sysctl -a 查看内核配置
1)优化Linux文件打开最大数:
vi /etc/security/limits.conf
* soft noproc 60000
* hard noproc 65535
* soft nofile 65535
* hard nofile 65535
为了防止失控的进程破坏系统的性能,Unix和Linux跟踪进程使用的大部分资源,允许用户和系统管理员使用对进程的资源限制,设置的限制有两种: 硬限制和软限制:
hard硬限制是可以在任何时候任何进程中设置 但硬限制只能由超级用户修改。
soft软限制是内核实际执行的限制,任何进程都可以将软限制设置为任意小于等于对进程限制的硬限制的值,(noproc)最大线程数和(nofile)文件数。
2)内核参数的优化
vi /etc/sysctl.conf
net.ipv4.tcp_max_tw_buckets = 6000
timewait的数量,默认是180000。
net.ipv4.ip_local_port_range = 1024 65000 #关系到最大timewait数 端口范围是一个闭区间,所以实际可用的端口数量是65000-1024+1
允许系统打开的端口范围。
net.ipv4.tcp_tw_recycle = 1 #官方建议不开启此项,如果开启此项,必须要将访问此台机器的net.ipv4.tcp_timestamps关闭。http://blog.sina.com.cn/s/blog_781b0c850100znjd.html
启用timewait快速回收。
net.ipv4.tcp_tw_reuse = 1
开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接。
net.ipv4.tcp_syncookies = 1
开启SYN Cookies,当出现SYN等待队列溢出时,启用cookies来处理。
net.core.somaxconn = 262144
web应用中listen函数的backlog默认会给我们内核参数的net.core.somaxconn限制到128,而nginx定义的NGX_LISTEN_BACKLOG默认为511,所以有必要调整这个值。
net.core.netdev_max_backlog = 262144
每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。
net.ipv4.tcp_max_orphans = 262144
系统中最多有多少个TCP套接字不被关联到任何一个用户文件句柄上。如果超过这个数字,孤儿连接将即刻被复位并打印出警告信息。这个限制仅仅是为了防止简单的DoS攻击,不能过分依靠它或者人为地减小这个值,更应该增加这个值(如果增加了内存之后)。
net.ipv4.tcp_max_syn_backlog = 262144
记录的那些尚未收到客户端确认信息的连接请求的最大值。对于有128M内存的系统而言,缺省值是1024,小内存的系统则是128。
net.ipv4.tcp_timestamps = 0 #注意这个开启会与net.ipv4.tcp_tw_recycle冲突(临时关闭echo 0 > /proc/sys/net/ipv4/tcp_timestamps)。案例可参考http://www.bubuko.com/infodetail-1650846.html
时间戳可以避免序列号的卷绕。一个1Gbps的链路肯定会遇到以前用过的序列号。时间戳能够让内核接受这种“异常”的数据包。这里需要将其关掉 。
net.ipv4.tcp_synack_retries = 1
为了打开对端的连接,内核需要发送一个SYN并附带一个回应前面一个SYN的ACK。也就是所谓三次握手中的第二次握手。这个设置决定了内核放弃连接之前发送SYN+ACK包的数量。
net.ipv4.tcp_syn_retries = 1
在内核放弃建立连接之前发送SYN包的数量。
net.ipv4.tcp_fin_timeout = 1
如果套接字由本端要求关闭,这个参数决定了它保持在FIN-WAIT-2状态的时间。对端可以出错并永远不关闭连接,甚至意外当机。缺省值是60秒。2.2 内核的通常值是180秒,你可以按这个设置,但要记住的是,即使你的机器是一个轻载的WEB服务器,也有因为大量的死套接字而内存溢出的风险,FIN- WAIT-2的危险性比FIN-WAIT-1要小,因为它最多只能吃掉1.5K内存,但是它们的生存期长些。
net.ipv4.tcp_keepalive_time = 30
当keepalive起用的时候,TCP发送keepalive消息的频度。缺省是2小时。
net.ipv4.tcp_rmem 和 net.ipv4.tcp_wmem
为每个TCP连接分配的读、写缓冲区内存大小,单位是Byte
net.ipv4.tcp_rmem = 4096 8192 4194304
net.ipv4.tcp_wmem = 4096 8192 4194304
第一个数字表示,为TCP连接分配的最小内存
第二个数字表示,为TCP连接分配的缺省内存
第三个数字表示,为TCP连接分配的最大内存
一般按照缺省值分配,上面的例子就是读写均为8KB,共16KB
.6GB TCP内存能容纳的连接数,约为 1600MB/16KB = 100K = 1
参考 https://www.cnblogs.com/94cool/p/5631905.html
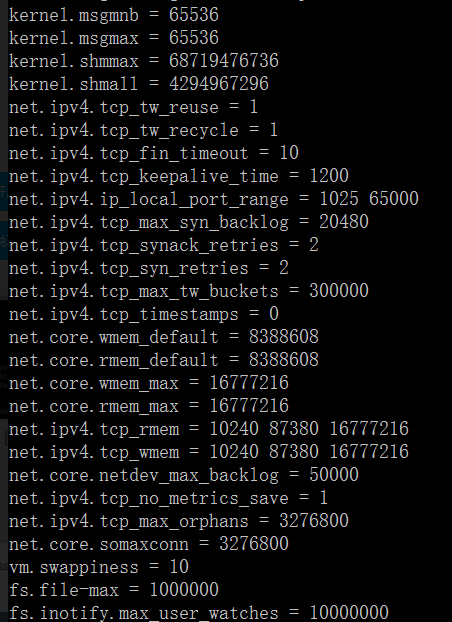
完整的内核优化脚本:
net.ipv4.ip_forward = 0
net.ipv4.conf.default.rp_filter = 1
net.ipv4.conf.default.accept_source_route = 0
kernel.sysrq = 0
kernel.core_uses_pid = 1
net.ipv4.tcp_syncookies = 1
kernel.msgmnb = 65536
kernel.msgmax = 65536
kernel.shmmax = 68719476736
kernel.shmall = 4294967296
net.ipv4.tcp_max_tw_buckets = 10000
net.ipv4.tcp_sack = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_rmem = 4096 87380 4194304
net.ipv4.tcp_wmem = 4096 16384 4194304
net.core.wmem_default = 8388608
net.core.rmem_default = 8388608
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.core.netdev_max_backlog = 262144
net.core.somaxconn = 262144
net.ipv4.tcp_max_orphans = 3276800
net.ipv4.tcp_max_syn_backlog = 262144
net.ipv4.tcp_timestamps = 0
net.ipv4.tcp_synack_retries = 1
net.ipv4.tcp_syn_retries = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_mem = 94500000 915000000 927000000
net.ipv4.tcp_fin_timeout = 1
net.ipv4.tcp_keepalive_time = 30
net.ipv4.ip_local_port_range = 1024 65530
net.ipv4.icmp_echo_ignore_all = 1
微
注
配置完 需sysctl -p 重新加载下
3)常见内核报错解析
net.ipv4.tcp_max_tw_buckets错误:
Sep 23 04:45:54 localhost kernel: possible SYN flooding on port 80. Sending cookies.
Sep 23 04:45:55 localhost kernel: TCP: time wait bucket table overflow
Sep 23 04:45:55 localhost kernel: TCP: time wait bucket table overflow
Sep 23 04:45:55 localhost kernel: TCP: time wait bucket table overflow
Sep 23 04:45:55 localhost kernel: TCP: time wait bucket table overflow
Sep 23 04:45:55 localhost kernel: TCP: time wait bucket table overflow
Sep 23 04:45:55 localhost kernel: TCP: time wait bucket table overflow
如上错误是由于net.ipv4.tcp_max_tw_buckets设置过小导致,如果内核有如上错误,我们需要增加net.ipv4.tcp_max_tw_buckets的值。
Too many open files错误:
如果后台报错,大量的too many open files错误,一般主要是JAVA应用出现这类错误比较多。我们需要设置内核打开文件最大数。
ulimit -SHn 51200 临时生效,如果想永久生效,需要写入到系统内核里面:
vi /etc/security/limits.conf
* soft nproc 65535
* hard nproc 65535
* soft nofile 65535
* hard nofile 65535
SOFT软限制 可以突破 hard 硬限制 所有用户不能超过 number open file
然后exit退出,重新登录即生效,也可以写在/etc/profile文件里。
内核优化主要打开文件数;time wait buckets数 ,端口数 ,打开TCP time wait 快速回收;打开SYN COOKIES;fin_timeout 出现第第1次第2次挥手;keeplalieved_time
14.影响务器性能因素
影响Linux服务器性能的因素有很多,这里大致分为如下两类:
1)操作系统级
a)内存
b)CPU
c)磁盘I/O
d)网络I/O带宽
2)程序应用级
15.系统性能评估标准
影响性能因素 评判标准
|
影响性能因素 |
评判标准 |
||
|
好 |
坏 |
糟糕 |
|
|
CPU |
user% + sys%< 70% |
user% + sys%= 85% |
user% + sys% >=90% |
|
内存 |
Swap In(si)=0 Swap Out(so)=0 |
Per CPU with 10 page/s |
More Swap In & Swap Out |
|
磁盘 |
iowait % < 20% |
iowait % =35% |
iowait % >= 50% |
其中:
%user:表示CPU处在用户模式下的时间百分比。
%sys:表示CPU处在系统模式下的时间百分比。
%iowait:表示CPU等待输入输出完成时间的百分比。
swap in:即si,表示虚拟内存的页导入,即从SWAP DISK交换到RAM
swap out:即so,表示虚拟内存的页导出,即从RAM交换到SWAP DISK。
16.系统性能分析工具
1.常用系统命令
vmstat、sar、iostat、netstat、free、ps、top、iftop等
2.常用组合方式
vmstat、sar、iostat检测是否是CPU瓶颈
free、vmstat检测是否是内存瓶颈
iostat检测是否是磁盘I/O瓶颈
netstat、iftop检测是否是网络带宽瓶颈
17.Linux性能评估与优化
1)系统整体性能评估(uptime命令)
[root@web1 ~]# uptime
16:38:00 up 118 days, 3:01, 5 users, load average: 1.22, 1.02, 0.91
这里需要注意的是:load average这个输出值,这三个值的大小一般不能大于系统CPU的个数,例如,本输出中系统有8个CPU,如果load average的三个值长期大于8时,说明CPU很繁忙,负载很高,可能会影响系统性能,但是偶尔大于8时,倒不用担心,一般不会影响系统性能。相反,如果load average的输出值小于CPU的个数,则表示CPU还有空闲的时间片,比如本例中的输出,CPU是非常空闲的。
2)CPU性能评估
1)利用vmstat命令监控系统CPU
该命令可以显示关于系统各种资源之间相关性能的简要信息,这里我们主要用它来看CPU一个负载情况。
下面是vmstat命令在某个系统的输出结果:

r列表示运行和等待cpu时间片的进程数,这个值如果长期大于系统CPU的个数,说明CPU不足,需要增加CPU。
b列表示在等待资源的进程数,比如正在等待I/O、或者内存交换等。
us列显示了用户进程消耗的CPU 时间百分比。us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%,就需要考虑优化程序或算法。
sy列显示了内核进程消耗的CPU时间百分比。Sy的值较高时,说明内核消耗的CPU资源很多。
根据经验,us+sy的参考值为80%,如果us+sy大于 80%说明可能存在CPU资源不足。
2)利用sar命令监控系统CPU
sar功能很强大,可以对系统的每个方面进行单独的统计,但是使用sar命令会增加系统开销,不过这些开销是可以评估的,对系统的统计结果不会有很大影响。
下面是sar命令对某个系统的CPU统计输出:

对上面每项的输出解释如下:
%user列显示了用户进程消耗的CPU 时间百分比。
%nice列显示了运行正常进程所消耗的CPU 时间百分比。
%system列显示了系统进程消耗的CPU时间百分比。
%iowait列显示了IO等待所占用的CPU时间百分比
%steal列显示了在内存相对紧张的环境下pagein强制对不同的页面进行的steal操作 。
%idle列显示了CPU处在空闲状态的时间百分比。
问题
1)你是否遇到过系统CPU整体利用率不高,而应用缓慢的现象?
在一个多CPU的系统中,如果程序使用了单线程,会出现这么一个现象,CPU的整体使用率不高,但是系统应用却响应缓慢,这可能是由于程序使用单线程的原因,单线程只使用一个CPU,导致这个CPU占用率为100%,无法处理其它请求,而其它的CPU却闲置,这就导致了整体CPU使用率不高,而应用缓慢现象的发生。
3)内存性能评估
1)利用free指令监控内存
free是监控linux内存使用状况最常用的指令,看下面的一个输出:

一般有这样一个经验公式:应用程序可用内存/系统物理内存>70%时,表示系统内存资源非常充足,不影响系统性能,应用程序可用内存/系统物理内存<20%时,表示系统内存资源紧缺,需要增加系统内存,20%<应用程序可用内存/系统物理内存<70%时,表示系统内存资源基本能满足应用需求,暂时不影响系统性能。
内存爆满也会引起CPU和IO高
2)利用vmstat命令监控内存
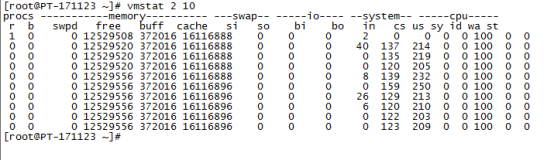
swpd列表示切换到内存交换区的内存数量(以k为单位)。如果swpd的值不为0,或者比较大,只要si、so的值长期为0,这种情况下一般不用担心,不会影响系统性能。
free列表示当前空闲的物理内存数量(以k为单位)
buff列表示buffers cache的内存数量,一般对块设备的读写才需要缓冲。
cache列表示page cached的内存数量,一般作为文件系统cached,频繁访问的文件都会被cached,如果cache值较大,说明cached的文件数较多,如果此时IO中bi比较小,说明文件系统效率比较好。
si列表示由磁盘调入内存,也就是内存进入内存交换区的数量。
so列表示由内存调入磁盘,也就是内存交换区进入内存的数量。
一般情况下,si、so的值都为0,如果si、so的值长期不为0,则表示系统内存不足。需要增加系统内存。
4)磁盘I/O性能评估
1)磁盘存储基础
熟悉RAID存储方式,可以根据应用的不同,选择不同的RAID方式。
尽可能用内存的读写代替直接磁盘I/O,使频繁访问的文件或数据放入内存中进行操作处理,因为内存读写操作比直接磁盘读写的效率要高千倍。
将经常进行读写的文件与长期不变的文件独立出来,分别放置到不同的磁盘设备上。
对于写操作频繁的数据,可以考虑使用裸设备代替文件系统。
使用裸设备的优点有:
数据可以直接读写,不需要经过操作系统级的缓存,节省了内存资源,避免了内存资源争用。
避免了文件系统级的维护开销,比如文件系统需要维护超级块、I-node等。
避免了操作系统的cache预读功能,减少了I/O请求。
使用裸设备的缺点是:
数据管理、空间管理不灵活,需要很专业的人来操作。
2)利用iostat评估磁盘性能
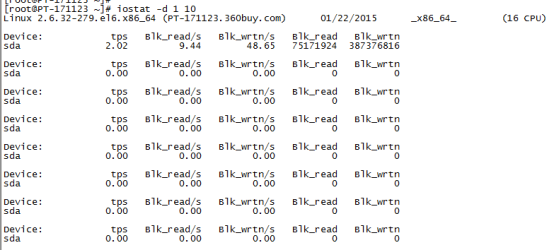
对上面每项的输出解释如下:
Blk_read/s表示每秒读取的数据块数。
Blk_wrtn/s表示每秒写入的数据块数。
Blk_read表示读取的所有块数。
Blk_wrtn表示写入的所有块数。
可以通过Blk_read/s和Blk_wrtn/s的值对磁盘的读写性能有一个基本的了解,如果Blk_wrtn/s值很大,表示磁盘的写操作很频繁,可以考虑优化磁盘或者优化程序,如果Blk_read/s值很大,表示磁盘直接读取操作很多,可以将读取的数据放入内存中进行操作。
对于这两个选项的值没有一个固定的大小,根据系统应用的不同,会有不同的值,但是有一个规则还是可以遵循的:长期的、超大的数据读写,肯定是不正常的,这种情况一定会影响系统性能。
3)利用sar评估磁盘性能
通过sar -d组合,可以对系统的磁盘IO做一个基本的统计,请看下面的一个输出:
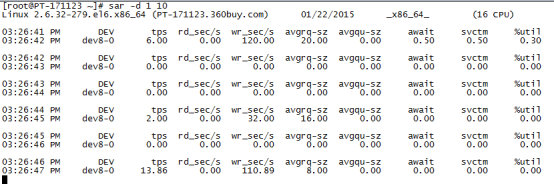
需要关注的几个参数含义:
await表示平均每次设备I/O操作的等待时间(以毫秒为单位)。
svctm表示平均每次设备I/O操作的服务时间(以毫秒为单位)。
%util表示一秒中有百分之几的时间用于I/O操作。
对以磁盘IO性能,一般有如下评判标准:
正常情况下svctm应该是小于await值的,而svctm的大小和磁盘性能有关,CPU、内存的负荷也会对svctm值造成影响,过多的请求也会间接的导致svctm值的增加。
await值的大小一般取决与svctm的值和I/O队列长度以及I/O请求模式,如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm的值,则表示I/O队列等待太长,系统上运行的应用程序将变慢,此时可以通过更换更快的硬盘来解决问题。
%util项的值也是衡量磁盘I/O的一个重要指标,如果%util接近100%,表示磁盘产生的I/O请求太多,I/O系统已经满负荷的在工作,该磁盘可能存在瓶颈。长期下去,势必影响系统的性能,可以通过优化程序或者通过更换更高、更快的磁盘来解决此问题。
5)网络性能评估
1)通过ping命令检测网络的连通性
2)通过netstat –i组合检测网络接口状况
3)通过netstat –r组合检测系统的路由表信息
4)通过sar -n组合显示系统的网络运行状态
5)通过iftop -i eth0 查看网卡流量
yum install sysstat iostat、mpstat、sar、sa的功能
yum install epel-release yum install iftop