本节重点:
完整性约束的作用 :能保证数据的完整性与一致性
- not null 与 default
- unique
- primary
- auto_increment
- foreign key
not null 与default:
not null 是指 不为空 必须设定值
default 是指 默认值 可以设定默认值


create table tb1( #创建一个表 nid int not null defalut 2, #nid 是整数类型 不为空 默认值为2 num int not null #变量数 为整数型 不能为空 );
mysql> create table student2( -> id int not null, -> name varchar(50) not null, -> age int(3) unsigned not null default 18, -> sex enum('male','female') default 'male', -> fav set('smoke','drink','tangtou') default 'drink,tangtou' -> ); Query OK, 0 rows affected (0.01 sec) # 只插入了not null约束条件的字段对应的值 mysql> insert into student2(id,name) values(1,'mjj'); Query OK, 1 row affected (0.00 sec) # 查询结果如下 mysql> select * from student2; +----+------+-----+------+---------------+ | id | name | age | sex | fav | +----+------+-----+------+---------------+ | 1 | mjj | 18 | male | drink,tangtou | +----+------+-----+------+---------------+ 1 row in set (0.00 sec)
unique:
单列唯一:
举例说明:创建公司部门表(每个公司都有唯一的一个部门)。
#第一种创建unique的方式 #例子1: create table department( id int, name char(10) unique ); mysql> insert into department values(1,'it'),(2,'it'); ERROR 1062 (23000): Duplicate entry 'it' for key 'name' #例子2: create table department( id int unique, name char(10) unique ); insert into department values(1,'it'),(2,'sale'); #第二种创建unique的方式 create table department( id int, name char(10) , unique(id), unique(name) ); insert into department values(1,'it'),(2,'sale');
联合唯一:
# 创建services表 mysql> create table services( -> id int, -> ip char(15), -> port int, -> unique(id), -> unique(ip,port) -> ); Query OK, 0 rows affected (0.05 sec) mysql> desc services; +-------+----------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+-------+ | id | int(11) | YES | UNI | NULL | | | ip | char(15) | YES | MUL | NULL | | | port | int(11) | YES | | NULL | | +-------+----------+------+-----+---------+-------+ 3 rows in set (0.01 sec) #联合唯一,只要两列记录,有一列不同,既符合联合唯一的约束 mysql> insert into services values -> (1,'192,168,11,23',80), -> (2,'192,168,11,23',81), -> (3,'192,168,11,25',80); Query OK, 3 rows affected (0.01 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> select * from services; +------+---------------+------+ | id | ip | port | +------+---------------+------+ | 1 | 192,168,11,23 | 80 | | 2 | 192,168,11,23 | 81 | | 3 | 192,168,11,25 | 80 | +------+---------------+------+ 3 rows in set (0.00 sec) mysql> insert into services values (4,'192,168,11,23',80); ERROR 1062 (23000): Duplicate entry '192,168,11,23-80' for key 'ip'
primary key:
一个表中可以:
单列做主键
多列作主键(复合主键)
约束:等价于 not null unique 字段的值不为空且唯一
存储引擎默认是innodb: 对于innodb存储引擎来说,一张表只能有一个主键
单列主键
# 创建t14表,为id字段设置主键,唯一的不同的记录 create table t14( id int primary key, name char(16) ); insert into t14 values (1,'xiaoma'), (2,'xiaohong'); mysql> insert into t14 values(2,'wxxx'); ERROR 1062 (23000): Duplicate entry '6' for key 'PRIMARY' # not null + unique的化学反应,相当于给id设置primary key create table t15( id int not null unique, name char(16) ); mysql> create table t15( -> id int not null unique, -> name char(16) -> ); Query OK, 0 rows affected (0.01 sec) mysql> desc t15; +-------+----------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+-------+ | id | int(11) | NO | PRI | NULL | | | name | char(16) | YES | | NULL | | +-------+----------+------+-----+-
复合主键:
create table t16( ip char(15), port int, primary key(ip,port) ); insert into t16 values ('1.1.1.2',80), ('1.1.1.2',81);
auto_increment:自增长
1 约束的字段为自动增长,约束的字段必须同时被key约束
# 创建student create table student( id int primary key auto_increment, name varchar(20), sex enum('male','female') default 'male' ); mysql> desc student; +-------+-----------------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+-----------------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | varchar(20) | YES | | NULL | | | sex | enum('male','female') | YES | | male | | +-------+-----------------------+------+-----+---------+----------------+ 3 rows in set (0.17 sec) #插入记录 mysql> insert into student(name) values ('老白'),('小白'); Query OK, 2 rows affected (0.01 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql> select * from student; +----+--------+------+ | id | name | sex | +----+--------+------+ | 1 | 老白 | male | | 2 | 小白 | male | +----+--------+------+ 2 rows in set (0.00 sec)
2 对于自增长的字段,在用delete删除后 再次添加新的数据是在原来删除前的位置进行自增长
mysql> delete from student; Query OK, 5 rows affected (0.00 sec) mysql> select * from student; Empty set (0.00 sec) mysql> select * from student; Empty set (0.00 sec) mysql> insert into student(name) values('ysb'); Query OK, 1 row affected (0.01 sec) mysql> select * from student; +----+------+------+ | id | name | sex | +----+------+------+ | 9 | ysb | male | +----+------+------+ 1 row in set (0.00 sec) #应该用truncate清空表,比起delete一条一条地删除记录,truncate是直接清空表,在删除大表时用它 mysql> truncate student; Query OK, 0 rows affected (0.03 sec) mysql> insert into student(name) values('xiaobai'); Query OK, 1 row affected (0.00 sec) mysql> select * from student; +----+---------+------+ | id | name | sex | +----+---------+------+ | 1 | xiaobai | male | +----+---------+------+ 1 row in set (0.00 sec) mysql>
总结 :自增长需要注意的问题是 1 设定完自增长以后 因为auto_increment是与primary key配合使用的,所以数据会自动默认从1开始自增加
2 插入数据时依旧可以自己设定数据
3 删除问题 注意区分delete与truncate的区别,delete删除后如果新增数据 自增长会在原有的基础上进行,truncate会现存的数据基础上进行自增长.
了解:auto_increment_increment,默认起始值与auto_increment_offset 默认偏移量
查看可用的 开头auto_inc的词 mysql> show variables like 'auto_inc%'; +--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | auto_increment_increment | 1 | | auto_increment_offset | 1 | +--------------------------+-------+ 2 rows in set (0.02 sec) # 步长auto_increment_increment,默认为1 # 起始的偏移量auto_increment_offset, 默认是1 # 设置步长 为会话设置,只在本次连接中有效 set session auto_increment_increment=5; #全局设置步长 都有效。 set global auto_increment_increment=5; # 设置起始偏移量 set global auto_increment_offset=3; #强调:If the value of auto_increment_offset is greater than that of auto_increment_increment, the value of auto_increment_offset is ignored. 翻译:如果auto_increment_offset的值大于auto_increment_increment的值,则auto_increment_offset的值会被忽略 # 设置完起始偏移量和步长之后,再次执行show variables like'auto_inc%'; 发现跟之前一样,必须先exit,再登录才有效。 mysql> show variables like'auto_inc%'; +--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | auto_increment_increment | 5 | | auto_increment_offset | 3 | +--------------------------+-------+ 2 rows in set (0.00 sec) #因为之前有一条记录id=1 mysql> select * from student; +----+---------+------+ | id | name | sex | +----+---------+------+ | 1 | xiaobai | male | +----+---------+------+ 1 row in set (0.00 sec) # 下次插入的时候,从起始位置3开始,每次插入记录id+5 mysql> insert into student(name) values('ma1'),('ma2'),('ma3'); Query OK, 3 rows affected (0.00 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> select * from student; +----+---------+------+ | id | name | sex | +----+---------+------+ | 1 | xiaobai | male | | 3 | ma1 | male | | 8 | ma2 | male | | 13 | ma3 | male | +----+---------+------+
delete 与truncate删除的区别:
delete from t1; #如果有自增id,新增的数据,仍然是以删除前的最后一样作为起始。
truncate table t1;数据量大,删除速度比上一条快,且直接从零开始。
foreign key :
为了节省内存空间与数据冗余,我们可以创建主表与从表进行关联.
例子:创建员工表与部门表:
#1.创建表时先创建被关联表,再创建关联表 # 先创建被关联表(dep表) create table dep( id int primary key, name varchar(20) not null, descripe varchar(20) not null ); #再创建关联表(emp表) create table emp( id int primary key, name varchar(20) not null, age int not null, dep_id int, constraint fk_dep foreign key(dep_id) references dep(id) ); #2.插入记录时,先往被关联表中插入记录,再往关联表中插入记录 insert into dep values (1,'IT','IT技术有限部门'), (2,'销售部','销售部门'), (3,'财务部','花钱太多部门'); insert into emp values (1,'zhangsan',18,1), (2,'lisi',19,1), (3,'egon',20,2), (4,'yuanhao',40,3), (5,'alex',18,2); 3.删除表 #按道理来说,删除了部门表中的某个部门,员工表的有关联的记录相继删除。 mysql> delete from dep where id=3; ERROR 1451 (23000): Cannot delete or update a parent row: a foreign key constraint fails (`db5`.`emp`, CONSTRAINT `fk_name` FOREIGN KEY (`dep_id`) REFERENCES `dep` (`id`)) #但是先删除员工表的记录之后,再删除当前部门就没有任何问题 mysql> delete from emp where dep =3; Query OK, 1 row affected (0.00 sec) mysql> select * from emp; +----+----------+-----+--------+ | id | name | age | dep_id | +----+----------+-----+--------+ | 1 | zhangsan | 18 | 1 | | 2 | lisi | 18 | 1 | | 3 | egon | 20 | 2 | | 5 | alex | 18 | 2 | +----+----------+-----+--------+ 4 rows in set (0.00 sec) mysql> delete from dep where id=3; Query OK, 1 row affected (0.00 sec) mysql> select * from dep; +----+-----------+----------------------+ | id | name | descripe | +----+-----------+----------------------+ | 1 | IT | IT技术有限部门 | | 2 | 销售部 | 销售部门 | +----+-----------+----------------------+ 2 rows in set (0.00 sec)
从上面可以看出为了删除数据时必须先删除关联表里面的数据后才可以删除被关联表里面相应的内容,为了解决这个问题,引入同步删除与同步更新
在创建关联表的时候给数据设定完完整性约束以后最后加上
on delete cascade #同步删除
on update cascade #同步更新
create table emp( id int primary key, name varchar(20) not null, age int not null, dep_id int, constraint fk_dep foreign key(dep_id) references dep(id) on delete cascade #同步删除 on update cascade #同步更新 );
再删除数据就可以随意删除了
#再去删被关联表(dep)的记录,关联表(emp)中的记录也跟着删除 mysql> delete from dep where id=3; Query OK, 1 row affected (0.00 sec) mysql> select * from dep; +----+-----------+----------------------+ | id | name | descripe | +----+-----------+----------------------+ | 1 | IT | IT技术有限部门 | | 2 | 销售部 | 销售部门 | +----+-----------+----------------------+ 2 rows in set (0.00 sec) mysql> select * from emp; +----+----------+-----+--------+ | id | name | age | dep_id | +----+----------+-----+--------+ | 1 | zhangsan | 18 | 1 | | 2 | lisi | 19 | 1 | | 3 | egon | 20 | 2 | | 5 | alex | 18 | 2 | +----+----------+-----+--------+ 4 rows in set (0.00 sec) #再去更改被关联表(dep)的记录,关联表(emp)中的记录也跟着更改 mysql> update dep set id=222 where id=2; Query OK, 1 row affected (0.02 sec) Rows matched: 1 Changed: 1 Warnings: 0 # 赶紧去查看一下两张表是否都被删除了,是否都被更改了 mysql> select * from dep; +-----+-----------+----------------------+ | id | name | descripe | +-----+-----------+----------------------+ | 1 | IT | IT技术有限部门 | | 222 | 销售部 | 销售部门 | +-----+-----------+----------------------+ 2 rows in set (0.00 sec) mysql> select * from emp; +----+----------+-----+--------+ | id | name | age | dep_id | +----+----------+-----+--------+ | 1 | zhangsan | 18 | 1 | | 2 | lisi | 19 | 1 | | 3 | egon | 20 | 222 | | 5 | alex | 18 | 222 | +----+----------+-----+--------+ 4 rows in set (0.00 sec)
外键的变种(三种方式):
重点: 1 如何找出两张表之间的关系 2表之间三种关系
三种关系: 多对一 多对多 一对一
如何确定表之间的关系:
分析步骤: #1、先站在左表的角度去找 是否左表的多条记录可以对应右表的一条记录,如果是,则证明左表的一个字段foreign key 右表一个字段(通常是id) #2、再站在右表的角度去找 是否右表的多条记录可以对应左表的一条记录,如果是,则证明右表的一个字段foreign key 左表一个字段(通常是id) #3、总结: #多对一: 如果只有步骤1成立,则是左表多对一右表 如果只有步骤2成立,则是右表多对一左表 #多对多 如果步骤1和2同时成立,则证明这两张表时一个双向的多对一,即多对多,需要定义一个这两张表的关系表来专门存放二者的关系 #一对一: 如果1和2都不成立,而是左表的一条记录唯一对应右表的一条记录,反之亦然。这种情况很简单,就是在左表foreign key右表的基础上,将左表的外键字段设置成unique即可
表的三种关系:
多对一:
书和出版社的关系:一本书只能被一个出版社出版,一个出版社可以出版多种书,
create table press( id int primary key auto_increment, name varchar(20) ); create table book( id int primary key auto_increment, name varchar(20), press_id int not null, constraint fk_book_press foreign key(press_id) references press(id) on delete cascade on update cascade ); # 先往被关联表中插入记录 insert into press(name) values ('北京工业地雷出版社'), ('人民音乐不好听出版社'), ('知识产权没有用出版社') ; # 再往关联表中插入记录 insert into book(name,press_id) values ('九阳神功',1), ('九阴真经',2), ('九阴白骨爪',2), ('独孤九剑',3), ('降龙十巴掌',2), ('葵花宝典',3) ; 查询结果: mysql> select * from book; +----+-----------------+----------+ | id | name | press_id | +----+-----------------+----------+ | 1 | 九阳神功 | 1 | | 2 | 九阴真经 | 2 | | 3 | 九阴白骨爪 | 2 | | 4 | 独孤九剑 | 3 | | 5 | 降龙十巴掌 | 2 | | 6 | 葵花宝典 | 3 | +----+-----------------+----------+ 6 rows in set (0.00 sec) mysql> select * from press; +----+--------------------------------+ | id | name | +----+--------------------------------+ | 1 | 北京工业地雷出版社 | | 2 | 人民音乐不好听出版社 | | 3 | 知识产权没有用出版社 | +----+--------------------------------+ 3 rows in set (0.00 sec)
多对多:
书籍作者和书的关系:一本书可以被多个人共同完成,一个作者也可以出版多本书.
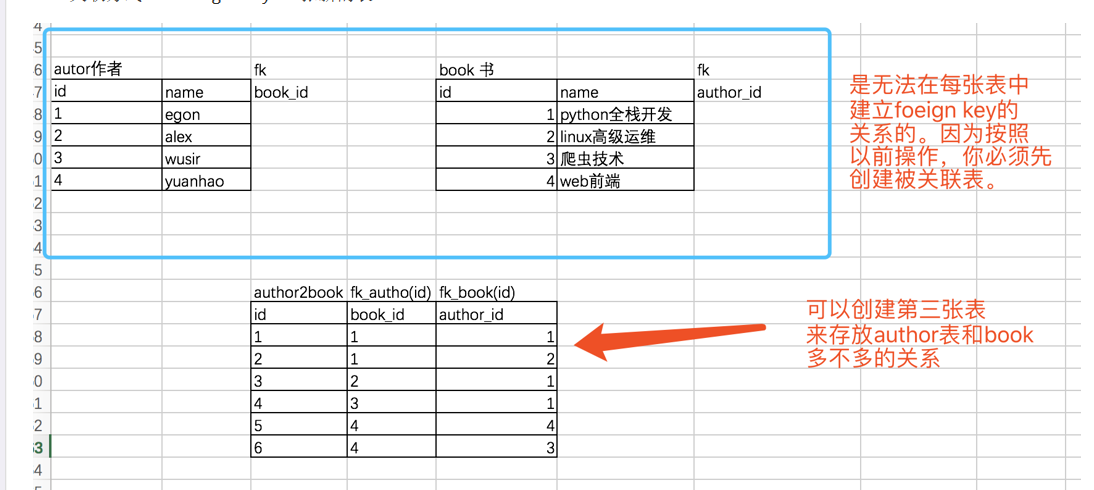
# 创建被关联表author表,之前的book表在讲多对一的关系已创建 create table author( id int primary key auto_increment, name varchar(20) ); #这张表就存放了author表和book表的关系,即查询二者的关系查这表就可以了 create table author2book( id int not null unique auto_increment, author_id int not null, book_id int not null, constraint fk_author foreign key(author_id) references author(id) on delete cascade on update cascade, constraint fk_book foreign key(book_id) references book(id) on delete cascade on update cascade, primary key(author_id,book_id) ); #插入四个作者,id依次排开 insert into author(name) values('egon'),('alex'),('wusir'),('yuanhao'); # 每个作者的代表作 egon: 九阳神功、九阴真经、九阴白骨爪、独孤九剑、降龙十巴掌、葵花宝典 alex: 九阳神功、葵花宝典 wusir:独孤九剑、降龙十巴掌、葵花宝典 yuanhao:九阳神功 # 在author2book表中插入相应的数据 insert into author2book(author_id,book_id) values (1,1), (1,2), (1,3), (1,4), (1,5), (1,6), (2,1), (2,6), (3,4), (3,5), (3,6), (4,1) ; # 现在就可以查author2book对应的作者和书的关系了 mysql> select * from author2book; +----+-----------+---------+ | id | author_id | book_id | +----+-----------+---------+ | 1 | 1 | 1 | | 2 | 1 | 2 | | 3 | 1 | 3 | | 4 | 1 | 4 | | 5 | 1 | 5 | | 6 | 1 | 6 | | 7 | 2 | 1 | | 8 | 2 | 6 | | 9 | 3 | 4 | | 10 | 3 | 5 | | 11 | 3 | 6 | | 12 | 4 | 1 | +----+-----------+---------+ 12 rows in set (0.00 sec)
一对一:
用户与博客:一个用户只能有一个唯一的博客用户地址:
#例如: 一个用户只能注册一个博客 #两张表: 用户表 (user)和 博客表(blog) # 创建用户表 create table user( id int primary key auto_increment, name varchar(20) ); # 创建博客表 create table blog( id int primary key auto_increment, url varchar(100), user_id int unique, constraint fk_user foreign key(user_id) references user(id) on delete cascade on update cascade ); #插入用户表中的记录 insert into user(name) values ('alex'), ('wusir'), ('egon'), ('xiaoma') ; # 插入博客表的记录 insert into blog(url,user_id) values ('http://www.cnblog/alex',1), ('http://www.cnblog/wusir',2), ('http://www.cnblog/egon',3), ('http://www.cnblog/xiaoma',4) ; # 查询wusir的博客地址 select url from blog where user_id=2;