Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下
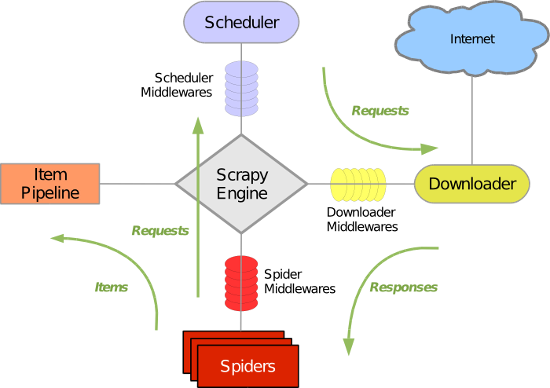
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
一、基本使用
1. 基本命令
1. scrapy startproject 项目名称 - 在当前目录中创建中创建一个项目文件(类似于Django) 2. scrapy genspider [-t template] <name> <domain> - 创建爬虫应用 如: scrapy gensipider -t basic oldboy oldboy.com scrapy gensipider -t xmlfeed autohome autohome.com.cn PS: 查看所有命令:scrapy gensipider -l 查看模板命令:scrapy gensipider -d 模板名称 3. scrapy list - 展示爬虫应用列表 4. scrapy crawl 爬虫应用名称 - 运行单独爬虫应用
2.项目结构以及爬虫应用简介
project_name/ scrapy.cfg project_name/ __init__.py items.py pipelines.py settings.py spiders/ __init__.py 爬虫1.py 爬虫2.py 爬虫3.py
文件说明:
- scrapy.cfg 项目的主配置信息。(真正爬虫相关的配置信息在settings.py文件中)
- items.py 设置数据存储模板,用于结构化数据,如:Django的Model
- pipelines 数据处理行为,如:一般结构化的数据持久化
- settings.py 配置文件,如:递归的层数、并发数,延迟下载等
- spiders 爬虫目录,如:创建文件,编写爬虫规则


# -*- coding: utf-8 -*- import scrapy from copy import deepcopy import re class SnSpider(scrapy.Spider): name = 'sn' allowed_domains = ['suning.com'] start_urls = ['https://book.suning.com/'] def parse(self, response): # 第一大类分组 fir_div_list = response.xpath("//div[@class='menu-list']/div[@class='menu-item']") # 文学艺术 少儿 社科 # 第二大类分组 sec_div_list = response.xpath("//div[@class='menu-sub']") nums = -1 for fir_div in fir_div_list: item = dict() item["fir_category"] = fir_div.xpath("./dl/dt/h3/a/text()").extract_first() # 文学艺术 nums += 1 sec_div = sec_div_list[nums] p_list = sec_div.xpath("./div[@class='submenu-left']/p") # 小说 青春文学 艺术 动漫/幽默 for p in p_list: item["sec_category"] = p.xpath("./a/text()").extract_first() item["href"] = p.xpath("./a/@href").extract_first() if item["href"] is not None: yield scrapy.Request( item["href"], callback=self.parse_url, meta={"item":deepcopy(item)} ) nums += 1 # print(item) # 到达新的页面 def parse_url(self, response): item = response.meta["item"] li_list = response.xpath("//ul[@class='clearfix']/li") for li in li_list: # 商品详情链接 if li.xpath(".//a[1]/@href") is not None: product_href = "https:" + li.xpath(".//a[1]/@href").extract_first() # item["product_href"] = product_href # print(product_href) yield scrapy.Request( product_href, callback=self.get_deatil_content, meta={"item": deepcopy(item)} ) # 翻页 cur_page = int(response.xpath("//a[@class='cur']/text()").extract_first()) # 最大页码数 page_nums_str = response.xpath("//span[@class='page-more']/text()").extract_first() # print(page_nums_str, "*"*20) if page_nums_str is not None: # print(page_nums_str, "*"*20) page_nums = int(re.findall(r"d+", page_nums_str)[0]) print(page_nums, "*"*10) while cur_page <= page_nums: cur_url = response.xpath("//a[@class='cur']/@href").extract_first() # print(type(cur_url), "*"*50) # next_url = cur_url.replace(cur_url[11], str(cur_page), 1) next_url = cur_url[:10] + str(cur_page) + cur_url[11:] cur_page += 1 print("下一页", next_url) # print(next_url) if next_url is not None: next_url = "https://list.suning.com" + next_url print("翻页") yield scrapy.Request( next_url, callback=self.parse_url, meta={"item": deepcopy(item)} ) def get_deatil_content(self, responce): item = responce.meta["item"] item["title"] = responce.xpath("//h1[@id='itemDisplayName']/text()").extract_first() item["author"] = responce.xpath("//ul[@class='bk-publish clearfix']/li[1]/text()").extract_first() if responce.xpath("//a[@id='bigImg']/img/@src") is not None: item["img"] = "https:" + responce.xpath("//a[@id='bigImg']/img/@src").extract_first() item["book_publish"] = responce.xpath("//ul[@class='bk-publish clearfix']/li[2]/text()").extract_first() item["publish_date"] = responce.xpath("//ul[@class='bk-publish clearfix']/li[3]/span[2]/text()").extract_first() yield item # print(item)
3、选择器
from scrapy.selector import Selector, HtmlXPathSelector from scrapy.http import HtmlResponse html = """<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8"> <title></title> </head> <body> <ul> <li class="item-"><a id='i1' href="link.html">first item</a></li> <li class="item-0"><a id='i2' href="llink.html">first item</a></li> <li class="item-1"><a href="llink2.html">second item<span>vv</span></a></li> </ul> <div><a href="llink2.html">second item</a></div> </body> </html> """ response = HtmlResponse(url='http://example.com', body=html,encoding='utf-8') # hxs = HtmlXPathSelector(response) # print(hxs) # hxs = Selector(response=response).xpath('//a') # print(hxs) # hxs = Selector(response=response).xpath('//a[2]') # print(hxs) # hxs = Selector(response=response).xpath('//a[@id]') # print(hxs) # hxs = Selector(response=response).xpath('//a[@id="i1"]') # print(hxs) # hxs = Selector(response=response).xpath('//a[@href="link.html"][@id="i1"]') # print(hxs) # hxs = Selector(response=response).xpath('//a[contains(@href, "link")]') # print(hxs) # hxs = Selector(response=response).xpath('//a[starts-with(@href, "link")]') # print(hxs) # hxs = Selector(response=response).xpath('//a[re:test(@id, "id+")]') # print(hxs) # hxs = Selector(response=response).xpath('//a[re:test(@id, "id+")]/text()').extract() # print(hxs) # hxs = Selector(response=response).xpath('//a[re:test(@id, "id+")]/@href').extract() # print(hxs) # hxs = Selector(response=response).xpath('/html/body/ul/li/a/@href').extract() # print(hxs) # hxs = Selector(response=response).xpath('//body/ul/li/a/@href').extract_first() # print(hxs) # ul_list = Selector(response=response).xpath('//body/ul/li') # for item in ul_list: # v = item.xpath('./a/span') # # 或 # # v = item.xpath('a/span') # # 或 # # v = item.xpath('*/a/span') # print(v)
4、settings.py配置文件介绍
# -*- coding: utf-8 -*- # 爬虫名称 BOT_NAME = 'step8_king' # 爬虫应用路径 SPIDER_MODULES = ['step8_king.spiders'] NEWSPIDER_MODULE = 'step8_king.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent # 客户端 user-agent请求头 # USER_AGENT = 'step8_king (+http://www.yourdomain.com)' # Obey robots.txt rules # 是否遵循机器人协议 # ROBOTSTXT_OBEY = False # Configure maximum concurrent requests performed by Scrapy (default: 16) # 并发请求数 # CONCURRENT_REQUESTS = 4 # Configure a delay for requests for the same website (default: 0) # See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs # 延迟下载秒数 # DOWNLOAD_DELAY = 2 # The download delay setting will honor only one of: # 单域名访问并发数,并且延迟下次秒数也应用在每个域名 # CONCURRENT_REQUESTS_PER_DOMAIN = 2 # 单IP访问并发数,如果有值则忽略:CONCURRENT_REQUESTS_PER_DOMAIN,并且延迟下次秒数也应用在每个IP # CONCURRENT_REQUESTS_PER_IP = 3 # Disable cookies (enabled by default) # 是否支持cookie,cookiejar进行操作cookie # COOKIES_ENABLED = True # COOKIES_DEBUG = True # Disable Telnet Console (enabled by default) # Telnet用于查看当前爬虫的信息,操作爬虫等... # 使用telnet ip port ,然后通过命令操作 # TELNETCONSOLE_ENABLED = True # TELNETCONSOLE_HOST = '127.0.0.1' # TELNETCONSOLE_PORT = [6023,] # 默认请求头 # Override the default request headers: # DEFAULT_REQUEST_HEADERS = { # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', # 'Accept-Language': 'en', # } # 爬虫允许的最大深度,可以通过meta查看当前深度;0表示无深度 # DEPTH_LIMIT = 3 # 爬取时,0表示深度优先Lifo(默认);1表示广度优先FiFo # 后进先出,深度优先 # DEPTH_PRIORITY = 0 # SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleLifoDiskQueue' # SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.LifoMemoryQueue' # 先进先出,广度优先 # DEPTH_PRIORITY = 1 # SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleFifoDiskQueue' # SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.FifoMemoryQueue' # 调度器队列 # SCHEDULER = 'scrapy.core.scheduler.Scheduler' # from scrapy.core.scheduler import Scheduler # 自动限速算法 from scrapy.contrib.throttle import AutoThrottle 自动限速设置 1. 获取最小延迟 DOWNLOAD_DELAY 2. 获取最大延迟 AUTOTHROTTLE_MAX_DELAY 3. 设置初始下载延迟 AUTOTHROTTLE_START_DELAY 4. 当请求下载完成后,获取其"连接"时间 latency,即:请求连接到接受到响应头之间的时间 5. 用于计算的... AUTOTHROTTLE_TARGET_CONCURRENCY target_delay = latency / self.target_concurrency new_delay = (slot.delay + target_delay) / 2.0 # 表示上一次的延迟时间 new_delay = max(target_delay, new_delay) new_delay = min(max(self.mindelay, new_delay), self.maxdelay) slot.delay = new_delay """ # 开始自动限速 # AUTOTHROTTLE_ENABLED = True # The initial download delay # 初始下载延迟 # AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies # 最大下载延迟 # AUTOTHROTTLE_MAX_DELAY = 10 # The average number of requests Scrapy should be sending in parallel to each remote server # 平均每秒并发数 # AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: # 是否显示 # AUTOTHROTTLE_DEBUG = True # Enable and configure HTTP caching (disabled by default) # See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings """ 启用缓存 目的用于将已经发送的请求或相应缓存下来,以便以后使用 from scrapy.downloadermiddlewares.httpcache import HttpCacheMiddleware from scrapy.extensions.httpcache import DummyPolicy from scrapy.extensions.httpcache import FilesystemCacheStorage """ # 是否启用缓存策略 # HTTPCACHE_ENABLED = True # 缓存策略:所有请求均缓存,下次在请求直接访问原来的缓存即可 # HTTPCACHE_POLICY = "scrapy.extensions.httpcache.DummyPolicy" # 缓存策略:根据Http响应头:Cache-Control、Last-Modified 等进行缓存的策略 # HTTPCACHE_POLICY = "scrapy.extensions.httpcache.RFC2616Policy" # 缓存超时时间 # HTTPCACHE_EXPIRATION_SECS = 0 # 缓存保存路径 # HTTPCACHE_DIR = 'httpcache' # 缓存忽略的Http状态码 # HTTPCACHE_IGNORE_HTTP_CODES = [] # 缓存存储的插件 # HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'