以下代码对鲁迅的《祝福》进行了词频统计:
1 import io 2 import jieba 3 txt = io.open("zhufu.txt", "r", encoding='utf-8').read() 4 words = jieba.lcut(txt) 5 counts = {} 6 for word in words: 7 if len(word) == 1: 8 continue 9 else: 10 counts[word] = counts.get(word,0) + 1 11 items = list(counts.items()) 12 items.sort(key=lambda x:x[1], reverse=True) 13 for i in range(15): 14 word, count = items[i] 15 print (u"{0:<10}{1:>5}".format(word, count))
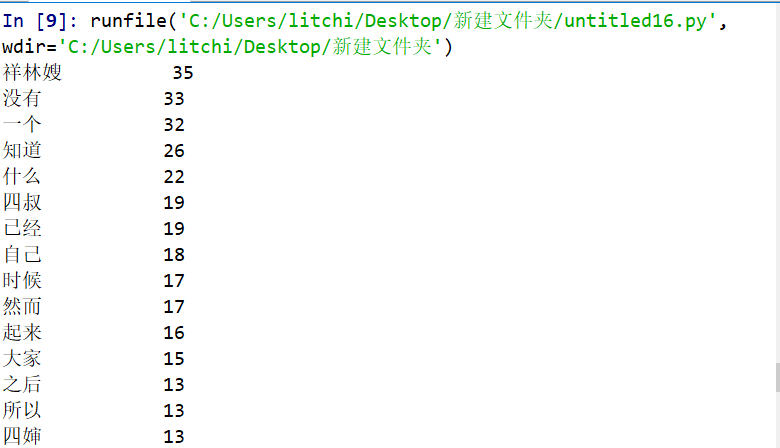
结果如下:
并把它生成词云
1 from wordcloud import WordCloud 2 import PIL.Image as image 3 import numpy as np 4 import jieba 5 6 # 分词 7 def trans_CN(text): 8 # 接收分词的字符串 9 word_list = jieba.cut(text) 10 # 分词后在单独个体之间加上空格 11 result = " ".join(word_list) 12 return result 13 14 with open("zhufu.txt") as fp: 15 text = fp.read() 16 # print(text) 17 # 将读取的中文文档进行分词 18 text = trans_CN(text) 19 mask = np.array(image.open("xinxing.jpg")) 20 wordcloud = WordCloud( 21 # 添加遮罩层 22 mask=mask, 23 font_path = "msyh.ttc" 24 ).generate(text) 25 image_produce = wordcloud.to_image() 26 image_produce.show()
效果如下:
