作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075
一.把爬取的内容保存取MySQL数据库
- import pandas as pd
- import pymysql
- from sqlalchemy import create_engine
- conInfo = "mysql+pymysql://user:passwd@host:port/gzccnews?charset=utf8"
- engine = create_engine(conInfo,encoding='utf-8')
- df = pd.DataFrame(allnews)
- df.to_sql(name = ‘news', con = engine, if_exists = 'append', index = False)


import pandas as pd import requests from bs4 import BeautifulSoup from datetime import datetime import re import time import random import sqlite3 import pymysql from sqlalchemy import create_engine coninfo='mysql+pymysql://root:lyh0523@localhost:3306/gzccnews?charset=utf8' engine = create_engine(coninfo,encoding='utf-8') def click(url): id = re.findall('(d{1,5})',url)[-1]#返回所有匹配的字符串的字符串列表的最后一个 clickUrl = 'http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80'.format(id) resClick = requests.get(clickUrl) newsClick = int(resClick.text.split('.html')[-1].lstrip("('").rstrip("');")) return newsClick #时间 def newsdt(showinfo): newsDate = showinfo.split()[0].split(':')[1] newsTime = showinfo.split()[1] newsDT = newsDate+' '+newsTime dt = datetime.strptime(newsDT,'%Y-%m-%d %H:%M:%S')#转换成datetime类型 return dt #内容 def anews(url): newsDetail = {} res = requests.get(url) res.encoding = 'utf-8' soup = BeautifulSoup(res.text,'html.parser') newsDetail['newsTitle'] = soup.select('.show-title')[0].text#题目 showinfo = soup.select('.show-info')[0].text newsDetail['newsDT'] = newsdt(showinfo)#时间 newsDetail['newsClick'] = click(url)#点击次数 return newsDetail def alist(url): res = requests.get(listUrl) res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') newsList = [] for news in soup.select('li'):#获取li元素 if len(news.select('.news-list-title'))>0:#如果存在新闻题目 newsUrl = news.select('a')[0]['href']#获取新闻的链接 newsDesc = news.select('.news-list-description')[0].text#获取摘要文本 newsDict = anews(newsUrl)#通过链接获取题目时间点击数 newsDict['description'] = newsDesc newsList.append(newsDict)#把每个新闻的信息放进字典扩展到列表里 return newsList allnews = [] for i in range(59,69): listUrl = 'http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i) allnews.extend(alist(listUrl)) pd.Series(anews) newsdf=pd.DataFrame(allnews) for i in range(5): print(i) time.sleep(random.random()*3) print(newsdf) newsdf.to_csv('123.csv') #在本地项目下生成一个表格存储爬取新闻内容 newsdf.to_sql(name='news',con=engine,if_exists='append',index=False) conn=pymysql.connect(host='localhost',port=3306,user='root',passwd='lyh0523',db='gzccnews',charset='utf8') with sqlite3.connect('gzccnewsdb.sqlite') as db: newsdf.to_sql('gzccnewsdb',db) #在本地项目下生成一个数据库存储爬取新闻内容
效果图:

二.爬虫综合大作业
- 选择一个热点或者你感兴趣的主题。
- 选择爬取的对象与范围。
- 了解爬取对象的限制与约束。
- 爬取相应内容。
- 做数据分析与文本分析。
- 形成一篇文章,有说明、技术要点、有数据、有数据分析图形化展示与说明、文本分析图形化展示与说明。
- 文章公开发布。
正文分割线
对于经常逛B站的动漫迷来说,弹幕是最值得研究的一个部分,我们可以通过弹幕来判断该短视频的受欢迎程度。故在此借助爬虫技术对一个视频的弹幕进行爬取,观察观众的关注点。最近的漫威上映了一部新电影——复仇者联盟:终局之战,吸引了无数的漫威粉前去观看,对于漫威一直以来的那么多部与之相关的电影,不少人都想重温之前发生的事情,故有up主把复仇者联盟从无到有,从古到今的所有时间线,都整理出来了。本文就是对该up主的视频进行解析。
导包:
import requests-----网页请求
import time-----延时操作
import jieba----分词操作
import numpy as np-----图片格式转换为数组 from PIL
import Image-----图片的读取 from wordcloud
import WordCloud as wc----词云制作
网页分析:
https://www.bilibili.com/video/av49842011这是目标资源,通过开发者工具找到弹幕的链接(别问我怎么知道的),在此可以看到目标资源的所有弹幕信息
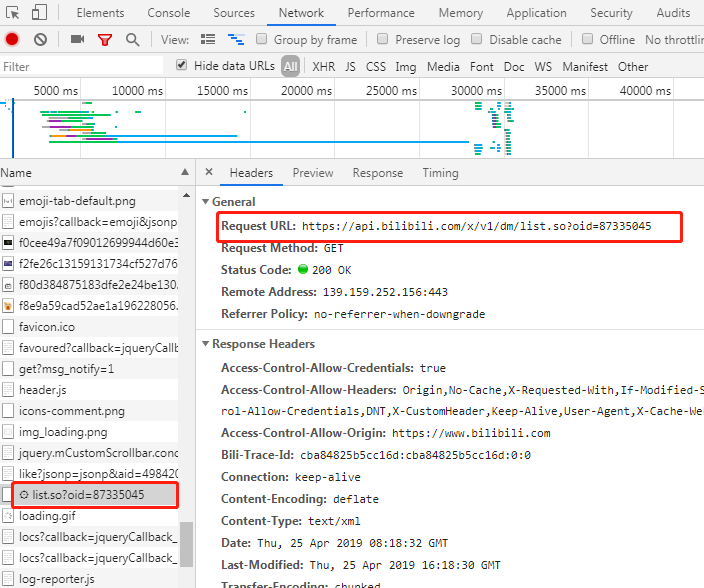
list.so?oid=xxxx的结果,这就是我们要找的弹幕资源。
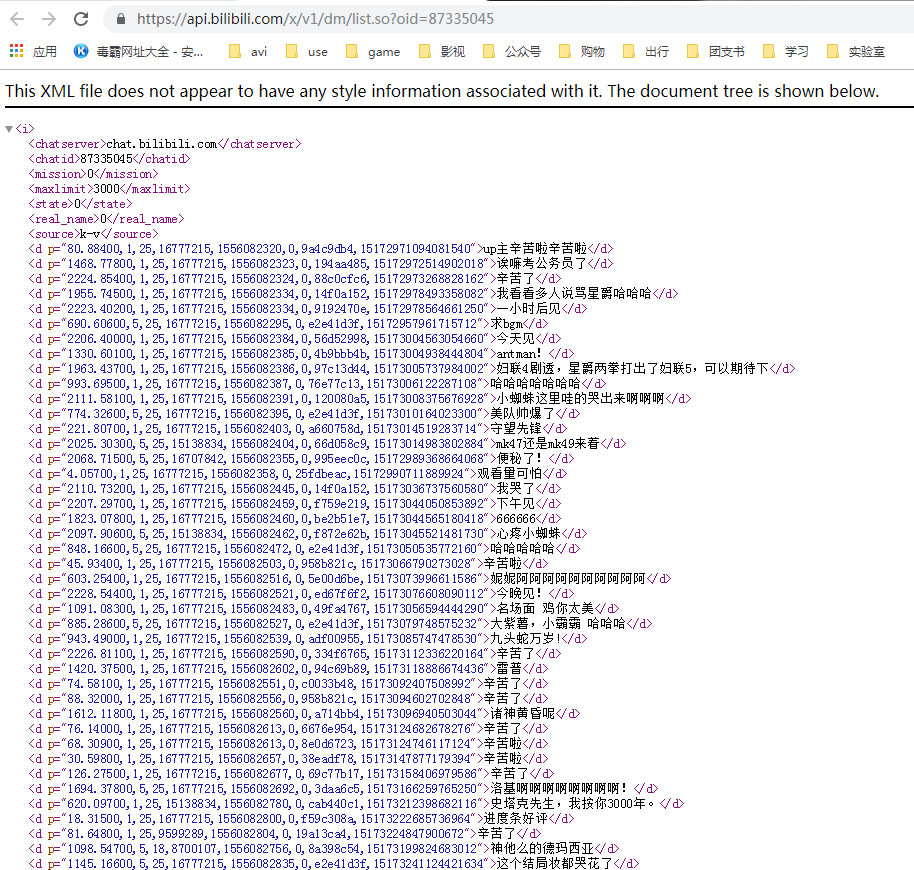
因此,我所要寻找的id不是平时网页地址栏的id,而是被隐藏了的id。
网页获取和解析:
把对网页的所有操作封装在一个类里面。初始化是设置请求头和url以及弹幕的获取,在此把整个xml文件下载到本地,用xpath解析xml文档。
def __init__(self,oid): self.headers={ 'Host': 'api.bilibili.com', 'Connection': 'keep-alive', 'Cache-Control': 'max-age=0', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Cookie': 'finger=edc6ecda; LIVE_BUVID=AUTO1415378023816310; stardustvideo=1; CURRENT_FNVAL=8; buvid3=0D8F3D74-987D-442D-99CF-42BC9A967709149017infoc; rpdid=olwimklsiidoskmqwipww; fts=1537803390' } self.url='https://api.bilibili.com/x/v1/dm/list.so?oid='+str(oid) self.barrage_reault=self.get_page() # 获取信息 def get_page(self): try: # 延时操作,防止太快爬取 time.sleep(0.5) response=requests.get(self.url,headers=self.headers) except Exception as e: print('获取xml内容失败,%s' % e) return False else: if response.status_code == 200: # 下载xml文件 with open('bilibilidanmu.xml','wb') as f: f.write(response.content) return True else: return False # 解析网页 def param_page(self): time.sleep(1) if self.barrage_reault: # 文件路径,html解析器 html=etree.parse('bilibilidanmu.xml',etree.HTMLParser()) # xpath解析,获取当前所有的d标签下的所有文本内容 results=html.xpath('//d//text()') return results
弹幕去重:
把弹幕内容存储到一个空的列表(result)中,每次准备存入一条弹幕都判断该列表是否已经含有该元素,有的话就添加到double_barrage列表和barrage集合中,方面接下来对重复的弹幕内容的统计。
# 弹幕去重 def remove_double_barrage(self): ''' double_arrage:所有重复弹幕的集合 results:去重后的弹幕 barrage:每种弹幕内容都存储一遍 ''' double_barrage=[] results=[] barrage=set() for result in self.param_page(): if result not in results: results.append(result) else: double_barrage.append(result) barrage.add(result) return double_barrage,results,barrage
弹幕重复内容的计数和词云的制作:
此处利用np.array(Image)函数,对生成的词云的图片大小进行限定。
# 弹幕重复计算和词云的制作 def make_wordCould(self): double_barrages,results,barrages=self.remove_double_barrage() # 重词计数 with open('barrages.csv','w',encoding='utf8') as f: for barrage in barrages: amount=double_barrages.count(barrage) f.write(barrage+':'+str(amount+1)+' ') # 设置停用词 stop_words=['【','】',',','.','?','!','。'] words=[] if results: for result in results: for stop in stop_words: result=''.join(result.split(stop)) words.append(result) # 列表拼接成字符串 words=''.join(words) words=jieba.cut(words) words=''.join(words) wcloud=np.array(Image.open('pic.jpg'))#wordcloud的形状=(初始图片的宽度、高度、通道) w=wc(font_path='C:/Windows/Fonts/SIMYOU.TTF',background_color='white',width=1600,height=1600,max_words=2000,mask=wcloud) w.generate(words) w.to_file('wcloud.jpg')
实现的效果:

从词云中可以看出一下几点:
-
- 对up主做出来的视频的认可,对其说一句“辛苦了”;
- 钢铁侠“妮妮”和奇异博士“本尼”这两位英雄比较受欢迎;
- 对视频展现的方式感到滑稽的也有不少观众。
当然,这个项目爬取的弹幕信息只是截止到该文章发表的时间,同一个视频在不同的时间爬取的弹幕所生成的词云会有所不同,期待过一两天这个视频所生成的词云会变成什么样。
在这个项目中还有不足的地方有以下几点:
-
- 可以对弹幕发布时间的分析;
- 对多个时间段的弹幕进行对比分析。
最后,在此奉上完整的代码~
from lxml import etree import requests import time import jieba import numpy as np from PIL import Image from wordcloud import WordCloud as wc class Bilibili(): """docstring for Bilibili""" def __init__(self,oid): self.headers={ 'Host': 'api.bilibili.com', 'Connection': 'keep-alive', 'Cache-Control': 'max-age=0', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Cookie': 'finger=edc6ecda; LIVE_BUVID=AUTO1415378023816310; stardustvideo=1; CURRENT_FNVAL=8; buvid3=0D8F3D74-987D-442D-99CF-42BC9A967709149017infoc; rpdid=olwimklsiidoskmqwipww; fts=1537803390' } self.url='https://api.bilibili.com/x/v1/dm/list.so?oid='+str(oid) self.barrage_reault=self.get_page() # 获取信息 def get_page(self): try: # 延时操作,防止太快爬取 time.sleep(0.5) response=requests.get(self.url,headers=self.headers) except Exception as e: print('获取xml内容失败,%s' % e) return False else: if response.status_code == 200: # 下载xml文件 with open('bilibilidanmu.xml','wb') as f: f.write(response.content) return True else: return False # 解析网页 def param_page(self): time.sleep(1) if self.barrage_reault: # 文件路径,html解析器 html=etree.parse('bilibilidanmu.xml',etree.HTMLParser()) # xpath解析,获取当前所有的d标签下的所有文本内容 results=html.xpath('//d//text()') return results # 弹幕去重 def remove_double_barrage(self): ''' double_arrage:所有重复弹幕的集合 results:去重后的弹幕 barrage:每种弹幕内容都存储一遍 ''' double_barrage=[] results=[] barrage=set() for result in self.param_page(): if result not in results: results.append(result) else: double_barrage.append(result) barrage.add(result) return double_barrage,results,barrage # 弹幕重复计算和词云的制作 def make_wordCould(self): double_barrages,results,barrages=self.remove_double_barrage() # 重词计数 with open('barrages.csv','w',encoding='utf8') as f: for barrage in barrages: amount=double_barrages.count(barrage) f.write(barrage+':'+str(amount+1)+' ') # 设置停用词 stop_words=['【','】',',','.','?','!','。'] words=[] if results: for result in results: for stop in stop_words: result=''.join(result.split(stop)) words.append(result) # 列表拼接成字符串 words=''.join(words) words=jieba.cut(words) words=''.join(words) wcloud=np.array(Image.open('pic.jpg'))#wordcloud的形状=(初始图片的宽度、高度、通道) w=wc(font_path='C:/Windows/Fonts/SIMYOU.TTF',background_color='white',width=1600,height=1600,max_words=2000,mask=wcloud) w.generate(words) w.to_file('wcloud.jpg') b=Bilibili(87335045)#弹幕资源 f12-->netword-->all-->list.so?oid=XXXX #b=Bilibili(2238927) b.make_wordCould()