redis使用基础(六)
——Redis集群
(转载请附上本文链接——linhxx)
一、单台服务器
单台redis服务器,会出现单点故障,且需要承受所有的负载。另外,所有的内容都存在单个服务器上,该服务器会成为瓶颈。
使用多台服务器作为redis服务器,需要考虑集群管理,如数据一致性、增加节点、故障恢复等问题。redis对处理这些问题有一套方案。
二、复制
redis的持久化功能保证了数据的持久性,但是如果服务器故障,数据还是可能会丢失,因此需要将数据备份到其他服务器。当一台服务器内容更新,会通知其他服务器进行备份。
多台服务器使用redis时,有主数据库、从数据库的概念。通常主数据库是读写(或只有写操作),从数据库都是只读。主数据库数据的变化会通知从库,让从库进行更新。
1、命令
1)redis配置从数据库,只需要在从数据库配置文件中加入命令:slave of 主库ip 主库端口。该命令可以在开启数据库的时候使用,也可以在运行期间使用。
2)主数据库无需任何配置。
3)查看数据库的从库/主库命令:INFO replication,该命令返回当前库的角色(master/slave),对于主库还可以看到从库的数量、每个从库的ip与端口、当前连接开启的从库数量,对于从库可以看到主库的ip和端口。
2、注意事项
如果当前数据库已经是某个数据库的从库,再输入slave of 新主库,则会断开和当前主库的连接,并成为新主库的从库,且同步新主库的数据(如果现有数据新的主库也有,会被覆盖)。
运行期间输入slave of no one命令,使当前数据库与主库断开连接,并且自己成为主库。
3、原理
a. 复制初始化:
1)从数据库启动后,给主库发送sync命令。
2)主库接到命令后,会开始对当前数据保存快照(RDB持久化),且对保存期间客户端发送的写命令进行缓存。保存完毕后,将保存文件和缓存的写命令一起发给从数据库。
3)从数据库收到后,会还原快照,并且执行缓存命令。
复制初始化后,主数据库每当收到写命令,都会发送给从数据库。
断开连接后重连时,2.8之前的redis版本会重新进行一遍复制初始化;2.8开始的版本可以进行增量初始化,加快初始化速度。
b. 协议角度分析复制初始化:
1)从库使用命令连接主库,如果需要输入密码则还要和主库发送auth验证。
2)从库使用replconf listening-port 端口号告诉主库当前监听的端口号。
3)向主库发送sync命令开始同步。主库发送回快照文件和缓存命令,从库收到后写入硬盘的临时文件中。
4)写入完成后,从库会使用该rdb文件替换当前rdb文件。
5)在同步过程中,从库不会阻塞,可以接收客户端的命令。默认情况下,同步还没完成时,会用同步前的数据响应客户端。也可以通过配置文件slave-server-stable-data=no,强制要求同步完成后才可以提供服务,则此时同步期间收到客户端的请求会报错。
6)复制完成后,主数据库的任何写操作,从数据库都会收到异步的命令,并且去执行。
c. 乐观复制
redis采用乐观复制的策略,容忍一定时间内的数据差异,最终数据是一致的。
当主库收到写命令,会立即写完并反馈给客户端,再异步地向从数据库发送命令告知同步,因此存在差异的时间端口。可以配置从库至少连接几个时,主库才可写,通过配置文件的命令min-slaves-to-write。
4、图结构
从数据库不仅可以作为主库的从库,也可以作为其他从数据库的主库。
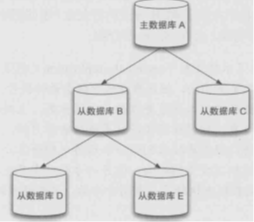
上图中A变化会同步给B和C,B变化会同步给D和E,但不会同步给A和C。
5、读写分离优势
正常的业务场景中,都是大量的读操作(远大于写操作),甚至带上计算(如sort)等场景,单个服务器很难应付,这是多个数据库的优势,保证主库仅进行写操作和同步数据,从库进行读操作,可以把工作量平均分配给从数据库。
6、从库持久化
持久化比较耗时,当有主从结构时,通常设置主库禁止持久化,由从库进行持久化操作。当主库奔溃时,使用以下方式进行还原:
1)将进行持久化的某台从库服务器,执行slave of no one,使其变成主库。
2)将重新恢复正常后的原主库,执行slave of 步骤1的从库,使其变成原从库的从库。
3)注意事项
主库设置关闭持久化后,一定要同时关闭自动重启功能。因为其没有持久化数据,关闭(无论正常还是异常关闭)后数据全部清空,如果此时自动重启,则所有的从库会同步数据,所有的数据都被清空。
7、无硬盘复制
使用rdb复制,简化逻辑,代码易复用,但是有以下缺点:
1)无法确定主库恢复数据的时间,因为快照的复制时间不确定。
2)复制初始化要在硬盘创建文件,如果硬盘性能差则会很慢(如网络硬盘)。
因此,redis2.8开始的版本,允许主库通过配置文件开启无硬盘复制,即对从库进行复制初始化时,直接通过网络传输给从库,而不是在主库的本地先生成rdb文件,再传输rdb。命令是 repl-diskless-sync yes
8、增量复制
a. 当从库断开重连,如果要全量复制,速度较慢。从redis2.8开始,支持增量复制。增量复制如下步骤:
1)从库存储主库的运行id(run id),每个redis实例有唯一运行id,重启后id会变。
2)复制过程中,主库把命令传给从库,并把命令存到挤压队列(backlog)中,记录当前挤压队列存放命令的偏移量。
3)从库接收到主库的命令后,会记录偏移量。
4)从库准备就绪后,从redis2.8开始,不再发送sync,而是发送psync 主库运行id断开前最新偏移量。
b. 主库收到psync后,会进行以下判断确定是否进行增量复制;
1)首先判断运行id是否正确,例如主库重启过则id会是新的。如果运行id不正确,则进行全量复制。
2)判断从库最后同步成功的命令是否在挤压队列中,在的话则可以进行增量复制,否则全量复制。
c. 挤压队列:
挤压队列本质是固定长度序列,大小为1MB,挤压队列越大,则允许断开的时间越长。通过repl-backlog-size设置挤压队列大小,通过repl-backlog-ttl设置全部从库断开连接后挤压队列释放的时间。
三、哨兵
redis2.8开始,提供稳定的哨兵,对redis的主从数据库进行自动化的系统监控和状态恢复。
1、概念
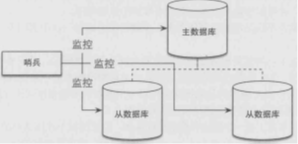
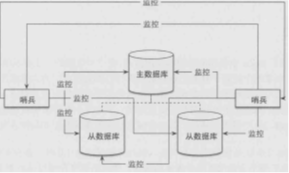
哨兵用于监控redis运行情况,监控主从数据库是否正常运行,并且在主库故障时将从库转换为主库。可以设置单个哨兵,也可以设置多个哨兵。
单个哨兵:
多个哨兵:
2、哨兵使用方式
现假设有一主二从数据库。哨兵建立方式如下:
1)建立配置文件,文件名可以任意,如sentinel.conf,里面的内容为:
sentinel monitor 主库名字(任意,只能是字母、数字、-、.、_) 主库ip 主库端口 主库投票数。
由于同一个主从系统可以多个哨兵检查,则投票数的目的在于当该哨兵认为主库主观下线,至少还要有 投票数-1 (因为包括当前哨兵)的哨兵认为是客观下线,才会换主库。
其中只需要配置主库,哨兵会自动获取从库。该文件可以有多行,每一行表示一个主库。设置多行表示检测多个主从系统。
除了monitor,还可以配置其他监控内容,通过主库名字区分监控的是哪个主从系统。
2)执行 sentinel进程,将配置文件传给哨兵:
redis-sentinel /sentinel.conf的路径/sentinel.conf
3)启动哨兵,可以看到哨兵的run id,输出+monitor表示监测到主库,+slave表示检测到从库。
哨兵执行过程如下:
1)主库关闭
如果将主库关闭(可以手动关闭或杀死进程),等待时间(默认30秒,可配置),会输出+sdown 主库ip 主库端口,表示哨兵主观认为主库停止服务。接着是+odown,表示哨兵客观认为主库停止服务。
当输出+odown后,哨兵会自动开始故障恢复,+try-failover开始修复,+failover-end表示修复完毕。修复完毕后,会重新设置一个主库,+switch-master 原主库名 原主库ip 原主库端口 新主库ip 新主库端口。接着,又会有+slave输出,表示检测到新主库的从库,原主库恢复连接后,也会被设置成新主库的从库。
2)从库关闭
从库如果被关闭,也会检测到+sdown,当从库再次开启,会检测到-sdown,并且会输出+convert-to-slave将重启后的从库再次设置为从库。
从库只有主观下线,没有客观下线。因为客观下线后需要重新选出新主库,这对于从库来说没有必要。
3、哨兵原理
1)哨兵进程启动时,通过读取上述提到的配置哨兵配置文件,确定主库的信息。当配置文件中有多行数据,表示是多个主从系统,哨兵也可以同时检测。
2)哨兵启动后,与要检测的主库建立两个连接,一个订阅来自主数据__sentine1__:hello频道,以获取其他监控该主库的哨兵信息;另一个用来给主库建立连接定期发送INFO等命令(这是因为考虑到主库可能会进入订阅模式,而无法执行其他命令,所有才用连接)。
3)连接建立后,进行如下操作:
a. 每10秒向主库发送INFO命令。
目的是获取当前主从系统的相关信息,如从库信息,比较上次发送的信息与当前的信息,确认主从库是否有故障。
b. 每2秒向主库与从库的__sentine1__:hello发送哨兵自身的信息。
目的是为了使各哨兵之间互相确认当前的检测范围,形成监测网。发送的内容包括哨兵地址、端口、运行id、配置版本,主库名字、地址、端口、配置版本。
当发现主库配置版本比较落后,还会更新主库的信息。
c. 每1秒向主从数据库以及其他哨兵发送ping命令。
目的是确认各库、各哨兵是否正常服务。1秒这个时间可以通过配置文件的字段进行配置,down-after-milliseconds,单位是毫秒。如果大于1秒则采用1秒,小于1秒则采用配置的数据。因此开启哨兵后,最少每秒会查看一次各库的情况。
4)判断各库是否下线
a. 当超过down-after-milliseconds时间,库没有回复,则认为其主观下线,即上述的检测到+sdown。
当下线的是主库,哨兵还会给其他哨兵发送命令,确认其他哨兵是否也认为主库主观下线,当达到指定数量(哨兵配置文件中主库的投票数,投票数含自身),则认为其客户下线(检测到+odown),此时重新选主库。
5)选举领头哨兵
多个哨兵确认主库客观下线,会选举出一个领头哨兵进行故障恢复,避免多个哨兵重复恢复。
选举领头哨兵,采用Raft算法,如下:
a. 发现主库客观下线的哨兵A,向其他哨兵发送命令,要求选举自己为领头哨兵。
b. 如果接到命令的哨兵,没有选过其他人,则选A。
c. 当A的票数超过哨兵的半数,且超过哨兵配置文件对该主库的投票数,则A称为领头哨兵。
由于要超过半数才能当领头哨兵,因此确保每次选举都只会选出一个领头哨兵。
d. 当多个节点参选领头哨兵,如果出现没有任何哨兵当选的情况,则每个哨兵随机等待一个时间,再重新发起请求。
6)故障恢复
领头哨兵挑选一个从库作为新的主库,挑选依据如下:
a. 所有在线从库,选择优先级最高的从库,优先级通过配置文件的slave-priority来设置。
b. 当多个从库优先级都一样且最高,则复制的偏移量越大,即增量复制时保存的数据相对约完整的,越优先。
c. 以上条件都一样,则选择运行id最小的从库作为新的主库。
7)后续步骤
a. 选出新主库,领头哨兵会向其发送slave of no one,让其成为主库,再向其他从库发送slave of命令,让其他从库称为该新主库的从库。
b. 将旧主库设置成为新主库的从库,使其重启后可以直接投入工作。
4、哨兵部署
哨兵以独立进程的方式进行监控,如果系统哨兵较少,可靠度则较低。因为哨兵本身也可能发生故障。因此,相对稳妥的方案:
1)为每个数据库(无论主从)都配置一个哨兵。
2)使每个哨兵与其对应节点网络环境相似。
但是,redis不支持连接复用,配置过多哨兵会有太多的冗余连接;另外redis负载高时会影响其对哨兵的回复以及哨兵和其他哨兵的通信。
因此要根据实际情况设置哨兵。
四、集群
1、分片方式
当主从结构的每个库都存储全量数据,则导致该主从系统的最大存储量被最小存储的redis服务器限定,形成木桶效应。
因此可以对redis进行水平扩容。由于redis轻量级,因此可以预先分足够多数量的片,并在存储的时候客户端采用某一算法将数据平均分配到不同的redis中。当数据量小的时候,每个片占用的内存都不多;当数据量很大时,也只需要将部分redis迁移到其他服务器即可。
2、集群概述
分片方式维护成本高,从redis3.0开始,集群是更好的解决方案。集群拥有和单机一样的性能,网络分区后提供可访问性,提供主库故障恢复支持。
集群支持所有单机执行的命令,对于多键命令(如MGET),如果多键都在同一个集群节点则正常返回,否则报错。另外,集群只支持0号数据库,如果使用select选择数据库也会保存。
3、配置集群
1)将每个节点设置成可集群
将每个数据库配置文件的cluster-enabled 开启(设置成yes)即可。每个集群至少要三个数据库才可能正常运行。
集群会将当前节点记录的集群状态持久化存储在指定文件中,默认是当前工作目录下的nodes.conf文件。但是,要求每个节点文件不同,否则会报错。因此,需要在开启节点前,设置节点的持久化路径,通过配置文件的命令cluster-config-file /路径/nodes.conf。
连接上任一集群,通过INFO cluster命令,可以判断该集群是否可用。返回值中如果cluster_enabled:1,则表示可用。
该配置生效后,表示该节点是一个独立的节点,还未加入集群。
2)redis-trib.rb
redis源码提供的一个文件,用于协助节点加入集群,由于是ruby写的,因此需要节点环境安装配置ruby,另外还需要gem包redis,通过gem install redis进行安装。
3)初始化集群
/redis-trib.rb的路径/redis-trib.rb create --replicas 1 ip1:port1 ip2:port2 ip3:port3 ip4:port4 ip5:port5 ip6:port6
其中--replicas 1表示集群中每个主库一个从库,该命令会将ip1、2、3的库设置为主库,4、5、6设置为从库。
也可以同一个ip的不同port加入集群。
4)集群创建的详细过程
a. redis-trib.rb以客户端形式连接所有节点,发送ping命令,如果有任何节点无法正常服务,则集群建立失败。接着,发送INFO命令,确定每个节点的运行id以及是否开启集群。
b. 向每个节点发送cluster meet命令,格式cluster meet ip port,告诉当前节点指定ip:port的节点也是集群的一个节点。从而使各ip归入一个集群。
c. 分配主从数据库节点,原则是尽量让每个主库运行在不同ip,确保系统容灾能力。
d. 为每个主库分配插槽,实质就是分配哪些键归哪些节点负责。
e. 为每个将要成为从库的库,发送命令CLUSTER REPLICATE 主库运行ID,将当前节点转换成从库,并复制数据。
上述步骤后,集群创建完成,连接上任意节点,输入命令CLUSTER NODES,可以查看集群的情况,包括每个节点运行id、地址、端口、角色、状态、插槽等。
4、节点增加
向加为节点的redis(下面称为A),发送命令CLUSTER MEET ip port,其中ip和端口是目前集群中的任一节点(下面称为B)。
A接到命令后,会与B进行握手,使B认为A是集群的一员。接着,B会使用Gossip协议,将A的信息通知集群的其他节点。
5、插槽(Slot)分配
新节点可以执行cluster replicate成为某个主节点的从节点,也可以申请一个插槽作为主节点运行。
1)键与插槽的关系
redis将每个键的键名有效部分用CRC16算法,计算散列值,再取对16384的余数。这样使每个键都可以分配到16384个插槽中。进而分配指定节点处理。因此,集群最大节点数量是16384,通常建议在1000左右。
有效键名指:
a. 如果键名包含{,且后面有},且{}之间至少1个字符,则有效键名是{}之间的内容。
b. 如果不满足上述条件,则键名是整个数据。
这样做的好处在于,可以把某个系统都设置成一样的,例如{order}:id,{order}:user:orderid,这两个键由于都有{},且里面的内容不止1个字符,因此有效键名都是order,则会被分配到1个节点进行存储,也就可以使用MGET等批量操作进行查询。
2)插槽分配指定节点
a. 插槽没有分配过
在要分配的节点,执行命令cluster add slot1 [slot2 slot3….]进行分配,如果某个插槽已经分配节点,会报错。
可以通过cluster slots查看当前插槽的情况。
b. 分配过的插槽重新分配
可以使用redis-trib.rb reshard 待分片ip:端口,然后跟着命令提示输入迁移插槽数量、迁移至的运行id、迁移前的运行id,完成迁移。(推荐使用此方法)
也可以直接执行命令:cluster set slots 插槽号 node 新的运行id。但是由于迁移不会把键也迁移过去,因此如果插槽里面有键会丢失,所以要按下列方式进行迁移。
a. 获取插槽存在的所有键:cluster getkeysinslot 插槽号 要返回键的数量
b. 对每个键迁移:migrate 目标节点地址 目标节点端口 键名 数据库号码 超时时间 [copy] [replace]。[copy]则表示不删除当前键,是在新地址建立副本;[replace]表示目标地址如果有同名的键,则覆盖目标地址的同名键。
c. 重新分配插槽:cluster setslots 插槽号 node 新的运行id。
3)迁移过程的数据问题
迁移过程中,如果时间较久,可能会存在数据不一致问题。redis提供解决方案,实现集群在线情况下的插槽迁移。
命令:
cluster setslot 插槽号 migrating 新节点的运行id
cluster setslot 插槽号 importing 新节点的运行id
如果要把0号插槽从A移到B,需要如下操作(redis-trib.rb的方案):
a. B执行 cluster setslot 0 importing A
b. A执行 cluster setslot 0 migrating B
c. 执行cluster getkeysinslot 0获取0号插槽的键列表
d. 对第三步的每个键执行migrate,迁移键
e. cluster setslots 0 node B 完成迁移
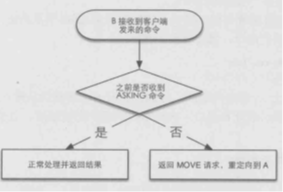
即多了a、b两个步骤,执行完前两步时,客户端A请求插槽0中的键时,如果键存在(未迁移),则正常处理;如果不存在,则返回ASK跳转请求,告诉客户端键在B。客户端接到ASK后,向B发送ASKING,再发送请求数据的命令。
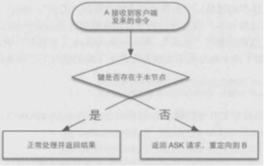
相反,如果客户端向B发送请求,如果有ASKING,则返回数据,否则B返回MOVED跳转,要求客户端去A请求数据。
6、获取键对应的插槽
客户端发送请求键的操作,如果某个节点有该键,则返回;否则返回重定向请求。这个重定向请求,如果开发语言已经封装,则对于开发者是透明的,相当于单机。如果没有封装,则需要手工实现重定向。
重定向的返回:MOVED 插槽号 IP:port,客户端收到重定向后,需要重定向到IP:port的地方,去进行键的相关操作。
redis-cli模式下,在对节点进行初始化连接的时候,加上-c参数,如果后续客户端发送过来该阶段不存在的键,会自动重定向。
优化:
重定向使得原本一次连接可以完成的操作,需要两次连接。反复这样会影响性能,通常需要客户端缓存插槽信息,后面就直接往相应的插槽发送数据。
7、故障恢复
集群内的每个节点,每秒都会随机选5个节点,再选这5个节点中最久没有响应的节点发送ping命令。如果一定时间内没有回复,会被认为疑似下线(PFAIL),与哨兵的主观下线相类似,如果要真正确认节点下线,还需要一定数量的节点认为该阶段疑似下线。
过程如下:
1)节点A认为节点B疑似下线,会和集群的其他节点广播。
2)当集群中的某一节点C收到集群中半数以上的节点认为B疑似下线,则确认B下线,并进行广播。
当集群中的一个主库下线,至少需要1个从库顶上,因此,集群中每个主库至少要有一个从库。
选择哪个从库作为新主库,和哨兵的方式一样,Raft算法,如下:
1)发现主库下线的从库A,向集群其他节点发送请求,要求称为主库。
2)集群的其他节点如果没有选其他的从库,则选A作为主库。
3)A发现集群半数以上节点选A做主库,则A就成为主库。
4)当多个库参选,出现没有库可以当选主库的情况,则这些库都随机等待一个时间再发送请求。
当某个从库变成主库后,会通过命令Slave of no one将自己变成主库,并把旧主库的插槽转给自己负责。
当某个主库负责1个以上的插槽,且该主库下线,且没有可用的从库时,默认情况认为该集群已经不可用,集群下线。如果希望集群不下线继续工作,可以通过配置文件cluster-require-full-coverage no(默认是yes)。
——written by linhxx
更多最新文章,欢迎关注微信公众号“决胜机器学习”,或扫描右边二维码。