When a process running in user mode requests additional memory, pages are allocated from the list of free page frames maintained by the kernel. This list is typically populated using a page-replacement algorithm such as those discussed in Section 9.4 and most likely contains free pages scattered throughout physical memory, as explained earlier. Remember, too, that if a user process requests a single byte of memory, internal fragmentation will result, as the process will be granted an entire page frame. Kernel memory is often allocated from a free-memory pool different from the list used to satisfy ordinary user-mode processes. There are two primary reasons for this:
- The kernel requests memory for data structures of varying sizes, some of which are less than a page in size. As a result, the kernel must use memory conservatively and attempt to minimize waste due to fragmentation. This is especially important because many operating systems do not subject kernel code or data to the paging system.
- Pages allocated to user-mode processes do not necessarily have to be in contiguous physical memory. However, certain hardware devices interact directly with physical memory—without the benefit of a virtual memory interface—and consequently may require memory residing in physically contiguous pages.
通常32位Linux内核虚拟地址空间划分0~3G为用户空间,3~4G为内核空间(注意,内核可以使用的线性地址只有1G)。注意这里是32位内核地址空间划分,64位内核地址空间划分是不同的。
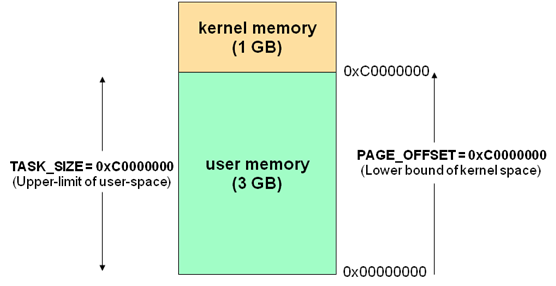
每个进程的页面目录就分成了两部分,第一部分为“用户空间”,用来映射其整个进程空间(0x0000 0000-0xBFFF FFFF)即3G字节的虚拟地址;第二部分为“系统空间”,用来映射(0xC000 0000-0xFFFF FFFF)1G字节的虚拟地址。可以看出Linux系统中每个进程的页面目录的第二部分是相同的,所以从进程的角度来看,每个进程有4G字节的虚拟空间, 较低的3G字节是自己的用户空间,最高的1G字节则为与所有进程以及内核共享的系统空间。
由程序员通过 INT指令触发。cpu把软中断做为陷阱来处理,也叫编程异常,其中int 0x80可以用于执行系统调用,int3则主要用于设置断点(对程序进行调试)。
linux采用虚拟内存管理技术,每一个进程都有一个3G大小的独立的进程地址空间,这个地址空间就是用户空间。每个进程的用户空间都是完全独立、互不相干的。进程访问内核空间的方式:系统调用和中断。
创建进程等进程相关操作都需要分配内存给进程。这时进程申请和获得的不是物理地址,仅仅是虚拟地址。
实际的物理内存只有当进程真的去访问新获取的虚拟地址时,才会由“请页机制”产生“缺页”异常,从而进入分配实际页框的程序。该异常是虚拟内存机制赖以存在的基本保证,它会告诉内核去为进程分配物理页,并建立对应的页表,这之后虚拟地址才实实在在的映射到了物理地址上。
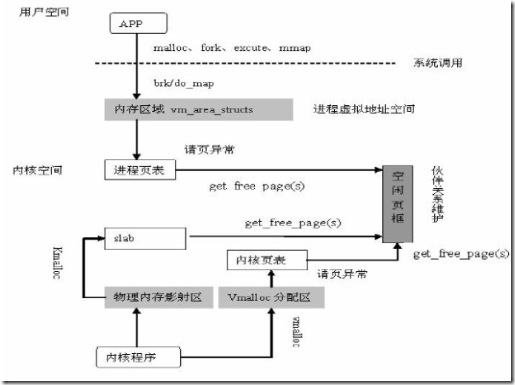
vmalloc和kmalloc区别
- kmalloc对应于kfree,分配的内存处于3GB~high_memory之间,这段内核空间与物理内存的映射一一对应,可以分配连续的物理内存; vmalloc对应于vfree,分配的内存在VMALLOC_START~4GB之间,分配连续的虚拟内存,但是物理上不一定连续。
- vmalloc() 分配的物理地址无需连续,而kmalloc() 确保页在物理上是连续的
- kmalloc分配内存是基于slab,因此slab的一些特性包括着色,对齐等都具备,性能较好。物理地址和逻辑地址都是连续的。
- 最主要的区别是分配大小的问题,比如你需要28个字节,那一定用kmalloc,如果用vmalloc,分配不多次机器就罢工了。
- 尽管仅仅在某些情况下才需要物理上连续的内存块,但是,很多内核代码都调用kmalloc(),而不是用vmalloc()获得内存。这主要是出于性能的考虑。vmalloc()函数为了把物理上不连续的页面转换为虚拟地址空间上连续的页,必须专门建立页表项。还有,通过 vmalloc()获得的页必须一个一个的进行映射(因为它们物理上不是连续的),这就会导致比直接内存映射大得多的缓冲区刷新。因为这些原因,vmalloc()仅在绝对必要时才会使用,最典型的就是为了获得大块内存时,例如,当模块被动态插入到内核中时,就把模块装载到由vmalloc()分配的内存上。
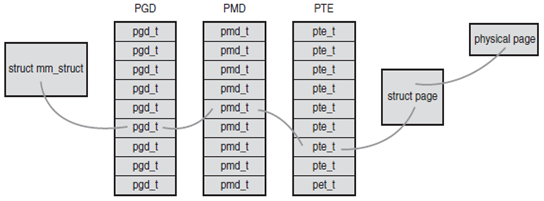
linux中使用三级页表完成地址转换。多数体系结构中,搜索页表的工作由硬件完成。在上面这个图中,顶级页表是页全局目录(PGD),二级页表是中间页目录(PMD).最后一级是页表(PTE),该页表结构指向物理页。上图中的页表对应的结构体定义在文件asm/page.h中。为了加快查找速度,在linux中实现了快表(TLB),其本质是一个缓冲器,作为一个将虚拟地址映射到物理地址的硬件缓存,当请求访问一个虚拟地址时,处理器将首先检查TLB中是否缓存了该虚拟地址到物理地址的映射,如果找到了,物理地址就立刻返回,否则,就需要再通过页表搜索需要的物理地址。
中文翻译就是个坑,前几天舍友问我什么是快表?我表示不知道。网上一查才知道原来是TLB.
摘自:http://www.cnblogs.com/bizhu/archive/2012/10/09/2717303.html
Slab allocation
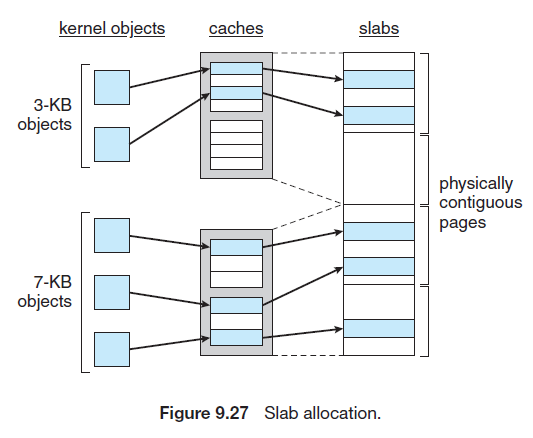
A slab is made up of one or more physically contiguous pages.A cache consists of one or more slabs. There is a single cache for each unique kernel data structure.
The slab allocator first attempts to satisfy the request with a free object in a partial slab. If none exists, a free object is assigned from an empty slab. If no empty slabs are available, a new slab is allocated from contiguous physical pages and assigned to a cache; memory for the object is allocated from this slab.
The slab allocator provides two main benefits:
- No memory is wasted due to fragmentation.
- Memory requests can be satisfied quickly.objects are created in advance and thus can be quickly allocated from the cache. Furthermore, when the kernel has finished with an object and releases it, it is marked as free and returned to its cache, thus making it immediately available for subsequent requests from the kernel.
Beginning with Version 2.6.24, the SLUB allocator replaced SLAB as the default allocator for the Linux kernel. SLUB addresses performance issues with slab allocation by reducing much of the overhead required by theSLAB allocator
内核空间
x86架构中将内核地址空间划分三部分:ZONE_DMA、ZONE_NORMAL和 ZONE_HIGHMEM。ZONE_HIGHMEM即为高端内存,这就是内存高端内存概念的由来。
ZONE_DMA 内存开始的16MB
ZONE_NORMAL 16MB~896MB
ZONE_HIGHMEM 896MB ~ 结束(1G)
当内核想访问高于896MB物理地址内存时,从0xF8000000 ~ 0xFFFFFFFF地址空间范围内找一段相应大小空闲的逻辑地址空间,借用一会。借用这段逻辑地址空间,建立映射到想访问的那段物理内存(即填充内核PTE页面表),临时用一会,用完后归还。这样别人也可以借用这段地址空间访问其他物理内存,实现了使用有限的地址空间,访问所有所有物理内存。
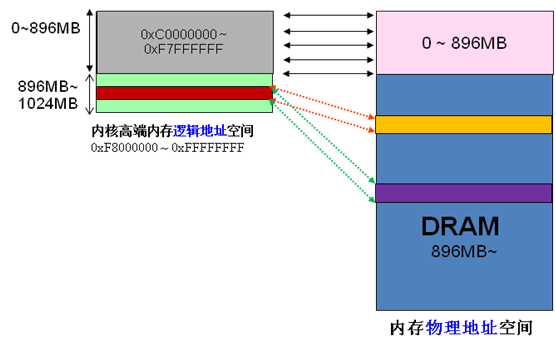
用户进程没有高端内存概念。只有在内核空间才存在高端内存。用户进程最多只可以访问3G物理内存,而内核进程可以访问所有物理内存。
目前现实中,64位Linux内核不存在高端内存,因为64位内核可以支持超过512GB内存。若机器安装的物理内存超过内核地址空间范围,就会存在高端内存。
摘自:http://blog.csdn.net/trochiluses/article/details/9297311
用户态和内核态切换
Linux的系统调用通过int 80h实现,用系统调用号来区分入口函数。 操作系统实现系统调用的基本过程是:
- 应用程序调用库函数(API);
- API将系统调用号存入EAX,然后通过中断调用使系统进入内核态;
- 内核中的中断处理函数根据系统调用号,调用对应的内核函数(系统调用);
- 系统调用完成相应功能,将返回值存入EAX,返回到中断处理函数;
- 中断处理函数返回到API中;
- API将EAX返回给应用程序。
用户内存空间布局
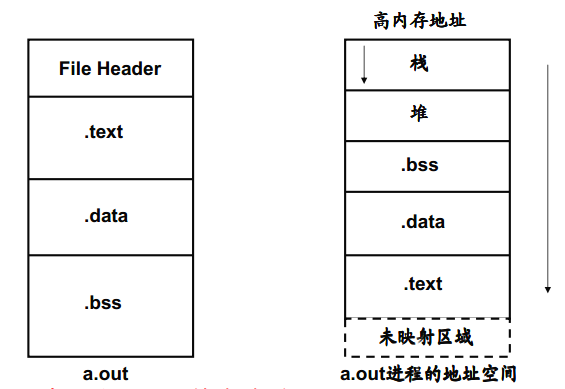
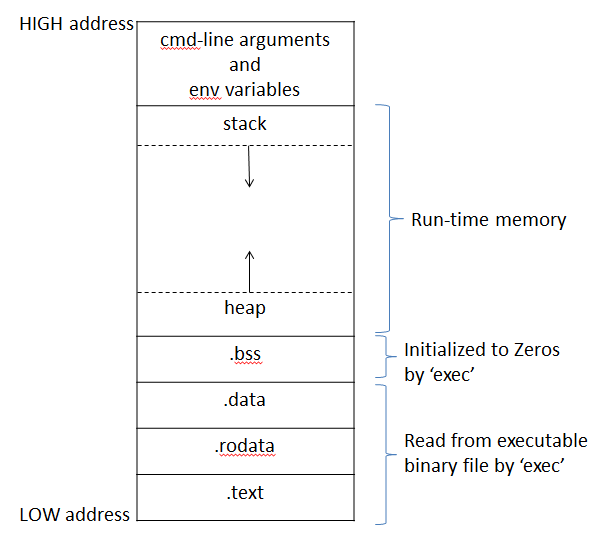
text段:就是放程序代码的,编译时确定,只读。
data段:存放在编译阶段(而非运行时)就能确定的数据,可读可写就是通常所说的静态存储区,赋了初值的全局变量和静态变量存放在这个域,常量也存放在这个区域。
rdata段:rdata是用来存放只读初始化变量的,当我们在源程序中的变量前面加了const后,编译器知道个字符串是永远不会改变的,或说是只读的,所以将其分配到.rdata段中。
bss段:定义而没有赋初值的全局变量和静态变量,放在这个区域
栈区(stack)— 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
堆区(heap) — 般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收
程序内存段和进程地址空间中的内存区域是种模糊对应,也就是说,堆、bss、数据段(初始化过的)都在进程空间中由数据段内存区域表示。
进程内存的分配与回收
创建进程fork()、程序载入execve()、映射文件mmap()、动态内存分配malloc()/brk()等进程相关操作都需要分配内存给进程。不过这时进程申请和获得的还不是实际内存,而是虚拟内存,准确的说是“内存区域”。进程对内存区域的分配最终都会归结到do_mmap()函数上来(brk调用被单独以系统调用实现,不用do_mmap()),
内核使用do_mmap()函数创建一个新的线性地址区间。但是说该函数创建了一个新VMA并不非常准确,因为如果创建的地址区间和一个已经存在的地址区间相邻,并且它们具有相同的访问权限的话,那么两个区间将合并为一个。如果不能合并,那么就确实需要创建一个新的VMA了。但无论哪种情况, do_mmap()函数都会将一个地址区间加入到进程的地址空间中--无论是扩展已存在的内存区域还是创建一个新的区域。
同样,释放一个内存区域应使用函数do_ummap(),它会销毁对应的内存区域。