1、Hive是什么
由Facebook开源,最初用于解决海量结构化的日志数据统计问题。
构建在Hadoop之上的数据仓库
Hive定义了一种类SQL查询语言: HQL(类似SQL但不完全相同)
通常用于进行离线数据处理(采用MapReduce)
底层支持多种不同的执行引擎(包括MapReduce、Tez、Spark)
支持多种不同的压缩格式(GZIP、LZO、Snappy、BZIP2)、存储格式(TextFile、SequenceFile、ORC、Parquet)以及自定义函数(UDF)。
2、为什么要使用Hive
简单、容易上手(提供了类似SQL查询语言HQL)
为超大数据集设计的计算/存储扩展能力(MR计算,HDFS存储)
统一的元数据管理(可与Presto/Impala/SparkSQL等共享数据)
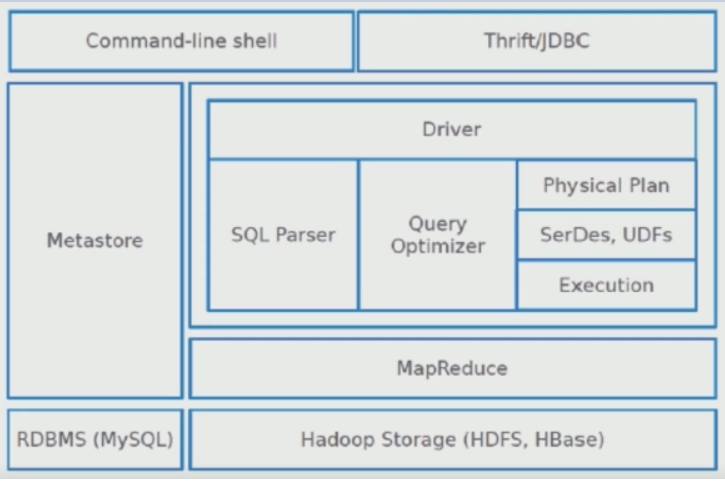
3、Hive体系架构
Hive部署架构-测试环境

Hive部署架构--生产环境
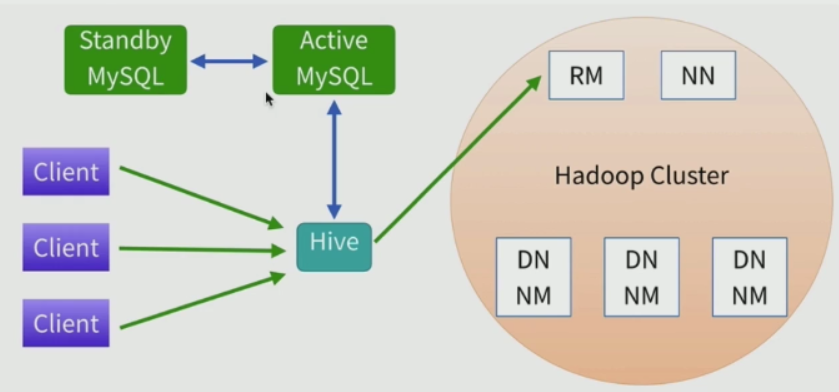
MySQL存放元数据,主备模式。
5、HIve环境搭建
1) Hive下载:
cd /home/tools
wget http://archive.cloudera.com/cdh5/cdh/5/hive-1.1.0-cdh5.7.0.tar.gz
tar -zxvf hive-1.1.0-cdh5.7.0.tar.gz
2) 配置环境变量
vi ~/.bash_profile
export HADOOP_HOME=/home/tools/hadoop-2.6.0-cdh5.7.0
export PATH=$HADOOP_HOME/bin:%PATH
export HIVE_HOME=/home/tools/hive-1.1.0-cdh5.7.0
export PATH=$HIVE_HOME/bin:$PATH
cd /home/tools/hive-1.1.0-cdh5.7.0/conf
cp hive-env.sh.template hive-env.sh
vi hive-env.sh
设置HADOOP_HOME=/home/tools/hadoop-2.6.0-cdh5.7.0
MySQL配置
前置条件: 安装一个MySQL,本机或者其它服务器上。

上传Mysql驱动 mysql-connector-java-5.1.29.jar到/home/tools/hive-1.1.0-cdh5.7.0/lib目录下
在conf下创建hive-site.xml
<configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/sparksql?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>xxx</value> </property> </configuration>
3) 启动Hive
cd /home/tools/hive-1.1.0-cdh5.7.0/bin
./hive

说明已经启动成功
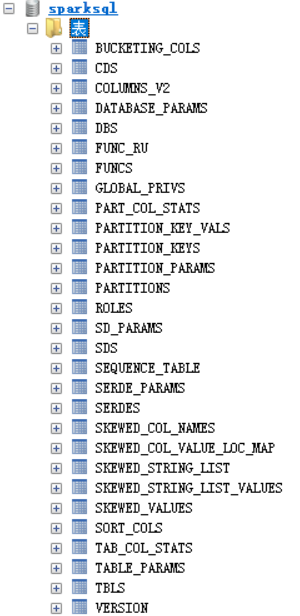
登录数据库,sparksql数据库已经创建好了

可以发现,创建了如下图所示的表