Solr版本4.10.0
mmseg4j 2.2.0
1、为什么使用中文分词器
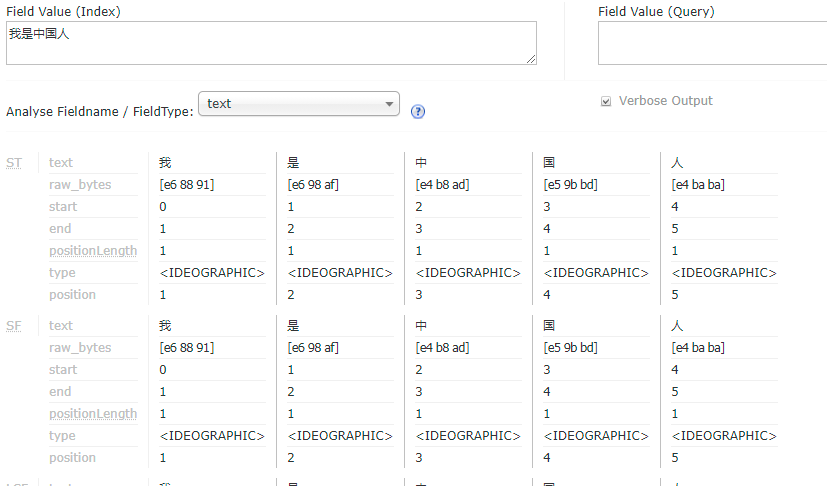
如上图所示,输入“我是中国人”,结果是将每个字进行了分词。这个显然不是我们想要的结果。
2、使用中文分词器mmseg4j
在工程中增加
<dependency>
<groupId>com.chenlb.mmseg4j</groupId>
<artifactId>mmseg4j-solr</artifactId>
<version>2.2.0</version>
</dependency>
然后将mmseg4j-core-1.10.0.jar 和 mmseg4j-solr-2.2.0.jar 拷贝到/home/tools/tomcat8.0.45/webapps/solr/WEB-INF/lib

3、配置schema.xml
vi /home/files/solrhome/collection1/conf/schema.xml
增加
<!-- mmseg4j -->
<fieldType name="text_zh" class="solr.TextField" positionIncrementGap="100">
<span style="white-space:pre"> </span><analyzer>
<span style="white-space:pre"> </span>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" />
<span style="white-space:pre"> </span></analyzer>
</fieldType>
假设字段叫my_content需要支持中文分词,只需要定义示例filed节点如下:
<field name="my_content" type="text_zh" indexed="true" stored="false" multiValued="true"/>
然后重启solr服务器
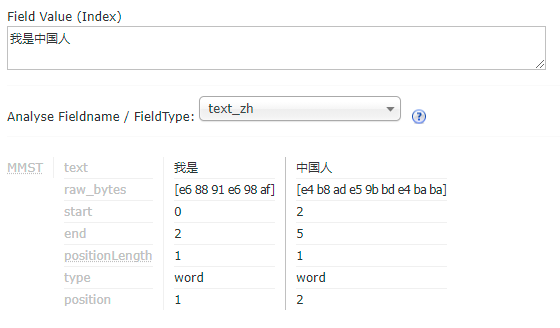
4、测试