循环神经网络
RNN
全连接网络处理图像的问题:
- 参数太多:权重矩阵的参数太多(longrightarrow)过拟合
卷积神经网络的解决方式
- 局部关联,参数共享
基本应用:
- 语音问答 2. 股票预测 3. 作词作诗 4. 图像理解 5. 视觉问答
循环神经网络和卷积神经网络的不同是什么?
- 传统神经网络,卷积神经网络,输入和输出之间是相互独立的
- RNN可以更好的处理具有时序关系的任务
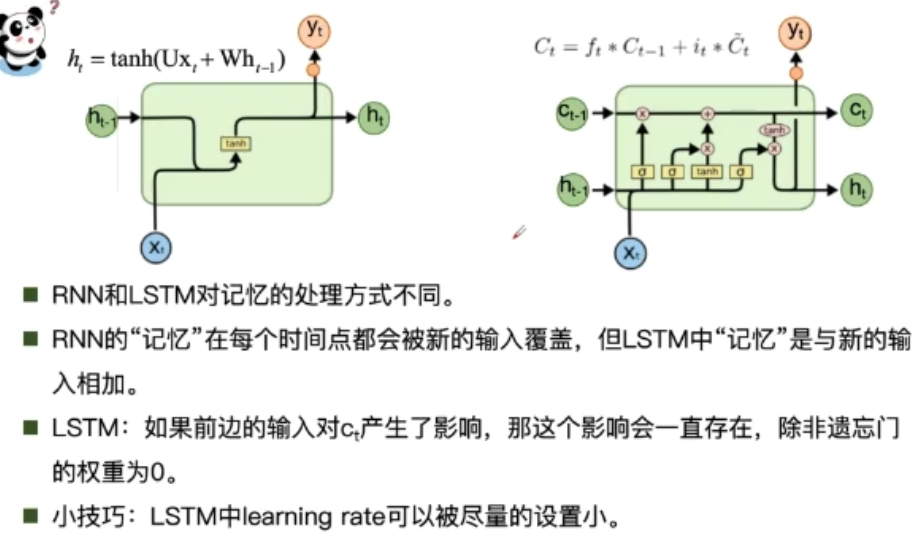
- RNN通过其循环结构引入“记忆”的
RNN的基本结构
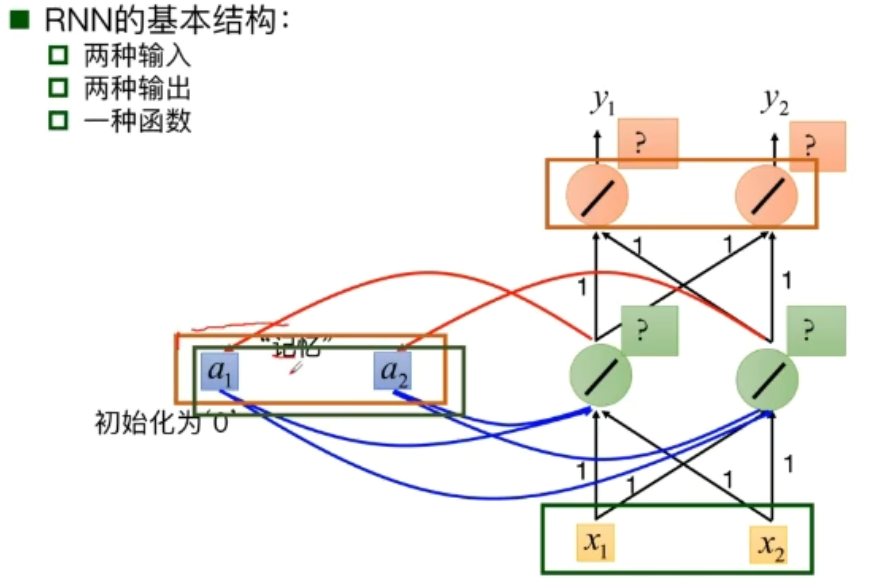
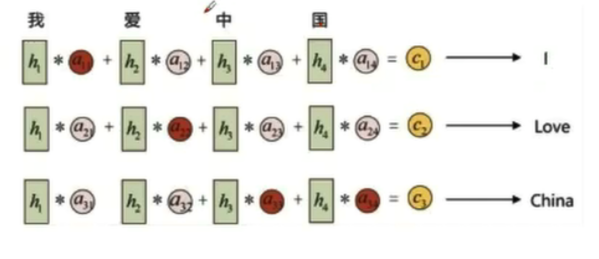
三块参数

展开
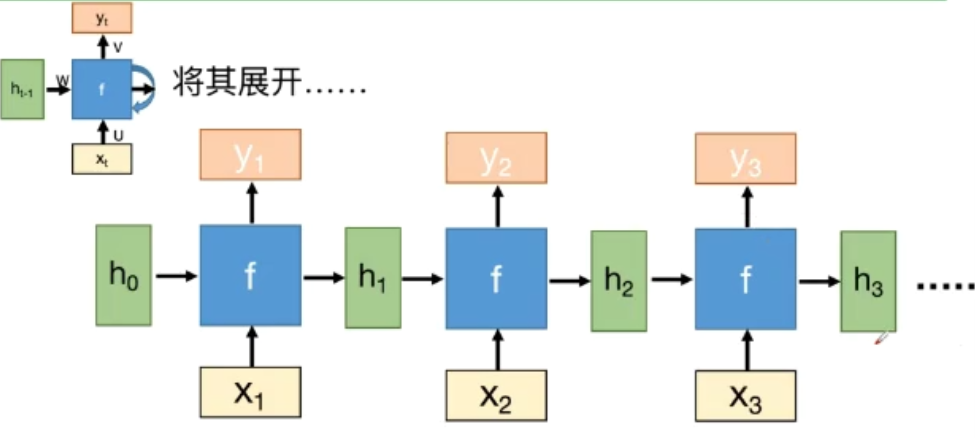
- f被不断的重复利用
- 模型所需要学习的参数是固定的
- 无论输入的长度是多少,只需要一个函数f
深度RNN(在深度上延伸)
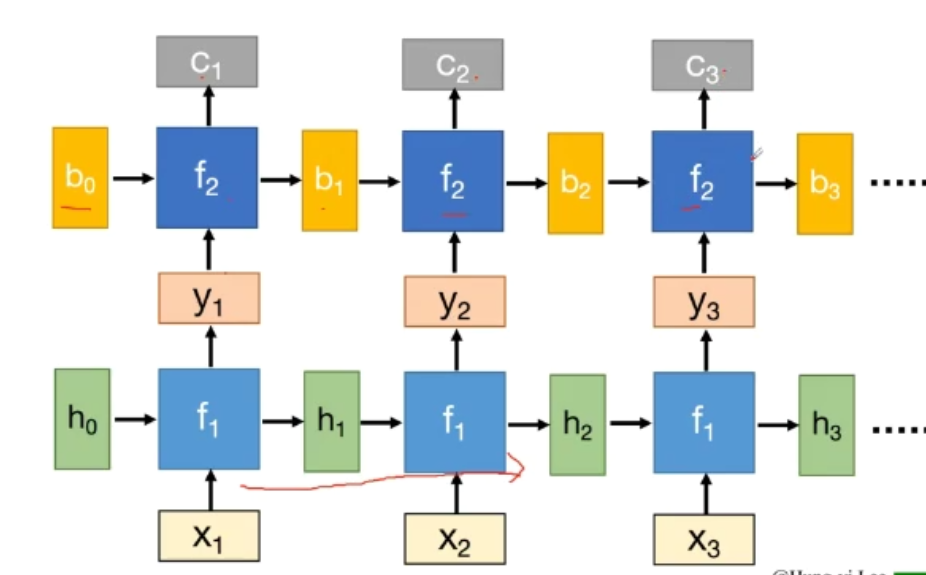
双向RNN
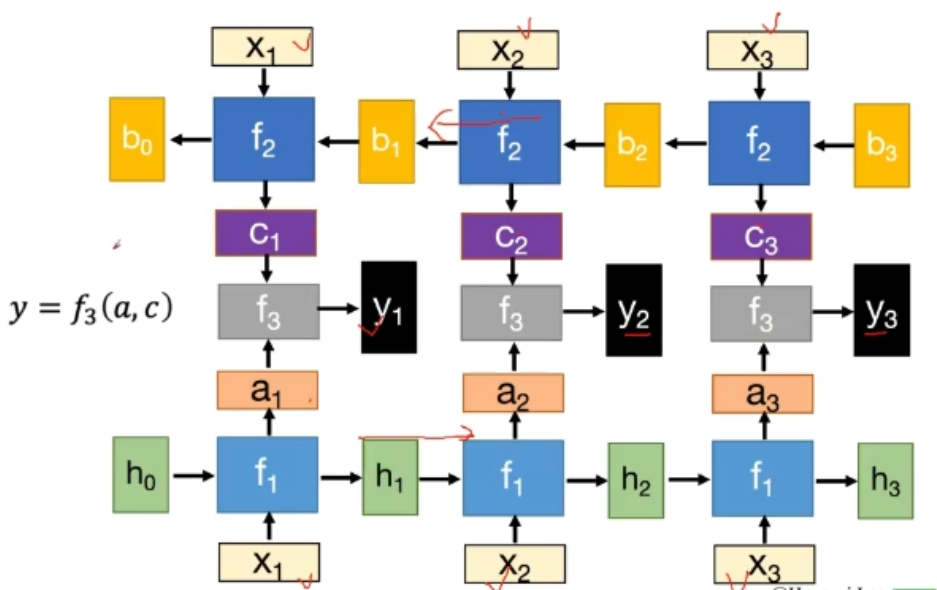
小结:
- 隐层状态h可以被看作是“记忆”,因为它包含了之前时间点上的相关信息
- 输出y不仅由当前的输入所决定,还会考虑到之前的“记忆“。由两者共同决定
- RNN在不同时刻共享同一组参数(U,W,V),极大的减小了需要训练和预估的参数量
BP算法


当循环神经网络在时间维度上非常深的时候,会导致梯度消失或梯度爆炸的问题。
梯度爆炸导致的问题:模型训练不稳定,梯度变为Nan(无效数字),Inf(无穷大)
梯度爆炸改进:
- 权重衰减(longrightarrow) (L^2)权重衰减 (hat{E} = E+ frac{lambda}{2n}sumlimits_w w^2)
- 梯度阶段(longrightarrow)检查误差梯度的值是否超过阈值,如果超过了就截断梯度,将梯度设置为阈值
梯度消失导致的问题:长时依赖问题
随着时间间隔的不断增大,RNN会丧失学习到连接如此远的信息的能力
梯度消失改进:
-
改进模型
-
LSTM,GRU
LSTM 长短期记忆模型
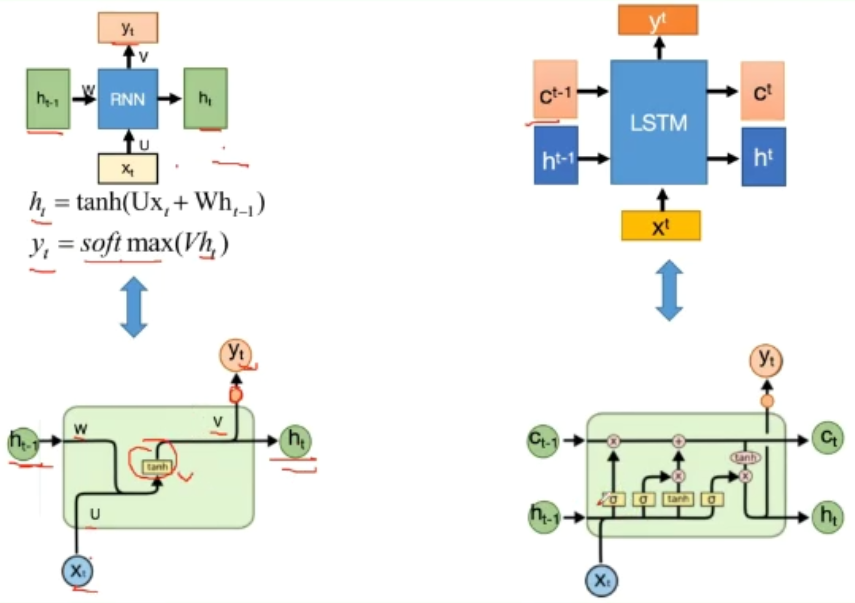
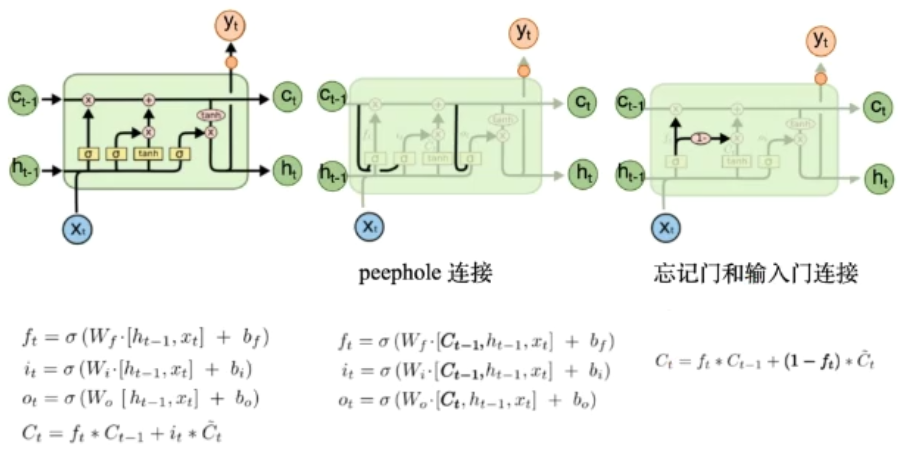
LSTM有三个门(遗忘门,输入门,输出门),来保护和控制细胞状态
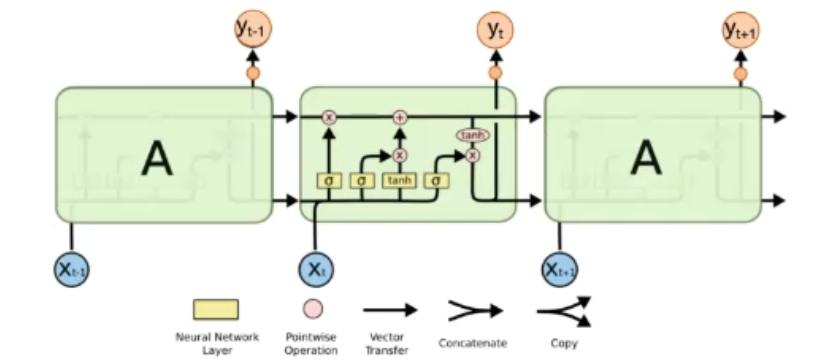
-
遗忘门:(f_t = sigma(W_f·[h_{t-1},x_t]+ b_f))
-
(sigma)为Sigmoid函数
-
输入门
[i_t = sigma(W_i·[h_{t-1},x_t]+ b_i)\ hat{C_t} = tanh(W_c·[h_{t-1},x_t]+b_C) ] -
首先经过Sigmoid层决定什么信息需要更新,然后通过tanh层输出备选的需要更新的内容,然后加入到新的状态中
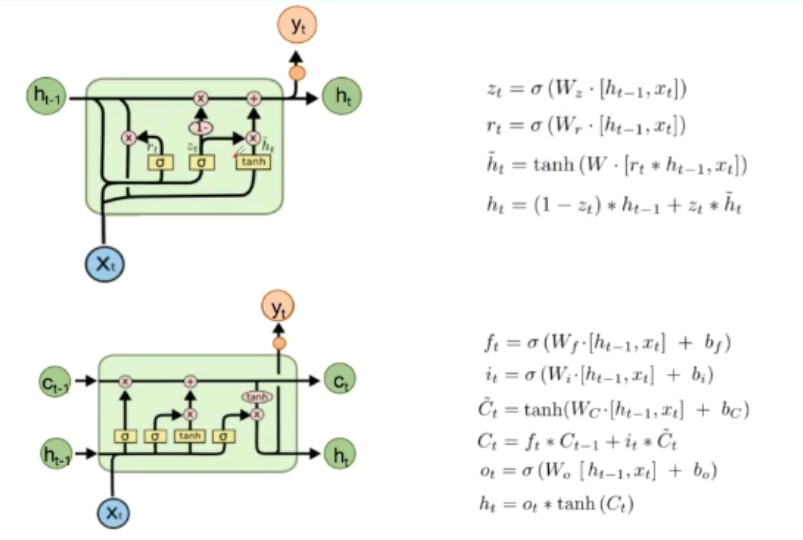
得到新的(C_t):(C_t = f_t * C_{t-1} + i_t * hat{C_t})
- 输出门[o_t = sigma(W_o·[h_{t-1},x_t]+ b_o)\ h_t = o_t * tanh(C_t) ]通过sigmoid来确定细胞状态的哪个部分将输出出去,然后将细胞状态通过tanh进行处理并将它和sigmoid门的输出相乘,最终仅仅会输出我们确定输出的那部分
小结:
- LSTM实现了三个门计算,即遗忘门,输入门和输出门
- LSTM的一个初始化技巧就是将输出门的bias置为证书,这样刚开始训练的时候forget gate的值接近于1,不会发生梯度消失
- LSTM有三个门,运算复杂,如何解决?(longrightarrow)GRU
GRU
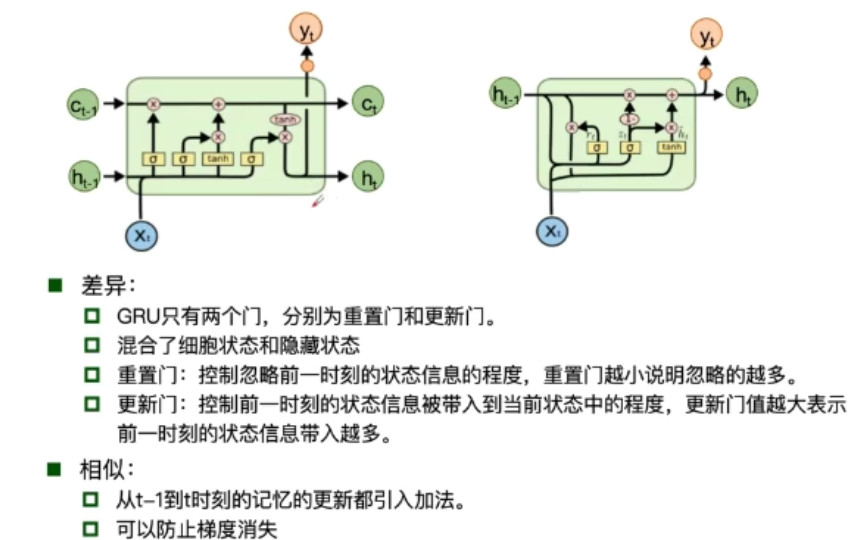
Clockwise RNN
普通RNN都是隐层从前一个时间步连接到当前时间步。而CW-RNN把隐层分成很多组,每组有不同的循环周期,有的周期是1,有的更长,这样一来,距离较远的某个依赖关系就可以通过周期较长的cell少数几次循环访问到,从而网络层数不太深,更容易学到。
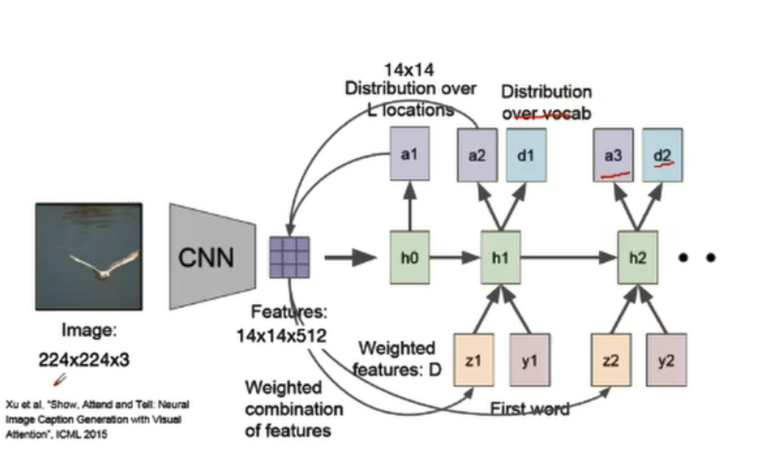
attention
什么是attention?
是受到人类注意力机制的启发,人们在进行观察图像的时候,不是一次就把整幅图像的每个位置像素都看过,大多是根据需求将注意力集中到图像的特定部分。而人类会根据之前观察的图像学习到未来要观察图像注意力应该集中的位置。