很多朋友做安全测试的,好多人应该都使用过burpsuite工具,这个工具功能强大,除了抓包,截包,改包功能使用外那就是安全了。这里简单的讲一下基本功能,proxy、repeater、spider、intruder一般会中四个功能也就够玩的了。

1.Target(目标)——显示目标目录结构的的一个功能
2.Proxy(代理)——是一个拦截HTTP/S的代理服务器(抓包),作为一个在浏览器和目标应用程序之间的中间人,允许你拦 截,查看,修改在两个方向上的原始数据流。
3.Spider(爬虫)——是一个应用智能感应的网络爬虫,它能完整的枚举应用程序的内容和功能。
4.Scanner(扫描器)[仅限专业版]——是一个高级的工具,执行后,它能自动地发现web 应用程序的安全漏洞。
5.Intruder(入侵)——是一个定制的高度可配置的工具,对web应用程序进行自动化攻击,如:枚举标识符,收集有用的数 据,以及使用fuzzing 技术探测常规漏洞。
6.Repeater(中继器)——是一个靠手动操作来补发单独的HTTP 请求,并分析应用程序响应的工具。
7.Sequencer(会话)——是一个用来分析那些不可预知的应用程序会话令牌和重要数据项的随机性的工具。
8.Decoder(解码器)——是一个进行手动执行或对应用程序数据者智能解码编码的工具。
9.Comparer(对比)——是一个实用的工具,通常是通过一些相关的请求和响应得到两项数据的一个可视化的“差异”。
10.Extender(扩展)——可以让你加载Burp Suite的扩展,使用你自己的或第三方代码来扩展Burp Suit的功能。
11.Options(设置)——对Burp Suite的一些设置
site map
这个主要是由spider功能模块爬出对应网站的一个站点地图,这里我通过spider功能扒取本地的一个74cms做测试。具体的怎么爬出站点地图在稍后的spider进行介绍。
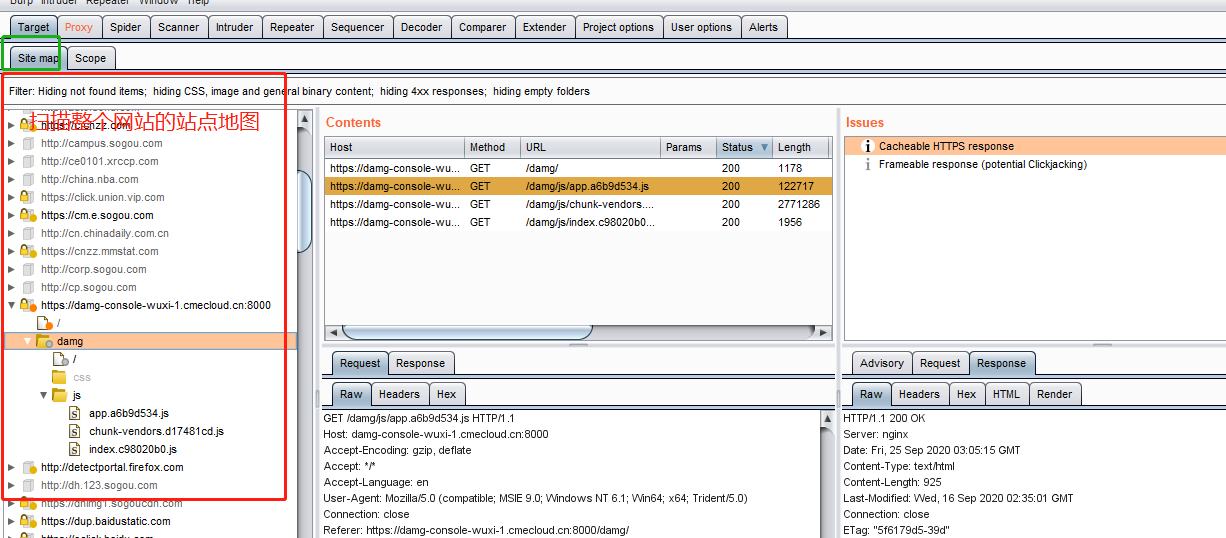
如图所示的,
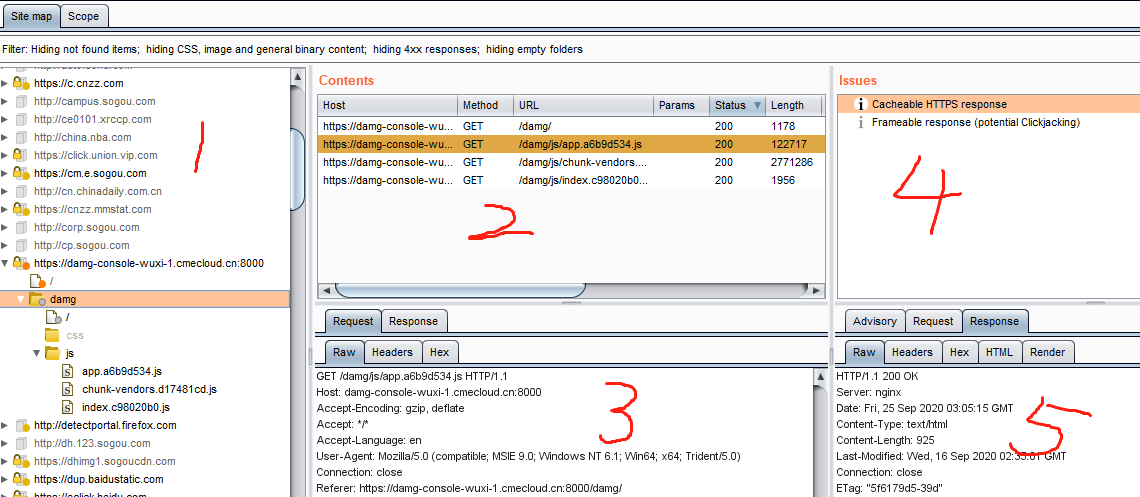
区块1就是扫描整个网站的站点地图
区块2就是递交的请求情况
区块3就是请求头和响应头的详细信息,包括源码,参数,头,16进制码。
区块4就是该网站存在的问题,这个spider功能能够扫描出网站一些比较明显的问题,当然肯定不全面,参考意义不是很大,漏洞扫描器推荐awvs,这个最开始还是比较好用的,不过到后来就会发现其实很多漏洞根本扫不出来。
区块5就是对应问题的详细信息以及解决方法。
然后可以看出区块上面还有一个filter的功能,这也是一个比较强大的功能,稍后做介绍。
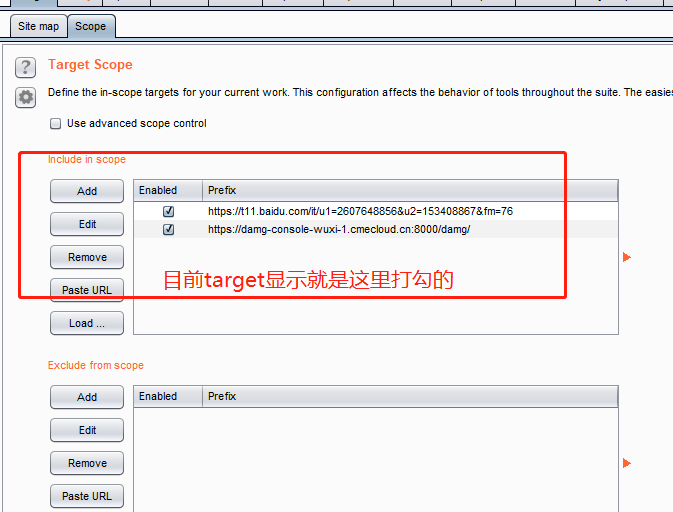
scope
然后是target下的scope栏目,
Proxy
这个代理抓包功能应该是使用最频繁的功能之一了,原理就是通过把127.0.0.1设置为代理服务器,由本机发起的请求都会通过127.0.0.1,
然后我们就可以把请求和响应包都截取下来。
首先要在浏览器的设置里添加一个代理,以火狐浏览器为例,点击选项,如下图
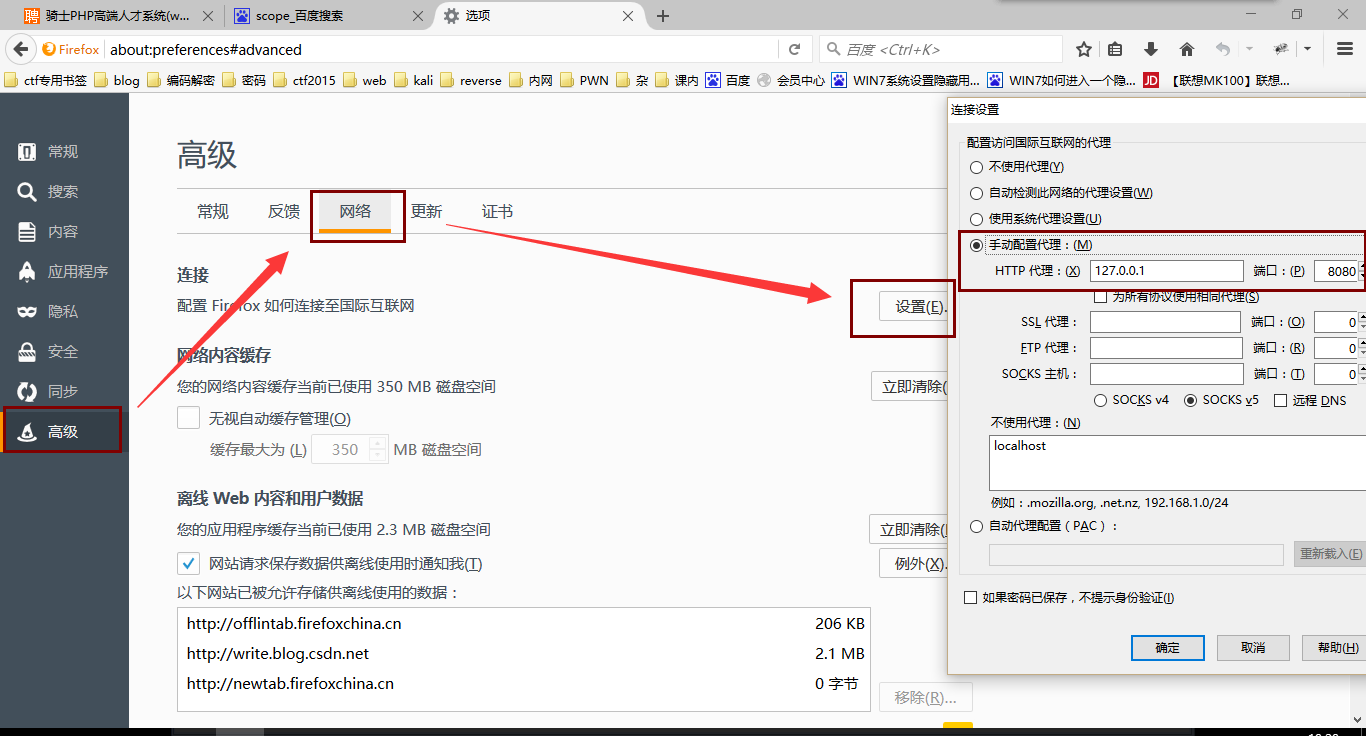
这里我设置的ip和端口分别是127.0.0.1和8080端口,然后在proxy下的Options一栏如下操作
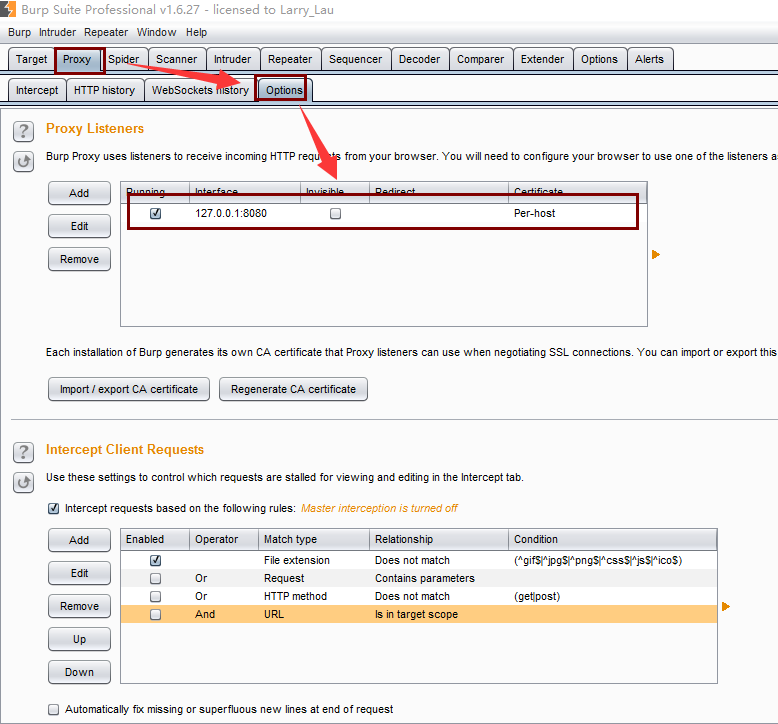
注意这里端口号一定要与浏览器设定的代理服务器端口号一致,如果8080被其他应用占用,可以将二者均换掉也无所谓。
这样,所有浏览器发出的请求和接受的响应都会被burpsuite拦截(PS:最后记得将浏览器的代理服务器勾选为不使用代理,否则一旦buresuite关了就可能上不了网了)
现在来介绍功能:
intercept
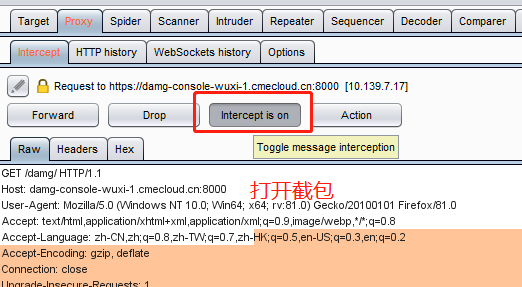
截取到包如下图:
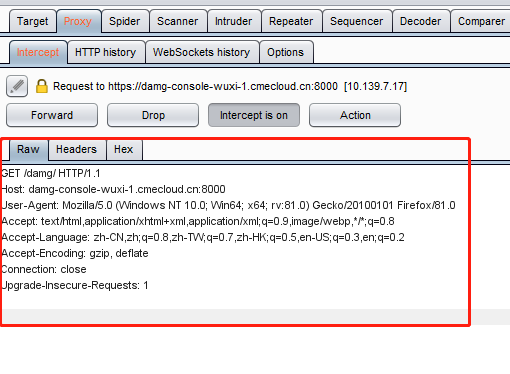
Forward:通俗来说就是将包发送出去
Drop:丢弃掉包
action的功能如下,也可以右键点击空白处
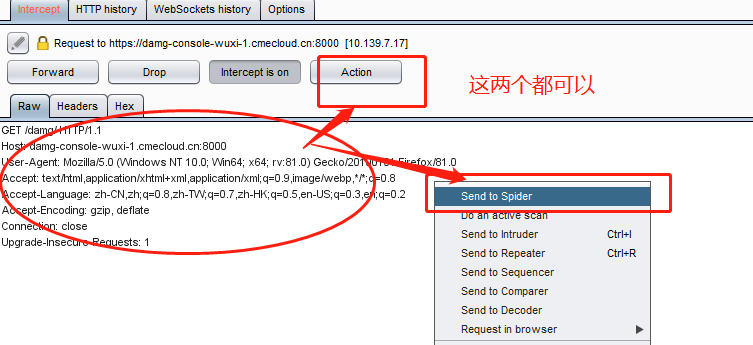
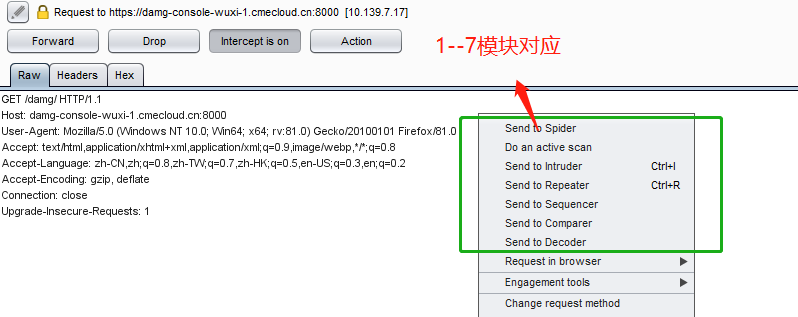
1-7分别对应到发送到最上方的七个模块
其他的英文应该都能读懂,自己试试就知道了,都比较清晰的
HTTP history
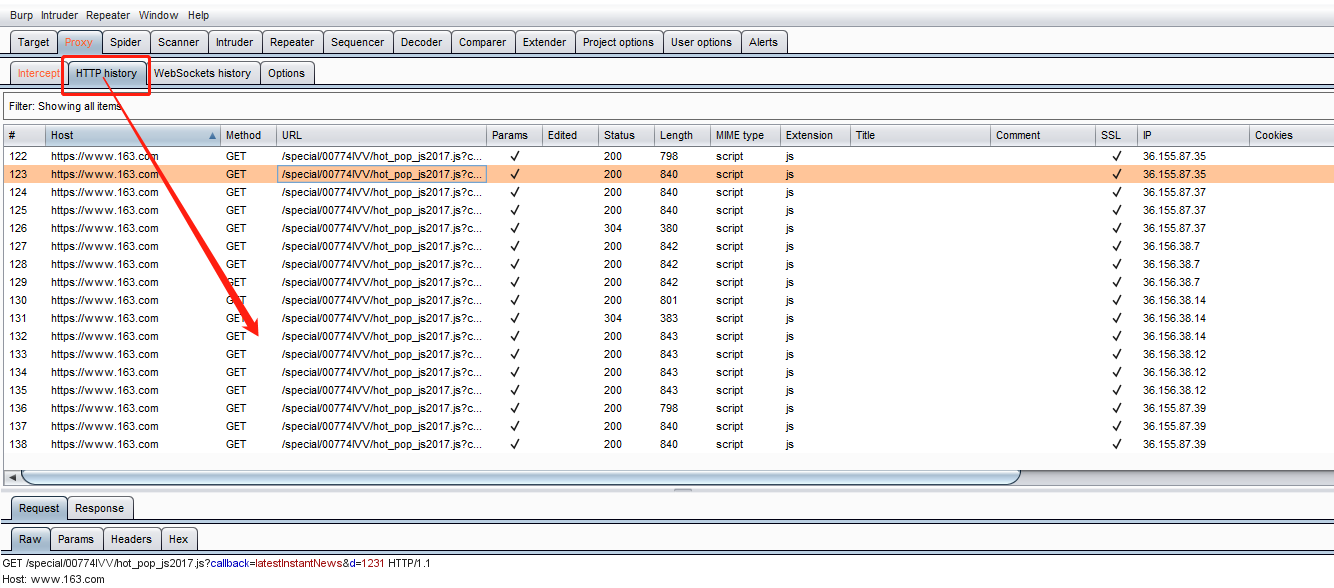
这个就是截取包的历史记录
然后我们来看看这个filter功能
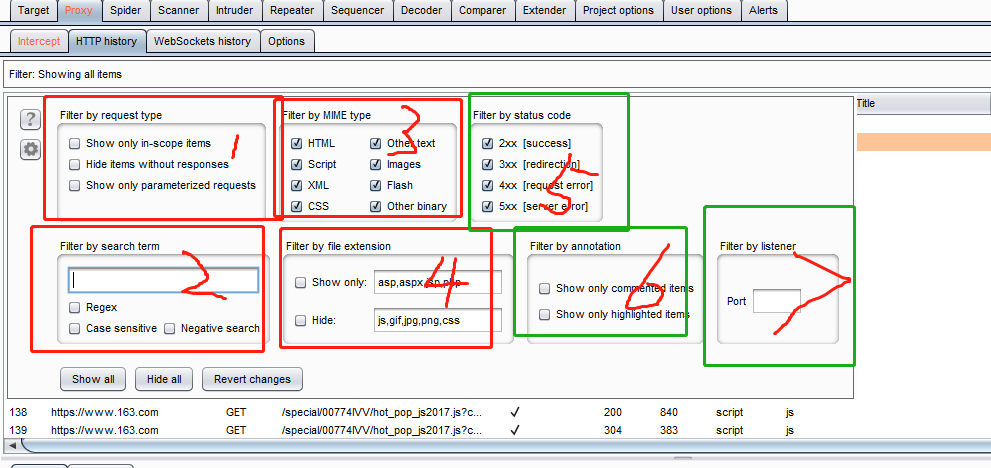
1、三项对应的是
- 只显示范围内的网址,这个主要在前面站点地图那里设置scope时的筛选
- 隐藏没有响应的记录
- 只展示有请求参数的记录
2、这里手动输入筛选条件可以支持正则、大小写敏感等
3、根据MIME类型进行筛选
4、展示和隐藏那些类型的请求记录
5、根据响应的HTTP状态码来筛选
6、显示评论过的和高亮的记录。注意,这里通过对记录点击右键是可以附加自己的评论或者是某一条记录以一种颜色高亮的。
7、端口筛选
Option
这里我主要截图介绍了一些常用的设置,其他不常用的就自己看吧。
Spider
control
要使用该功能就要先通过Proxy功能抓包,然后右键send to spider就行了,然后spider就开会运行,下图是运行结束后的情形

Options
这里截取几个个人较为常用的,其他一般不做修改,需要使用的时候自己看就行了
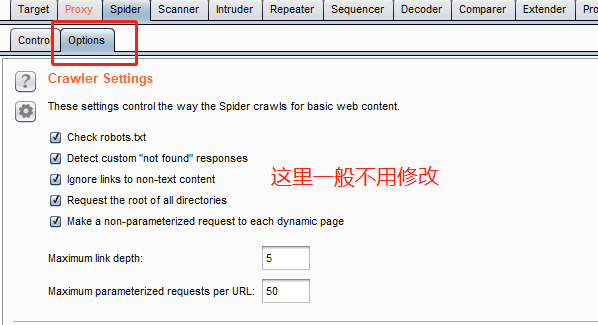
爬虫设置。
检查robots.txt,探测响应为not found等等。
下面的两个数字分别是最深的探测深度以及最多传递多少个参数
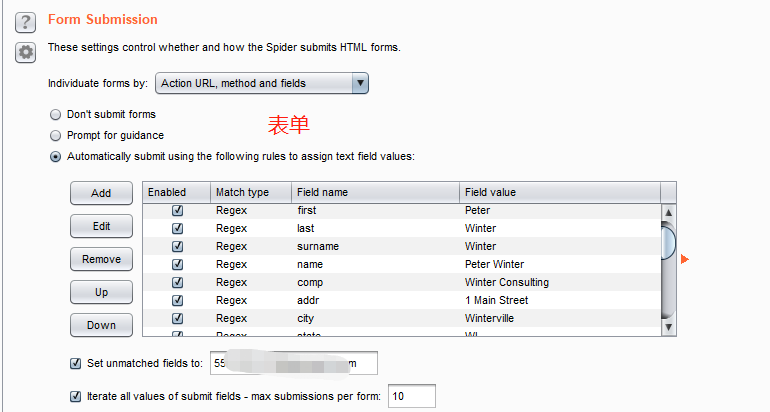
表单的提交设置。这个非常重要,就是爬虫遇到表单的时候怎么提交,显示是三个单选框,第一个就是不提交,第二个就弹出框体来由我们自己来填写并提交,第三个就是按照表中我们预先设定的值进行提交。
为什么说这个非常重要,因为表单和漏洞息息相关。。。
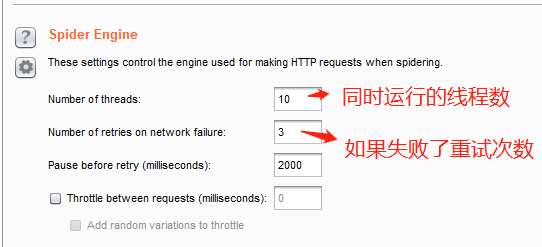
爬虫的引擎设置。
1、同时运行的线程数
2、如果失败了重试次数
3、重试延迟
一般来说都选用默认值,另外错误的话会最后的alert处显示出来,随时要关注。
intruder
定义通过添加字典(XSS,SQLI等等)来实现一个自动化的攻击或是密码爆破
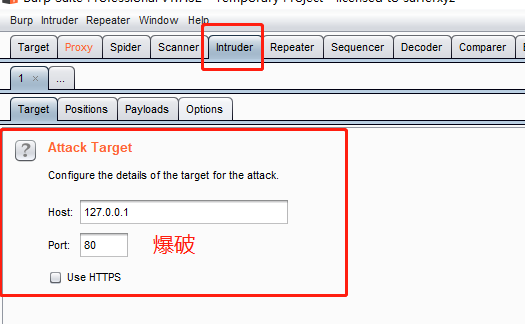
Target
一般来说我们使用intruder功能都是由Proxy然后send过来的,所以该栏目会默认填写的,当然也可以自己填,主要就是ip和端口号。
position
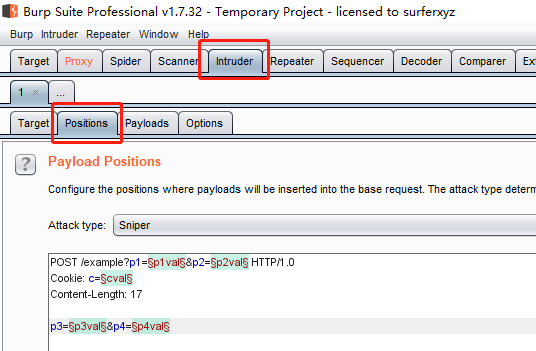
就是对HTTP请求进行操作了,定义通过添加字典(XSS,SQLI等等)来实现自动化。这里就是定义我们所选用的字典替换请求中的哪一部分需要被替换。然后至于那个attack type有四种
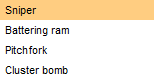
1、sniper,就是将字典一次赋给我们的多个参数,比如我们有三个参数,分别是a,b,c,字典里面有五个值(1,2,3,4,5),那么该模式下我们会先把a用字典替换,b、c保持原值,然后b用字典替换,a、c保持原值,以此类推。
2、battering ram,就是同时将a,b,c都用字典替换,例如a,b,c都用1替换,都用2替换。
3、pitchfork,那就是需要我们导入三个字典,依次对应进行替换。
4、cluster bomb,这个说起来比较麻烦,也是导入三个字典,就是比如a,b,c三个,原本应该有字典1替换a,字典2替换b,字典3替换c,然后它还会继续排列组合,比如字典1替换b,字典2替换c,字典3替换a,知道尝试完所有可能。
这个可以自己试一试然后观看一下结果就知道各个模式的作用了。
同样这个对一部分文本右键也是有很多功能,这里不做详述。
payload
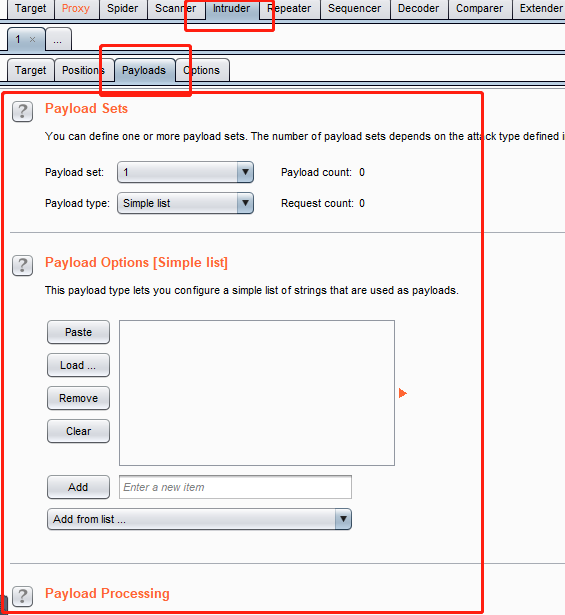
这里就是字典的导入,可以手动添加,也可以文件导入。
第一个数字就是第几本字典,第二个就是选择模式,有很多种
simple list:就是最简单的,手动输入或是文件导入都可以,可以导入多个字典。一般较少的数据使用该模式。
runtime file:这个应该主要就是针对较大批量的数据的字典把。
number:就是设置from 和to从多少到多少,然后step是间隔,例如from为1,to为100,step为2,那么payload就是1,3,5….
brute forcer:暴力破解,尝试你定义字符的所有组合,可以设置最小和最大长度,纯暴力破解。
接下来是payload Processing一栏,主要是对payload进行统一的规则设置,
Options
最后就是一些设置,和之前的差不太多,什么线程啊,失败重传啊等等之类不做想说了。
当所有一切设置好之后
点击右上角start attack就可以开始了。
0x06 Repeater
一般使用这个功能也是通过Proxy抓包然后send过来的。
主要就是修改请求的各项参数等等然后点击左上角的go发送出去,然后在右边接受到请求,请求和响应都可以以不同的形式展示出来。
Decoder
编码解码功能,没有太多可说的,自己随便试试就知道了
0x08 Comparer
主要是一个比较功能。
- 可以在Proxy处截包发送过来进行比较
- 也可以直接加载文件进行比较
用法比较简单个人使用频率也很高。
0x09 Alerts
这里展示警告信息。一定要随时关注这里。
一般来说就是比如爬虫的时候递交请求频率过快而被服务器拒绝访问等等之类的