ng机器学习视频笔记(十三)
——推荐系统基础理论
(转载请附上本文链接——linhxx)
一、概述
推荐系统(recommender system),作为机器学习的应用之一,在各大app中都有应用。这里以用户评价电影、电影推荐为例,讲述推荐系统。
最简单的理解方式,即假设有两类电影,一类是爱情片,一类是动作片,爱情片3部,动作片2部,共有四个用户参与打分,分值在0~5分。
但是用户并没有对所有的电影打分,如下图所示,问号表示用户未打分的电影。另外,为了方便讲述,本文用nu代表用户数量,nm代表电影数量,r(i,j)=1表示用户j给电影i评价,y(i,j)表示用户j给电影i的打分(当r(i,j)=1时这里的值才有效)。
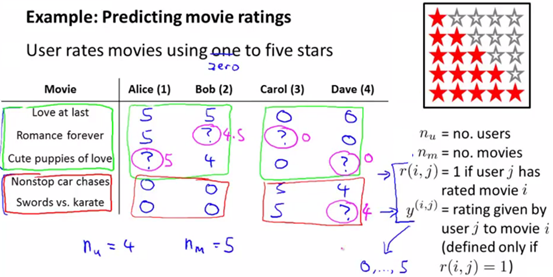
前三部是爱情片,用户Alice给前两部爱情片都5分,根据直接判断,其打5分的概率很高。
下面首先就要解决用机器学习来预测打分的问题,进而讨论电影的相关性问题。
二、基于内容的推荐系统
1、简要描述
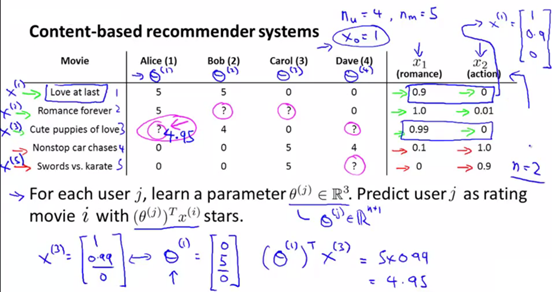
还是上面的几个人和几个电影,现假设已知每部电影的爱情属性和动作属性,分别用x1和x2表示每部电影的这两个特征值,加上x0=1,则该场景变为线性回归场景。即需要预测出用户对每种类型电影的喜好程度矩阵θ,进而在已知某种用户未打分的电影的特征x的情况下,用θTx预测用户可能给该电影打分的分值。
下图假设已求出用户的θ=[0 5 0]T,第一个数0对应x0没有实际意义,第二个数5表示用户对爱情片的喜欢程度,第三个数0表示用户对动作片的喜好程度。则可以预测出,该用户对第三部电影的打分,可能4.95。如下图所示:
2、计算单个用户的θ
列出类型线性回归的代价函数,但是在推荐系统中,有一些和线性回归的代价函数不太一样的地方:
1)求和的时候,只计算用户已经打过分的电影,忽略未打分的电影。未打分的无法参与计算。
2)不需要除以用户已打过分的电影的数目。这里是常量,忽略对结果影响不大。

3、计算所有用户的θ
每个用户去计算,要列很多公式,比较繁琐,这里可以把公式合并,一次性求出所有的用户对应的θ,即在代价函数的地方,累加上所有用户,同时正则化项也需要累加。

接着,就用梯度下降算法,进行计算。

这部分内容和线性回归完全一致,区别只有代价函数的列式不太一样,梯度下降部分完全一致。
这里基于内容的推荐,可以认为给定样本的特征x,求θ的过程。
三、基于用户评论的预测
现在考虑到,由于现实中并不一定会给每个电影都有特征标签,并且特征的数量可能非常多,但是考虑到已经有很多用户已经打分,现在反求每个电影的特征。
这里可以理解为给定用户对不同特征的喜好程度θ,求样本的特征的过程。如下图所示:

实际求解过程也很简单,只要把x当作变量,θ当作已知值,反过来列代价函数,进而再用梯度下降求出x即可。

四、协同过滤算法
上面的两个问题,有点像鸡生蛋还是蛋生鸡的问题,可以看出x和θ,只要知道一个内容,就可以求出另一个内容。进而,可以用求出的内容,反过来再优化原来的内容。相当于可以形成一个θ->x->θ->x……的链。
这里,首先由用户对电影评分,因此可以认为多个用户对电影的评分,致使计算出电影的特征,而特征又反过来进一步优化对用户评分的预测。
对于公式上,考虑将两个公式整合成一个,再分别对θ和x求偏导数,进行梯度下降,则可以得到θ和x。
这样的计算方式,则成为协同过滤算法(collaborative filtering algorithm)。
公式如下:

五、向量化实现
现在回到一开始的问题,怎么判断两个电影是否类型相似,进而给用户推荐相似类型的电影。
前提条件还是之前的,知道部分用户对电影的打分,未知电影的类型,如下图所示:
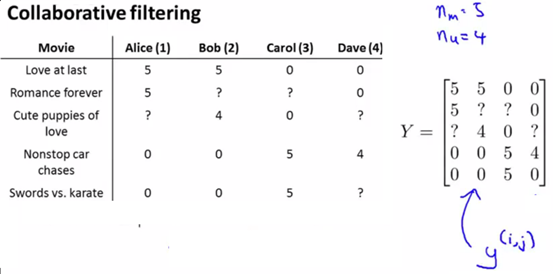
此时,可以用到向量化实现技术(vectorization implementation),简单来说,即用上面的协同过滤计算出x和θ后,将x和θ都表示成矩阵,并且用xθT得到预测矩阵,可以预测出每个用户对每种电影的打分,以及预测出电影的特征,矩阵如下图所示:

这个称为低秩矩阵分解(low rank matrix factorization)。
此时,要判断两个电影是否相似,则很简单,只要计算电影i和电影j对应的特征矩阵的距离||x(i)-x(j)||,当这个值越小,则表示这两部电影越相似。
六、均值归一化
1、现有问题
现考虑一个问题,当来了一个新用户,他没有对任何电影打分。此时如果用协同过滤算法,由于其没有任何的打分,则代价函数中,会只剩下θ平方和正则化项,另外两项都会为0。
因此,当需要对θ进行代价函数最小化求解,会得到θ=0时代价函数最小(显然的事情),结果就是会预测出用户对所有电影的评分都是0分。这个有违常理。

2、解决问题
为了解决问题,引入均值归一化(mean normalization),步骤如下:
1)设矩阵Y表示所有用户对所有电影的打分,为打分的电影用?表示。
2)在已打分的电影中,计算每个电影的分数均值。计算方式即打分的总数除以打分的总人数。设 这个矩阵为μ。
3)令Y=Y-μ,得到一个新的矩阵,其中?部分仍为?。
4)用这个新的Y去进行协同过滤算法,求出x和θ。
5)此时对于某个用户,可以预测结果是(θ(j))Tx(i)+μ(i),要加上对应的μ,是因为一开始扣除了μ。

根据上述的计算,得出的新用户的预测结果,会是均值。这个可以简单的推出,因为结果是(θ(j))Tx(i)+μ(i),而显然(θ(j))Tx(i)=0(因为这个用户之前没有任何预测,θ=0),故只会剩下μ值。
这样,对于每一个新用户,在还没进行评价之前,会预测其对每个电影的评价是均值,这也就表示给新用户推荐电影时,会按均值,把均值较高的电影推荐给用户,这个比较符合常理。
七、总结
这里的推荐系统,可以算是一个引子,只介绍了推荐系统的一些基础思想,对于真正完整的推荐系统,还有需要内容等待探索。后续我也会继续这方面的学习。
——written by linhxx
更多最新文章,欢迎关注微信公众号“决胜机器学习”,或扫描右边二维码。