作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2646
1.字符串操作:
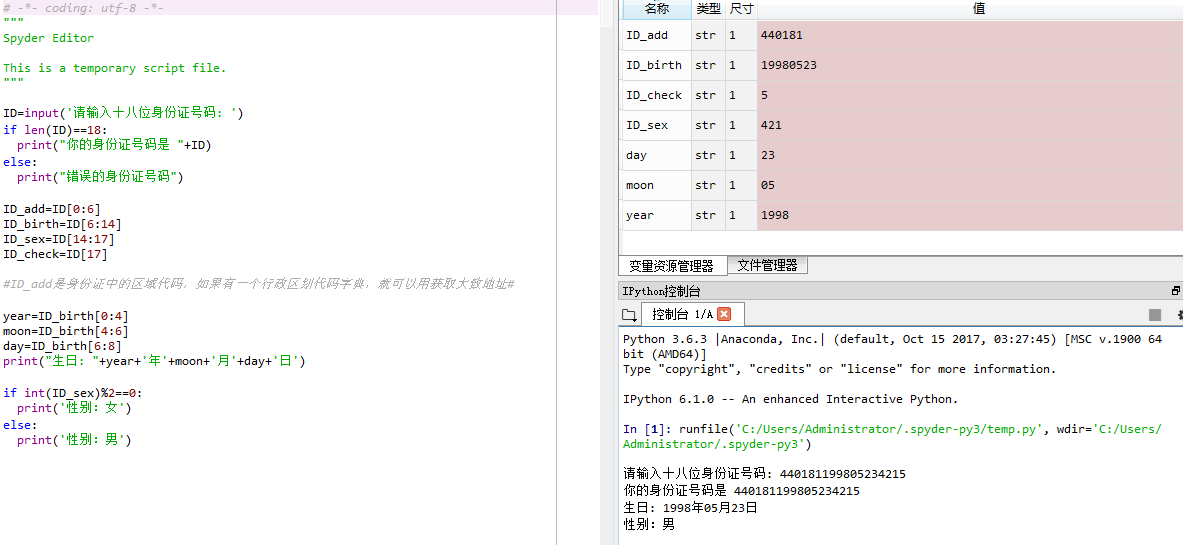
- 解析身份证号:生日、性别、出生地等。
# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a temporary script file.
"""
ID=input('请输入十八位身份证号码: ')
if len(ID)==18:
print("你的身份证号码是 "+ID)
else:
print("错误的身份证号码")
ID_add=ID[0:6]
ID_birth=ID[6:14]
ID_sex=ID[14:17]
ID_check=ID[17]
#ID_add是身份证中的区域代码,如果有一个行政区划代码字典,就可以用获取大致地址#
year=ID_birth[0:4]
moon=ID_birth[4:6]
day=ID_birth[6:8]
print("生日: "+year+'年'+moon+'月'+day+'日')
if int(ID_sex)%2==0:
print('性别:女')
else:
print('性别:男')
运行结果图如下:
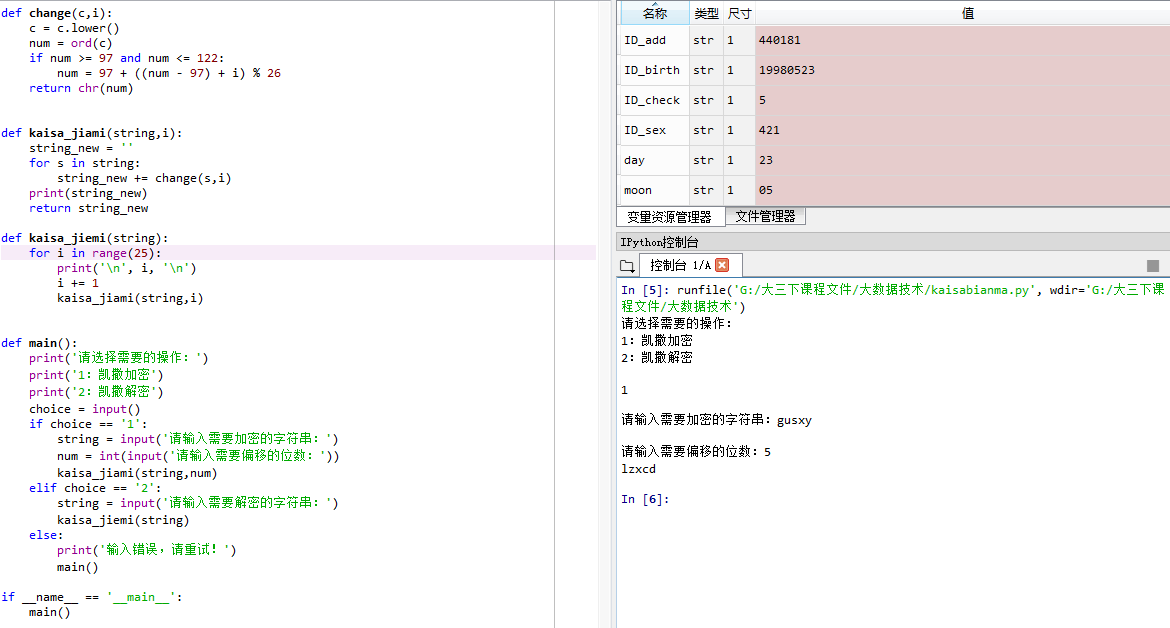
- 凯撒密码编码与解码。
def change(c,i):
c = c.lower()
num = ord(c)
if num >= 97 and num <= 122:
num = 97 + ((num - 97) + i) % 26
return chr(num)
def kaisa_jiami(string,i):
string_new = ''
for s in string:
string_new += change(s,i)
print(string_new)
return string_new
def kaisa_jiemi(string):
for i in range(25):
print('
', i, '
')
i += 1
kaisa_jiami(string,i)
def main():
print('请选择需要的操作:')
print('1:凯撒加密')
print('2:凯撒解密')
choice = input()
if choice == '1':
string = input('请输入需要加密的字符串:')
num = int(input('请输入需要偏移的位数:'))
kaisa_jiami(string,num)
elif choice == '2':
string = input('请输入需要解密的字符串:')
kaisa_jiemi(string)
else:
print('输入错误,请重试!')
main()
if __name__ == '__main__':
main()
运行结果图如下所示:
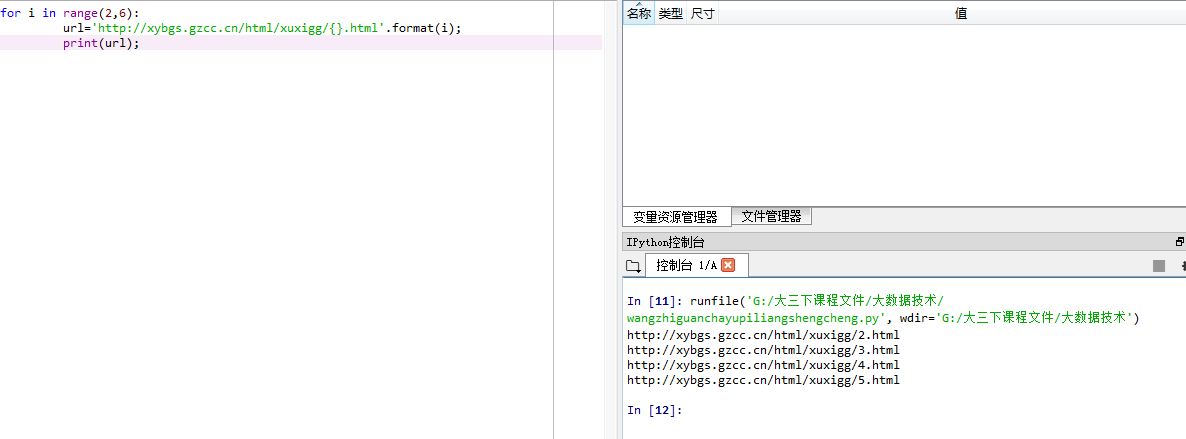
- 网址观察与批量生成。
for i in range(2,6):
url='http://xybgs.gzcc.cn/html/xuxigg/{}.html'.format(i);
print(url);
运行结果如图所示:
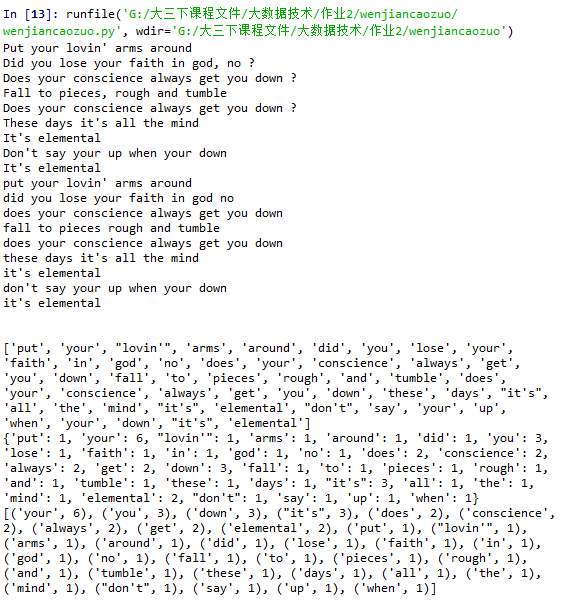
2.英文词频统计预处理:
- 下载一首英文的歌词或文章或小说,保存为utf8文件。
- 从文件读出字符串。
- 将所有大写转换为小写
- 将所有其他做分隔符(,.?!)替换为空格
- 分隔出一个一个的单词
- 并统计单词出现的次数。
#文件操作
def readFile():
f=open("speech.txt");
text=f.read();
print(text);
f.close();
return text;
#使用空格替换标点符号
t=readFile().lower();
article = t.replace(",","").replace(".","").replace(":","").replace(";","").replace("?","")
#大写字母转换成小写字母
exchange = article.lower();
print(exchange)
print('
')
#生成单词列表
list = exchange.split()
print(list)
#生成词频统计
dic = {}
for i in list:
count = list.count(i)
dic[i] = count
print(dic)
'''
#排除特定单词
word = {'and','the','with','in','by','its','for','of','an','to'}
for i in word:
del(dic[i])
print(dic)
'''
#排序
dic1= sorted(dic.items(),key=lambda d:d[1],reverse= True)
print(dic1)
print('
')
#输出词频最大的前十位单词
for i in range(10):
print(dic1[i])
结果如图所示: