普罗米修斯监控
使用docker部署普罗米修斯监控
普罗米修斯的基本架构

Prometheus Server
Prometheus Server是Prometheus组件中的核心部分,负责实现对监控数据的获取,存储以及查询。 Prometheus Server可以通过静态配置管理监控目标,也可以配合使用Service Discovery的方式动态管理监控目标,并从这些监控目标中获取数据。其次Prometheus Server需要对采集到的监控数据进行存储,Prometheus Server本身就是一个时序数据库,将采集到的监控数据按照时间序列的方式存储在本地磁盘当中。最后Prometheus Server对外提供了自定义的PromQL语言,实现对数据的查询以及分析。
Prometheus Server内置的Express Browser UI,通过这个UI可以直接通过PromQL实现数据的查询以及可视化。
Prometheus Server的联邦集群能力可以使其从其他的Prometheus Server实例中获取数据,因此在大规模监控的情况下,可以通过联邦集群以及功能分区的方式对Prometheus Server进行扩展。
Exporters
Exporter将监控数据采集的端点通过HTTP服务的形式暴露给Prometheus Server,Prometheus Server通过访问该Exporter提供的Endpoint端点,即可获取到需要采集的监控数据。
一般来说可以将Exporter分为2类:
- 直接采集:这一类Exporter直接内置了对Prometheus监控的支持,比如cAdvisor,Kubernetes,Etcd,Gokit等,都直接内置了用于向Prometheus暴露监控数据的端点。
- 间接采集:间接采集,原有监控目标并不直接支持Prometheus,因此我们需要通过Prometheus提供的Client Library编写该监控目标的监控采集程序。例如: Mysql Exporter,JMX Exporter,Consul Exporter等
AlertManager
在Prometheus Server中支持基于PromQL创建告警规则,如果满足PromQL定义的规则,则会产生一条告警,而告警的后续处理流程则由AlertManager进行管理。在AlertManager中我们可以与邮件,Slack等等内置的通知方式进行集成,也可以通过Webhook自定义告警处理方式。AlertManager即Prometheus体系中的告警处理中心。
如果遇到警告,普罗米修斯server把符合告警标准的数据推送给alertmanager,然后alertmanager通过插件prometheus-webhook-dingtalk 推送给钉钉
Grafana
负责以优雅的图形化页面来展示你所监控的数据 和他自带的web ui 一样通过promql来查询数据显示出来
一般可以使用自带的官方模板 8919 就不错
最后我会教 怎么导入模板
需求:现在有1000台服务器需要监控 而且要求数据持久化和普罗米修斯高可用
思路:
主备HA + 远程存储 + 联邦集群 = 服务可用性 , 数据持久化 , 水平扩展。
同时AlertManager也需要高可用

目标1
1000台服务器: 安装node_exporter 获取信息。 !!测试的话 这一步可以忽略 !!
目标2
3台普罗米修斯联邦集群:这三台需要获取那1000台服务器的相关信息 然后将数据持久化。
目标3
若干普罗米修斯server: 从三台联邦普罗米修斯获取数据 不需要数据持久化。
目标1: !! 测试的话 这一步可以忽略 !!
通过ansible 给1000台服务器安装node_exporter
node_exporter没有必要去使用docker去部署 会产生不必要的性能浪费 一般使用软件包部署
首先去下载 node_exporter 这里这个版本是服务我服务器的版本如果有需要别的版本去官方网站找找
官方网站https://github.com/prometheus/node_exporter/releases
然后用wget下载下来
wget https://github.com/prometheus/node_exporter/releases/download/v1.0.1/node_exporter-1.0.1.linux-amd64.tar.gz
将下载好的包用ansible传到那1000台主机里 然后运行命令
创建目录
mkdir /opt/exporter
解压到刚刚创建的目录
tar zxvf node_exporter-1.0.1.linux-amd64.tar.gz -C /opt/exporter
写exporter的service文件
cat > /etc/systemd/system/export.service<< EOF
[Unit]
Description=Prometheus Server
After=network.target
[Service]
Restart=on-failure
WorkingDirectory=/opt/exporter/node_exporter-1.0.1.linux-amd64/
ExecStart=/opt/exporter/node_exporter-1.0.1.linux-amd64/node_exporter
[Install]
WantedBy=multi-user.target
EOF
跟新systemctl配置
systemctl daemon-reload
启动export测试
systemctl start export
开机自启export
systemctl enable export
然后 curl http://本机ip:9100/metrics 看能不能获取到监控信息 如果可以的话证明没有问题
完成目标1
目标2
docker的yum源去清华大学开源站获取然后将docker源里的官方地址改为清华大学地址
下载好docker后 添加docker镜像加速去阿里云的容器加速服务获取自己的加速地址 他会告诉你怎么做
通过epel源 下载docker-compose , ok 安装好docker和docker-compose后
创建/opt/prometheus/目录
在目录里添加下面三个文件
第一个:docker-compose.yml 文件
version: "3" #指定 docker-compose.yml 文件的写法格式
networks: #定义一个名称为 monitor 的网络,由于networks是top-level(顶层级别,所以需要在顶层设置),而且driver内容不能省略
monitor:
driver: bridge # driver为bridge的网络
services: #多个容器集合
prometheus:
image: prom/prometheus #指定服务所使用的镜像
container_name: prometheus #定义启动后容器的名字
hostname: prometheus #主机名
restart: always # 配置重启,docker每次启动时会启动该服务
volumes: #卷挂载路径 宿主机路径:容器路径 这里主要定义了 一会需要的配置文件
- /opt/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml 配置文件1
- /opt/prometheus/alertmanager-rule.yml:/etc/prometheus/alertmanager-rule.yml 配置文件2
- /etc/localtime:/etc/localtime 时间时区同步
ports: 定义宿主机端口和容器端口的映射,宿主机端口:容器端口
- "9090:9090"
networks: #加入到 monitor 网络,实现容器间通信
- monitor
prometheus-webhook-alert:
image: quay.io/timonwong/prometheus-webhook-dingtalk
container_name: prometheus-webhook-alertmanagers
hostname: webhook-alertmanagers
restart: always
volumes:
- /etc/localtime:/etc/localtime
- /opt/webhook-dingtalk/default.tmpl:/usr/share/prometheus-webhook-dingtalk/template/default.tmpl 配置文件3
ports:
- "8060:8060"
entrypoint: /bin/prometheus-webhook-dingtalk --ding.profile="webhook1=这里是你的钉钉机器人API" --template.file=/usr/share/prometheus-webhook-dingtalk/template/default.tmpl
networks:
- monitor
grafana:
image: grafana/grafana
container_name: grafana
hostname: grafana
restart: always
volumes:
- /etc/localtime:/etc/localtime
ports:
- "3000:3000"
networks:
- monitor
exporter:
image: prom/node-exporter
container_name: node-exporter
hostname: node-exporter
restart: always
volumes:
- /proc:/host/proc:ro
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/host/sys:ro
- /etc/localtime:/etc/localtime
ports:
- "9100:9100"
networks:
- monitor
influxdb:
image: influxdb:latest
container_name: influxdb
hostname: influxdb
restart: always
volumes:
- /opt/influxdb/config:/etc/influxdb 配置文件4
- /opt/influxdb/data:/var/lib/influxdb/data
- /etc/localtime:/etc/localtime
ports:
- "8086:8086"
- "8083:8083"
environment:
- INFLUXDB_DB=prometheus
- INFLUXDB_ADMIN_ENABLED=true
- INFLUXDB_ADMIN_USER=admin
- INFLUXDB_ADMIN_PASSWORD=adminpwd
- INFLUXDB_USER=prometheus
- INFLUXDB_USER_PASSWORD=prometheuspwd
- INFLUXDB_CONFIG_PATH=/etc/influxdb/influxdb.conf
logging:
driver: "json-file"
options:
max-size: "1g"
networks:
- monitor
配置文件1 普罗米修斯主配置文件 :prometheus.yml
global: # 全局配置
scrape_interval: 15s #从exporter抓取数据周期,可用单位ms、smhdwy #设置每15s采集数据一次,默认1分钟
evaluation_interval: 15s #计算规则的默认周期 # 每15秒计算一次告警规则,默认1分钟
alerting: # Alertmanager相关配置
alertmanagers:
- static_configs:
- targets: ["改为本机ip:9093"] 这里指向alertmanager的服务端口
rule_files: # 告警规则文件
[ /etc/prometheus/alertmanager-rule.yml ] 这里指向了告警的配置文件
#这里因为远程数据库搭建在了本地所以填写本地ip即可 就是docker-copose里的influxdb 用来实现数据持久化
remote_write: #写数据库
- url: "http://远程数据库ip:8086/api/v1/prom/write?db=prometheus&u=prometheus&p=prometheuspwd"
remote_read: #读数据库
- url: "http://远程数据库ip:8086/api/v1/prom/read?db=prometheus&u=prometheus&p=prometheuspwd"
#配置数据源,称为target,每个target用job_name命名。又分为静态配置和服务发现
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['改为本机ip:9090']
- job_name: 'node-1' 这里指向了被监控主机 把那1000台主机的地址添加在node-1这个job里
scrape_interval: 15s
static_configs:
- targets: ['监控主机ip:9100']
- targets: ['...']
- targets: ['...']
配置文件2 普罗米修斯告警配置文件:alertmanager-rule.yml
自定义告警需要学习promQL
当可以看懂promQL后可以根据grafana模板里面的设置 自行更改为可用的参数然后用到告警里
groups 默认在第一行
- name 为一组告警的名字
rules: 这个是必要的格式不加会报错
- alert: 这个是此告警的名字
expr: 这里填写 promql 当这里的promql符合要求时就会触发告警
for: 可选参数当上面的告警持续多长时间后才触发报警 当符合告警条件但是没有到for时间时 此时这个告警处于不确定状态
annotations:
summary: "自定义信息" 其中 $labels.instance 这个变量时普罗米修斯自带变量为触发告警的服务器ip
$value 当报警时 这个值具体为多少
groups:
- name: prod_base_monitor
rules:
- alert: InstenceDown
expr: up == 0
for: 2m
annotations:
summary: "!特大事件!{{ $labels.instance }} 宕机"
- name: mem
rules:
- alert: HighMemoryUsage1
expr: (1 - (node_memory_MemAvailable_bytes{job="node-1"} / (node_memory_MemTotal_bytes{job="node-1"})))* 100 > 70
for: 10m
annotations:
summary: "!一般事件!{{ $labels.instance }} 内存使用率>70%已经持续10分钟
报警值是: {{ $value }}"
- alert: HighMemoryUsage2
expr: (1 - (node_memory_MemAvailable_bytes{job="node-1"} / (node_memory_MemTotal_bytes{job="node-1"})))* 100 > 80
for: 10m
annotations:
summary: "!重要事件!{{ $labels.instance }} 内存使用率>80%已经持续10分钟
报警值是: {{ $value }}"
- alert: HighMemoryUsage3
expr: (1 - (node_memory_MemAvailable_bytes{job="node-1"} / (node_memory_MemTotal_bytes{job="node-1"})))* 100 > 90
for: 10m
annotations:
summary: "!特大事件!{{ $labels.instance }} 内存使用率>90%已经持续10分钟
报警值是: {{ $value }}"
- name: cpu
rules:
- alert: HightCPUUsage1
expr: 100 - (avg by (instance)(irate(node_cpu_seconds_total{mode="idle"}[5m]))) * 100 > 70
for: 10m
annotations:
summary: "!一般事件!{{ $labels.instance }} CPU 使用率 > 70已经持续10分钟
报警值是: {{ $value }}"
- alert: HightCPUUsage2
expr: 100 - (avg by (instance)(irate(node_cpu_seconds_total{mode="idle"}[5m]))) * 100 > 80
for: 10m
annotations:
summary: "!重要事件!{{ $labels.instance }} CPU 使用率 > 80已经持续10分钟
报警值是: {{ $value }}"
- alert: HightCPUUsage3
expr: 100 - (avg by (instance)(irate(node_cpu_seconds_total{mode="idle"}[5m]))) * 100 > 90
for: 10m
annotations:
summary: "!特大事件!{{ $labels.instance }} CPU 使用率 > 90已经持续10分钟
报警值是: {{ $value }}"
- name: disk
rules:
- alert: HightDiskUsage1
expr: (node_filesystem_size_bytes{job='node-1',mountpoint="/rootfs"}-node_filesystem_free_bytes{job='node-1',mountpoint="/rootfs"})*100 /(node_filesystem_avail_bytes {job='node-1',mountpoint="/rootfs"}+(node_filesystem_size_bytes{job='node-1',mountpoint="/rootfs"}-node_filesystem_free_bytes{job='node-1',mountpoint="/rootfs"})) > 70
for: 10m
annotations:
summary: "!一般事件!{{ $labels.instance }} 磁盘使用率 > 70
报警值是: {{ $value }}"
- alert: HightDiskUsage2
expr: (node_filesystem_size_bytes{job='node-1',mountpoint="/rootfs"}-node_filesystem_free_bytes{job='node-1',mountpoint="/rootfs"})*100 /(node_filesystem_avail_bytes {job='node-1',mountpoint="/rootfs"}+(node_filesystem_size_bytes{job='node-1',mountpoint="/rootfs"}-node_filesystem_free_bytes{job='node-1',mountpoint="/rootfs"})) > 80
for: 10m
annotations:
summary: "!重要事件!{{ $labels.instance }} 磁盘使用率 > 80
报警值是: {{ $value }}"
- alert: HightDiskUsage3
expr: (node_filesystem_size_bytes{job='node-1',mountpoint="/rootfs"}-node_filesystem_free_bytes{job='node-1',mountpoint="/rootfs"})*100 /(node_filesystem_avail_bytes {job='node-1',mountpoint="/rootfs"}+(node_filesystem_size_bytes{job='node-1',mountpoint="/rootfs"}-node_filesystem_free_bytes{job='node-1',mountpoint="/rootfs"})) > 90
for: 10m
annotations:
summary: "!特大事件!{{ $labels.instance }} 磁盘使用率 > 90
报警值是: {{ $value }}"
配置文件3
创建/opt/webhook-dingtalk目录
在目录里创建default.tmpl 发送给钉钉告警的模板文件
{{ define "__subject" }}[{{ if eq .Status "firing" }}告警:{{ .Alerts.Firing | len }}{{ else }}恢复{{ end }}]{{ end }}
{{ define "__text_alert_list" }}
{{ if eq .Status "firing" }}
{{ range .Alerts.Firing }}
[告警时间]:{{ .StartsAt.Format "2006-01-02 15:04:05" }}
{{ range .Annotations.SortedPairs }} - {{ .Value | markdown | html }}
{{ end }}{{ end }}
{{ else if eq .Status "resolved" }}
{{ range .Alerts.Resolved }}
{{ range .Annotations.SortedPairs }} - {{ .Value | markdown | html }}
{{ end }}{{ end }}
{{ end }}
{{ end }}
{{ define "__alertmanagerURL" }}{{ end }}
{{ define "ding.link.title" }}{{ template "__subject" . }}{{ end }}
{{ define "ding.link.content" }}#### [{{ if eq .Status "firing" }}告警:{{ .Alerts.Firing | len }}{{ else }}恢复{{ end }}]
{{ template "__text_alert_list" . }}
{{ end }}
配置文件4
创建/opt/influxdb目录
在目录里创建 config 和 data 目录
在config目录里创建influxdb的配置文件 influxdb.conf
[meta]
dir = "/var/lib/influxdb/meta"
[data]
dir = "/var/lib/influxdb/data"
engine = "tsm1"
wal-dir = "/var/lib/influxdb/wal"
普罗米修斯需要通过alertmanager发送告警
如果你搭建普罗米修斯集群,不做alertmanager高可用的话,有一台服务器出现异常 而你有4个alertmanager 他就会发送4个一模一样的告警 会很烦的
只有一个告警的话显然时不适合生产环境使用的。。。但是我用docker做这个高可用时遇到了问题不会解决没办法 使用了软件包直接部署在本机
总之只要功能实现了就ok
如果不需要alertmanager高可用的话在docker-compose里添加
alertmanager:
image: prom/alertmanager
container_name: alertmanager
hostname: alertmanager1
restart: always
volumes:
- /opt/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml 配置文件5
- /etc/localtime:/etc/localtime
ports:
- "9093:9093"
networks:
- monitor
如果需要alertmanager高可用 要用软件包部署
wget https://github.com/prometheus/alertmanager/releases/download/v0.21.0/alertmanager-0.21.0.linux-amd64.tar.gz
将上面下载下来的包解压缩 然后将里面的文件全部移动到/opt/alertmanager/
alertmanager.yml配置文件改为 下面的 配置文件5
然后就是他的启动命令
--cluster.listen-address=自己的集群端口9094
--cluster.peer=需要进入集群的ip和端口9094
--config.file=配置文件路径
nohup /opt/alertmanager/alertmanager --cluster.listen-address="0.0.0.0:9094" --cluster.peer=另一台集群ip:9094 --cluster.peer=另一台集群ip:9094 --cluster.peer=另一台集群ip:9094 --config.file=/opt/alertmanager/alertmanager.yml &> /dev/null &
配置文件 5
/opt/alertmanager/alertmanager.yml
global:
resolve_timeout: 1m
route:
group_by: ['alertname']
group_wait: 5s
group_interval: 10s
repeat_interval: 3h
receiver: 'webhook'
receivers:
- name: 'webhook'
webhook_configs:
- url: 'http://本机ip:8060/dingtalk/webhook1/send'
目标3
搭建若干普罗米修斯server 把上面的docker-compose文件里的
influxdb:
image: influxdb:latest
container_name: influxdb
hostname: influxdb
restart: always
volumes:
- /opt/influxdb/config:/etc/influxdb 配置文件4
- /opt/influxdb/data:/var/lib/influxdb/data
- /etc/localtime:/etc/localtime
ports:
- "8086:8086"
- "8083:8083"
environment:
- INFLUXDB_DB=prometheus
- INFLUXDB_ADMIN_ENABLED=true
- INFLUXDB_ADMIN_USER=admin
- INFLUXDB_ADMIN_PASSWORD=adminpwd
- INFLUXDB_USER=prometheus
- INFLUXDB_USER_PASSWORD=prometheuspwd
- INFLUXDB_CONFIG_PATH=/etc/influxdb/influxdb.conf
logging:
driver: "json-file"
options:
max-size: "1g"
networks:
- monitor
删除
普罗米修斯主配置文件夹改为
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets: ["本机ip:9093"]
rule_files:
[ /etc/prometheus/alertmanager-rule.yml ]
scrape_configs:
- job_name: 'federate'
scrape_interval: 15s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job="prometheus"}'
- '{job="node-1"}'
static_configs:
- targets:
- '联邦普罗米修斯ip:9090'
然后去/opt/prometheus/
docker-compose up -d 启动他就可以了
访问grafana 地址 本机ip:3000
点击添加第一个数据源

添加自己的ip:9090端口

点击save & test 如果成功了即可

然后去导入模板文件

输入8919 点load
因为我添加过了 所以会报错
一个名字重复 一个随机码uid重复
选择普罗米修斯
点击import

点击左上角logo返回首页再点击下面的监控项就可以查看了


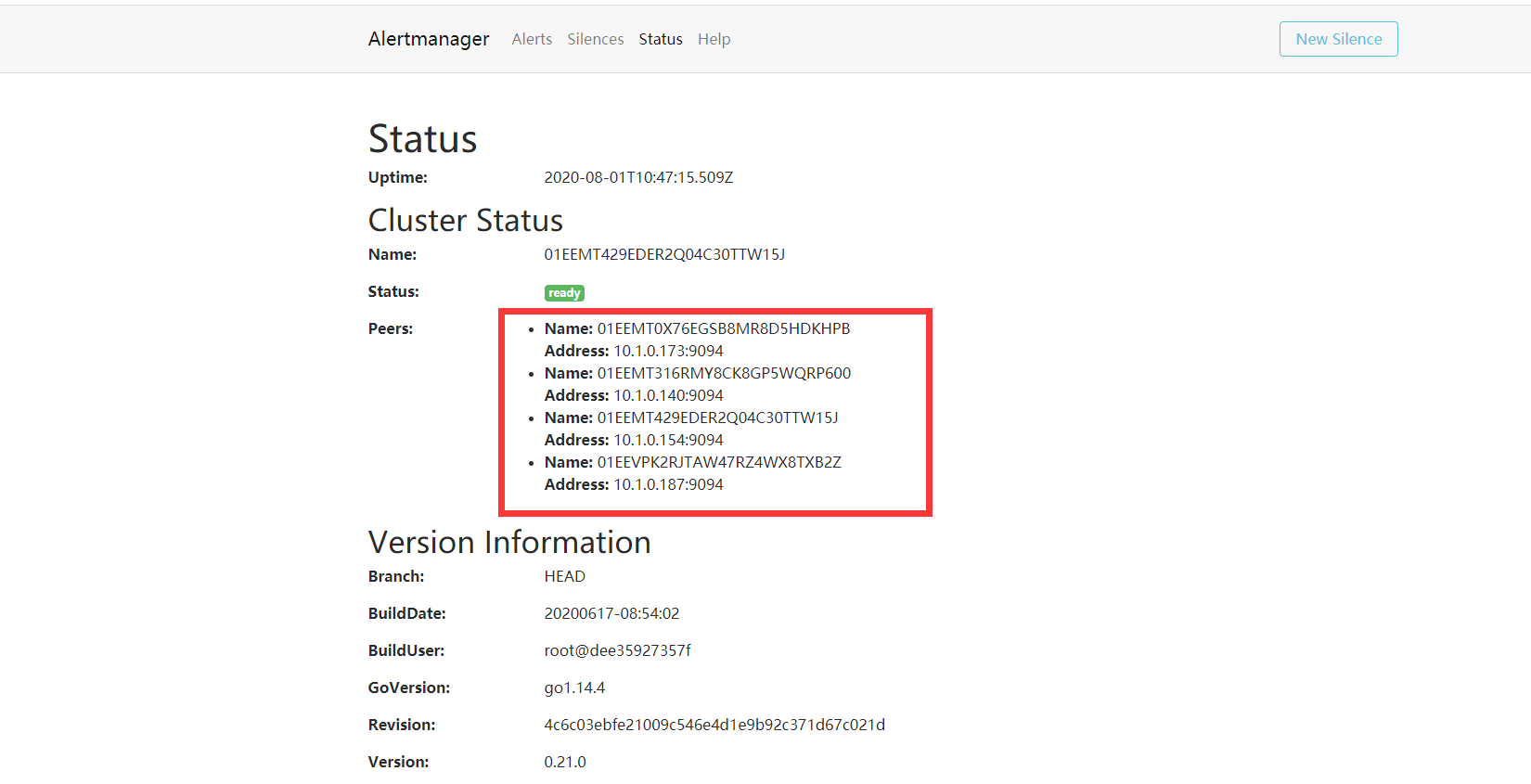
http://本机ip:9090/targets 是否正常收取信息 还没添加1000服务器

http://本机ip:9093/#/status alertmanager集群