文中给出的是1000,0为不使用平滑
c. 计算P(w|C)的概率
(3).sim(q,d)表示query与doc的相似度,可以使用其它方法计算,也可以使用如(2)中的方法计算
三.程序
完整程序https://github.com/jiangnanboy/entropy_sim
核心程序:
1 /** 2 * 结合交叉熵和狄里克雷平滑语言方法计算相关度 3 * @param queryTerms 4 * @return 5 */ 6 private Map<String, Double> queryDocScore(List<String> queryTerms) { 7 //统计查询中的词频 8 Map<String, Long> queryTermsCount = queryTerms 9 .stream() 10 .collect(Collectors.groupingBy(Function.identity(), Collectors.counting())); 11 //查询中的总词频 12 long queryTermsSize = queryTermsCount 13 .values() 14 .stream() 15 .mapToLong(word -> word) 16 .sum(); 17 18 //文档集中的词频 19 Map<String, Long> collectionTermsCount = corpusTerms 20 .stream() 21 .collect(Collectors.groupingBy(Function.identity(), Collectors.counting())); 22 //文档集中的总词频 23 long collectionTermsSize = collectionTermsCount 24 .values() 25 .stream() 26 .mapToLong(word -> word) 27 .sum(); 28 29 Map<String, Double> scoredDocument = new HashMap<>(); 30 documentList.forEach(docTerms -> { 31 //文档中的词频 32 Map<String, Long> docTermsCount = docTerms 33 .stream() 34 .collect(Collectors.groupingBy(Function.identity(), Collectors.counting())); 35 //文档中的总词频 36 long docTermsSize = docTermsCount 37 .values() 38 .stream() 39 .mapToLong(word -> word) 40 .sum(); 41 42 //计算交叉熵(或者相对熵) 43 OptionalDouble score = queryTerms 44 .stream() 45 .mapToDouble(queryTerm -> { 46 //queryTerm的似然 47 double queryCE = (double)queryTermsCount.get(queryTerm) / queryTermsSize; 48 //经过Dirichlet smooth的term weight 49 double docCE = (1.0 + docTermsCount.getOrDefault(queryTerm, 0L) + 50 this.lambda * (collectionTermsCount.getOrDefault(queryTerm, 0L) / collectionTermsSize)) / 51 (docTermsSize + this.lambda); 52 return queryCE * Math.log(1 / docCE);//交叉熵 53 //return queryCE * Math.log(queryCE / docCE);//相对熵 54 }) 55 .reduce(Double::sum); 56 String docID = corpusHashMap.get(docTerms); 57 scoredDocument.put(docID, Math.exp(-score.getAsDouble())); 58 }); 59 return scoredDocument; 60 }