-
一、元数据和元数据管理
- (1)元数据
在学习Ceph之前,需要了解元数据的概念。元数据又称为中介数据、中继数据,为描述数据的数据。主要描述数据属性的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。通俗地说,就 是用于描述一个文件的特征的系统数据,比如访问权限、文件拥有者以及文件数据库的分布信息(inode)等等。在集群文件系统中,分布信息包括文件在磁盘上的位置以 及磁盘在集群中的位置。用户需要操作一个文件就必须首先得到它的元数据,才能定位到文件的位置并且得到文件的内容或相关属性。
使用stat命令,可以显示文件的元数据
[root@ceph-node1 ~]# stat 1.txt File: ‘1.txt’ Size: 0 Blocks: 0 IO Block: 4096 regular empty file Device: 802h/2050d Inode: 33889728 Links: 1 Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root) Context: unconfined_u:object_r:admin_home_t:s0 Access: 2018-08-05 16:38:22.137566272 +0800 Modify: 2018-08-05 16:38:22.137566272 +0800 Change: 2018-08-05 16:38:22.137566272 +0800 Birth: - File:文件名 Size:文件大小(单位:B) Blocks:文件所占扇区个数,为8的倍数(通常的Linux扇区大小为512B,连续八个扇区组成一个block) IO Block:每个数据块的大小(单位:B) regular file:普通文件(此处显示文件的类型) Inode:文件的Inode号 Links:硬链接次数 Access:权限 Uid:属主id/属主名 Gid:属组id/属组名 Access:最近访问时间 Modify:数据改动时间 Change:元数据改动时间 以上的参数均属于文件的元数据,元数据即用来描述数据的数据。
- (2)元数据管理
元数据的管理方式有2种方式:集中式管理和分布式管理。
集中式管理是指在系统中有一个节点专门司职元数据管理,所有元数据都存储在该节点的存储设备上。所有客户端对文件的请求前,都要先对该元数据管理器请求元数据。
分布式管理是指将元数据存放在系统的任意节点并且能动态的迁移。对元数据管理的职责也分布到各个不同的节点上。大多数集群文件系统都采用集中式的元数据管理。
因为集中式管理实现简单,一致性维护容易,在一定的操作频繁内可以提供较为满意的性能。缺点是单一失效的问题,若该服务器失效,整个系统将无法正常 工作。而且,当对元数据的操作过于频繁时,集中的元数据管理会成为整个系统的性能瓶颈。
分布式元数据管理的好处是解决了集中式管理的单一失效点问题,而且性能不会随着操作频繁而出现瓶颈。其缺点是,实现复杂,一致性维护复杂,对性能有一 定的影响。
-
二、什么是Ceph?
Ceph是一种为优秀的性能、可靠性和可扩展性而设计的统一的、分布式的存储系统。Ceph 独一无二地用统一的系统提供了对象、块、和文件存储功能,它可靠性高、管理简便、并且是开源软件。 Ceph 的强大足以改变贵公司的 IT 基础架构、和管理海量数据的能力。Ceph 可提供极大的伸缩性——供成千用户访问 PB 乃至 EB 级的数据。 Ceph 节点以普通硬件和智能守护进程作为支撑点, Ceph 存储集群组织起了大量节点,它们之间靠相互通讯来复制数据、并动态地重分布数据。
-
三、Ceph的核心组件
Ceph的核心组件包括Ceph OSD、Ceph Monitor和Ceph MDS三大组件。
Ceph OSD:OSD的英文全称是Object Storage Device,它的主要功能是存储数据、复制数据、平衡数据、恢复数据等,与其它OSD间进行心跳检查等,并将一些变化情况上报给Ceph Monitor。一般情况下一块硬盘对应一个OSD,由OSD来对硬盘存储进行管理,当然一个分区也可以成为一个OSD。
Ceph Monitor:由该英文名字我们可以知道它是一个监视器,负责监视Ceph集群,维护Ceph集群的健康状态,同时维护着Ceph集群中的各种Map图,比如OSD Map、Monitor Map、PG Map和CRUSH Map,这些Map统称为Cluster Map,Cluster Map是RADOS的关键数据结构,管理集群中的所有成员、关系、属性等信息以及数据的分发,比如当用户需要存储数据到Ceph集群时,OSD需要先通过Monitor获取最新的Map图,然后根据Map图和object id等计算出数据最终存储的位置。
Ceph MDS:全称是Ceph MetaData Server,主要保存的文件系统服务的元数据,但对象存储和块存储设备是不需要使用该服务的。
查看各种Map的信息可以通过如下命令:ceph osd(mon、pg) dump
-
四、Ceph的架构
架构图:
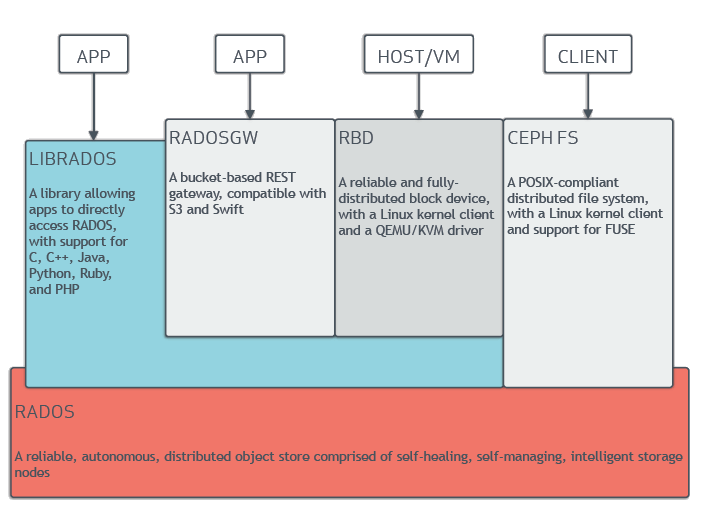
Ceph系统逻辑层次结构:
自下向上,可以将Ceph系统分为四个层次:
- (1)基础存储系统RADOS(Reliable, Autonomic, Distributed Object Store,即可靠的、自动化的、分布式的对象存储)
顾名思义,这一层本身就是一个完整的对象存储系统,所有存储在Ceph系统中的用户数据事实上最终都是由这一层来存储的。而Ceph的高可靠、高可扩展、高性能、高自动化等等特性本质上也是由这一层所提供的。因此,理解RADOS是理解Ceph的基础与关键。
- (2)基础库librados
这一层的功能是对RADOS进行抽象和封装,并向上层提供API,以便直接基于RADOS(而不是整个Ceph)进行应用开发。特别要注意的是,RADOS是一个对象存储系统,因此,librados实现的API也只是针对对象存储功能的。
RADOS采用C++开发,所提供的原生librados API包括C和C++两种。物理上,librados和基于其上开发的应用位于同一台机器,因而也被称为本地API。应用调用本机上的librados API,再由后者通过socket与RADOS集群中的节点通信并完成各种操作。
- (3)高层应用接口
这一层包括了三个部分:RADOS GW(RADOS Gateway)、 RBD(Reliable Block Device)和Ceph FS(Ceph File System),其作用是在librados库的基础上提供抽象层次更高、更便于应用或客户端使用的上层接口。
RADOS GW是一个提供与Amazon S3和Swift兼容的RESTful API的gateway,以供相应的对象存储应用开发使用。RADOS GW提供的API抽象层次更高,但功能则不如librados强大。因此,开发者应针对自己的需求选择使用。
RBD则提供了一个标准的块设备接口,常用于在虚拟化的场景下为虚拟机创建volume。目前,Red Hat已经将RBD驱动集成在KVM/QEMU中,以提高虚拟机访问性能。
Ceph FS是通过Linux内核客户端和FUSE来提供一个兼容POSIX的文件系统。
-
五、RADOS的存储逻辑架构
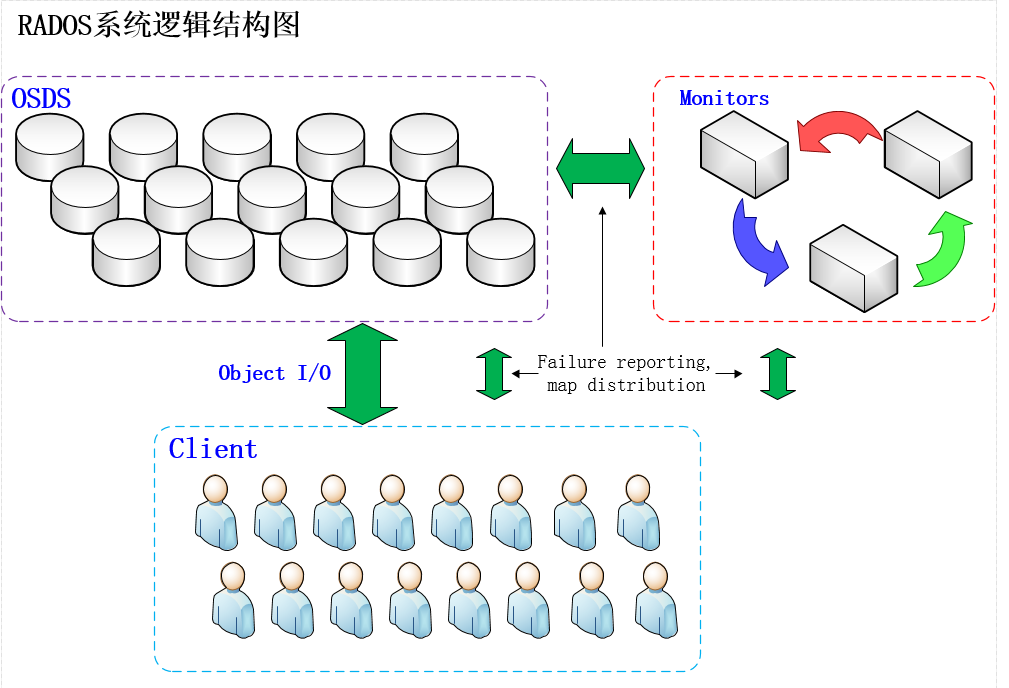
RADOS如图所示,RADOS集群主要由2种节点组成。一种是负责数据存储和维护功能的OSD,另一种则是若干个负责完成系统状态监测和维护的monitor。OSD和monitor之间相互传输节点的状态信息,共同得出系统的总体工作运行状态,并形成一个全局系统状态记录数据结构,即所谓的cluster map。这个数据结构和RADOS提供的特定算法相结合,便实现了Ceph“无需查表,算算就好”的核心机制和若干优秀特性。
在使用RADOS系统时,大量的客户端程序通过与OSD或者monitor的交互获取cluster map,然后直接在本地进行计算,得出对象的存储位置后,便直接与对应的OSD通信,完成数据的各种操作。可见,在此过程中,只要保证cluster map不频繁更新,则客户端显然可以不依赖于任何元数据服务器,不进行任何查表操作,便完成数据访问流程。在RADOS的运行过程中,cluster map的更新完全取决于系统的状态变化,而导致这一变化的常见事件只有两种:OSD出现故障,或者RADOS规模扩大。而正常应用场景下,这两种事件发生的频率显然远远低于客户端对数据进行访问的频率。