一、生产者负载均衡
1、分区器
使用分区器,kafka生产消息时,根据分区器将消息投递到指定的分区中。
Kafka默认的分区器时DefaultPartitioner。它的分区策略是根据key进行分配的。
如果key不为null: 对key值进行Hash计算,算出一个分区号; 拥有相同Key值被写入同一个分区;
如果key为null: 消息将以轮询方式,在所有可用分区中分别写入消息。
如果不想使用Kafka默认分区器,可以实现Partitioner接口,自己实现分区方法。
并非分区数量越多,效率越高:
Topic 每个 partition 在 Kafka 路径下都有一个自己的目录,该目录下有两个主要的文件:base_offset.log 和 base_offset.index。Kafka 服务端的 ReplicaManager 会为每个 Broker 节点保存每个分区的这两个文件的文件句柄。所以如果分区过多,ReplicaManager 需要保持打开状态的文件句柄数也就会很多。
每个 Producer, Consumer 进程都会为分区缓存消息,如果分区过多,缓存的消息越多,占用的内存就越大;
n 个分区有 1 个 Leader,(n-1) 个 Follower,如果运行过程中 Leader 挂了,则会从剩余 (n-1) 个 Followers 中选举新 Leader;如果有成千上万个分区,那么需要很长时间的选举,消耗较大的性能。
参考: https://blog.csdn.net/u010711495/article/details/113678248
二、消费者负载均衡
1、再均衡
再均衡是消费者层面的负载均衡
当一个group中,有consumer加入或者离开时,会触发partitions均衡,从而提升topic的并发消费能力。
引起消费者再平衡的情况
1、新的消费者加入消费组
2、某个消费者从消费组中退出(异常或正常)
3、增加订阅主题的分区(kafka的分区数,可以动态的增加,但不能减少)
4、某台broker宕机,新的协调器ZK当选
5、某个消费者在心跳会话时间内没有发送心跳请求(配置参数:session.timeout.ms), 组ZK认为该消费者已经退出。
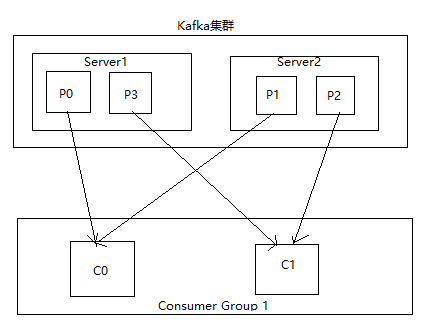
如下图所示,分区partitions有: P0, P1,P2,P3
加入group的消费者consumer有: C0, C1
流程如下:
1、 根据partitions索引号对partitions进行排序,P0, P1,P2,P3
2、根据consumer id排序,C0,C1
3、计算倍数 M = [P0, P1,P2,P3].size / [ C0, C1].size = 4 / 2 = 2;
4、然后依次分配Ci = [P(i * M),P((i + 1) * M -1)], 当i=0时, C0=[P0,P1]; 当i=1时, C1=[P2,P3]