一、JOIN语句优化
join的种类有哪些? 彼此的区别?
join有哪些算法?
join语句如何优化
1、join的种类有哪些? 彼此的区别?
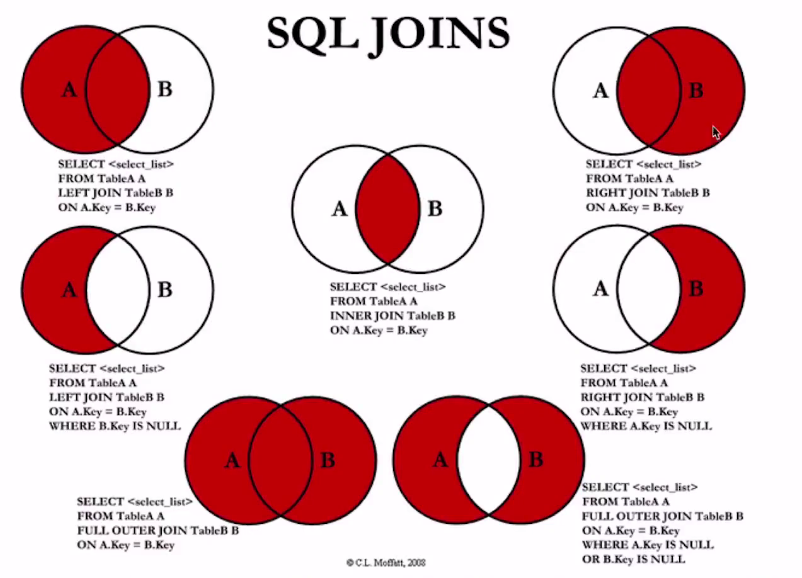
还有一种join
select * from A a corss join B b;
笛卡尔积连接。行数是A表和B表的乘积。
如果corss join带有on子句,就相当于inner join
select * from A a corss join B b where a.id = b.id ;
2、join有哪些算法?
JOIN算法1: Nested-Loop Join(NLJ) 嵌套循环
三张表

伪代码

JOIN算法2-Block Nested-Loop Join (BNLJ) 块循环嵌套Join

伪代码

引入join_buffer 降低了内层扫描的次数。
使用join buffer的条件
连接类型是All,index或range
第一个nonconst table(非常量表) 不会分配join buffer,即使类型是All或者index。
join buffer只会缓存需要的字段,而非整行数据。
可通过join_buffer_size 变量设置join buffer大小
每个能被缓存的join都会分配一个join buffer,一个查询可能有多个join buffer
补充: join buffer在连接之前分配,在执行查询之后释放。
如何知道一条SQL使用了BNLJ算法呢?

出现Using join buffer(Block Nested Loop) 表示使用了BNLJ。
JOIN算法3-Batched Key Access Join(BKA) 批量键值访问
MySQL 5.6 引入
BKA的基石: Multi Range Read(MRR)
MRR核心: 将随机IO转换成顺序IO,从而提升性能
MRR参数
1、optimizer_switch 的子参数
mrr: 是否开启mrr, on开启,off关闭
mrr_cost_based: 表示是否要开启基于成本计算的MRR
2、read_rnd_buffer_size: 指定mrr缓存大小
SHOW VARIABLES LIKE '%optimizer_switch%'
返回: *** mrr=on,mrr_cost_based=on ***
默认mrr是开启的,基于成本的mrr也是开启的。
SHOW VARIABLES LIKE '%read_rnd_buffer_size%'

默认是256K
JOIN算法4-HASH JOIN
MySQL 8.0.18引入,用来替代BNLJ
join buffer缓存外部循环的hash表,内层循环遍历时到hash表匹配
HASH JOIN注意点
1、MySQL 8.0.18才引入,且有很多限制,比如不能作用于外连接,比如left join/right join等等。从8.0.20开始,限制少了很多,建议使用8.0.20或者更高的版本
2、从MySQL 8.0.18开始,hash join的join buffer是递增分配的,这意味着,你可以为将join_buffer_size 设置的比较大。 而在MySQL 8.0.18中,如果你使用了外连接,
外连接没法使用hash join,此时join_buffer_size会按照你设置的值直接分配内存。因此join_buffer_size还得谨慎设置。
3、从MySQL 8.0.20开始,BNLJ已被删除了,用hash join代替了BNLJ
二、如何优化JOIN语句
1、启动表 vs 被驱动表
外层循环的表是驱动表,内存循环的表是被驱动表。
如下图,t1是t2的驱动表,t2是t1的被驱动表。t2是t3的驱动表,t3是t2的被驱动表。

2、JOIN调优原则
调优原则1
1) 用小表驱动大表
一般无需人工考虑,关联查询优化器会自动选择最优的执行顺序
如果优化器抽风,可使用STRAIGHT_JOIN
如何确定哪张表是小表,哪张表是大表?
EXPLAIN SELECT * FROM employees e
LEFT JOIN salaries s ON e.emp_no = s.emp_no
WHERE e.emp_no = 10001;

id都是1, 所以employees e 是驱动表。
EXPLAIN
SELECT * FROM employees e LEFT JOIN dept_emp de ON e.`emp_no` = de.`emp_no`
LEFT JOIN departments d ON de.`dept_no` = d.`dept_no`
WHERE e.`emp_no` = 10001

先操作e表,再操作de表,最后操作d表
2) 如果有where条件,应当要能够使用索引,并尽可能减少外层循环的数据量。
3) join的字段尽量创建索引
join字段的类型要保持一致(如一张表userId为int,另外一张表的userId为varchar),否则索引无法生效。
4) 尽量减少扫描的行数(explain-rows)
尽量控制在百万以内(经验之谈,仅供参考)
5) 参与join的表不要太多(因为扫描表的数据越多)
阿里编程规约建议不超过3张
如果业务要多张表的join,可以做如下修改
-- 拆分前 SELECT * FROM employees e LEFT JOIN dept_emp de ON e.`emp_no` = de.`emp_no` LEFT JOIN departments d ON de.`dept_no` = d.`dept_no` WHERE e.`emp_no` = 10001 -- 拆分后 SELECT * FROM employees WHERE emp_no = 10001 SELECT * FROM dept_emp WHERE emp_no = 10001 SELECT * FROM departments WHERE dept_no = 'd005'
这里是三张表,只是举个例子。一般三张表是可接受的。
6) 如果被驱动表的join字段用不了索引,且内存较为充足,可以考虑把join buffer设置得大一些。
join buffer可以降低内部循环次数,从而提高性能。