1 准备数据:
1.1 t_1
01 张三
02 李四
03 王五
04 马六
05 小七
06 二狗
1.2 t_2
01 11
03 33
04 44
06 66
07 77
08 88
1.3 t_3
01 男
02 男
03 女
04 男
05 女
06 女
07 男
08 X
2 创建表:t_1,t_2,t_3
create table if not exists t_1(id string,name string)row format delimited fields terminated by ' ';
create table if not exists t_2(id string,score string)row format delimited fields terminated by ' ';
create table if not exists t_3(id string,sex string)row format delimited fields terminated by ' ';
3 加载数据
load data local inpath '/root/tmp/t_1' into table t_1;
load data local inpath '/root/tmp/t_2' into table t_2;
load data local inpath '/root/tmp/t_3' into table t_3;
4 笛卡尔积:Join
select * from t_1 join t_2;
等价于:
select * from t_1,t_2;

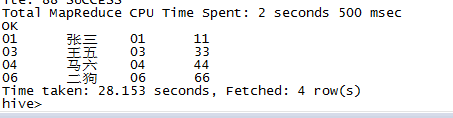
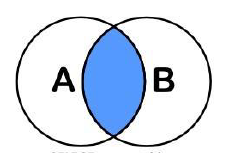
5 等值连接:Join ... on(查交集)
select * from t_1 t1 join t_2 t2 on t1.id=t2.id;
图解原理:

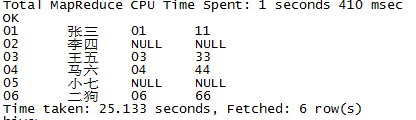
5 左连接: left join ... on ...
左连接是显示左边的表的所有数据,如果有右边表的数据与之对应,则显示;否则显示null
select * from t_1 t1 left join t_2 t2 on t1.id=t2.id;
图解原理:
6 右连接: right join ... on ...
与左连接类似,右连接是显示右边的表的所有数据,如果有左边表的数据与之对应,则显示;否则显示null
select * from t_1 t1 right join t_2 t2 on t1.id=t2.id;
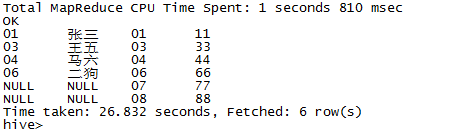
图解原理:
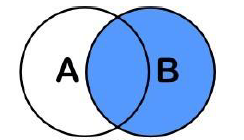
7 全连接:full outer join ... on
相当于t_1和t_2的数据都显示,如果没有对应的数据,则显示Null.
select * from t_1 t1 full outer join t_2 t2 on t1.id=t2.id;

图解原理:
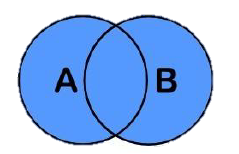
8 左半连接:semi join
semi join仅会显示t_1的数据,即左边表的数据。效率比左连接快,因为它会先拿到t_1的数据,然后在t_2中查找,只要查找到结果立马就返回t_1的数据。
select * from t_1 t1 left semi join t_2 t2 on t1.id=t2.id;
图解原理:
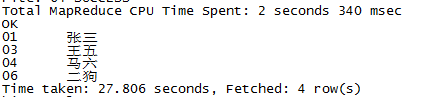
9 用单次MapReduce实现连接:
如果在连接中使用了公共键,Hive还支持通过一次MapReduce来连接多个表。
select t1.*,t3.sex,t2.score from t_1 t1 join t_3 t3 on t1.id=t3.id join t_2 t2 on t2.id=t1.id;
