字符编码
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。
由于计算机是美国人发明的,因此,最早只有127个字母被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
现在英文和中文问题被解决了,但新的问题又出现了。全球有那么多的国家不仅有英文、中文还有阿拉伯语、西班牙语、日语、韩语等等。难不成每种语言都做一种编码?基于这种情况一种新的编码诞生了:Unicode。Unicode又被称为统一码、万国码;它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。Unicode支持欧洲、非洲、中东、亚洲(包括统一标准的东亚象形汉字和韩国表音文字)。这样不管你使用的是英文或者中文,日语或者韩语,在Unicode编码中都有收录,且对应唯一的二进制编码。这样大家都开心了,只要大家都用Unicode编码,那就不存在这些转码的问题了,什么样的字符都能够解析了。
由于Unicode收录了更多的字符,可想而知它的解析效率相比ASCII码和GB2312的速度要大大降低,而且由于Unicode通过增加一个高字节对ISO Latin-1字符集进行扩展,当这些高字节位为0时,低字节就是ISO Latin-1字符。对可以用ASCII表示的字符使用Unicode并不高效,因为Unicode比ASCII占用大一倍的空间,而对ASCII来说高字节的0对他毫无用处。为了解决这个问题,就出现了一些中间格式的字符集,他们被称为通用转换格式,即UTF(Unicode Transformation Format)。而我们最常用的UTF-8就是这些转换格式中的一种。在这里我们不去研究UTF-8到底是如何提高效率的,你只需要知道他们之间的关系即可。
总结:
1、为了处理英文字符,产生了ASCII码。
2、为了处理中文字符,产生了GB2312。
3、为了处理各国字符,产生了Unicode。
4、为了提高Unicode存储和传输性能,产生了UTF-8,它是Unicode的一种实现形式。
Python2的默认编码是ASCII码,Python3的默认编码是UTF-8
一、python2 与 python3 通用的编码方式
1、UTF-8编码方式:
英文 :A 00100000 8位 1字节
中文: 中 00000001 00000010 00001110 24位 3字节
2、GBK编码方式:
英文: A 00000110 8位 1字节
中文: 中 00000010 00000110 16位 2字节
各个编码之间二进制,是不能互相识别的,会产生混乱
文件之间的储存、传输、不能用Unicode码(因为所占用的空间太大),只能用UTF-8、UTF-16、GBK、GB2312、ASCII码
3、str在Python中是用Unicode码,还有一种是bytes 类型
1、英文
str:
表现形式 s = 'alex'
编码方式 0101010101 unicode
bytes:
表现形式 s = b'alex'
编码方式 00101010 utf-8 gbk
2、中文
str:
表现方式 s= '中国'
编码方式 01010110 utf-8 gbk
bytes:
表现方式 b'xe91e91e01e21e31e32
编码方式 01001100 utf-8 gbk
二、字符编码的使用
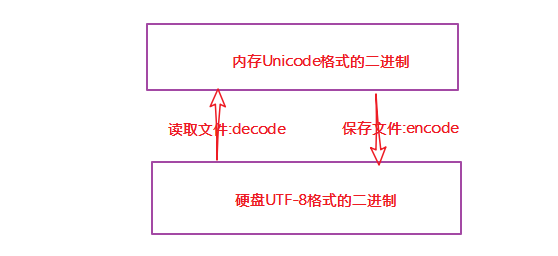
不管是哪种类型的文件,只要记住一点:文件以什么编码保存的,就以什么编码方式打开。
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
总结:
decode()方法将其他编码字符转化为Unicode编码字符。
encode()方法将Unicode编码字符转化为其他编码字符。