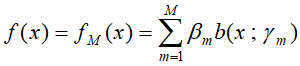就分类问题的训练而言,求比较粗糙的分类规则(弱分类器)要比求精确的分类规则(强分类器)容易。而提升方法即从若分类器算法的学习出发,反复学习,得到一系列的弱分类器,然后通过组合,构成一个强分类器。
当然,在这提升方法中,有两个问题需要解决:
- 如何在每一轮的训练中改变数据的权值或是概率分布;
- 如何将弱分类器组合成一个强分类器。
AdaBoost算法
提升算法中,最具有代表性的算法是AdaBoost算法。
而对提升算法中的两个问题,AdaBoost算法对第一个问题的解决方法是:提高那些在前一轮分类器被误分的样本的权值,而降低那些被正确分类的样本权值,这样就能是的在下一轮的分类学习中,更加注重那些被误分的样本。
对于第二个问题,AdaBoost算法的解决方法是:采用加权多数表决的方法,即加大分类误差率小的弱分类器的权值,使其在表决中能起较大作用;减小分类误差率大的弱分类器的权值,使其在表决中起作用较小。
AdaBoost算法流程:
输入:训练数据集
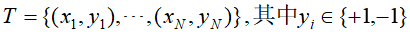 和弱学习方法;
和弱学习方法;
输出:最终分类器
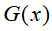 ;
;
- 初始化训练数据的权值分布(初始平均分配,D的下标和
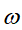 的第一个下标表示训练的轮次)
的第一个下标表示训练的轮次)
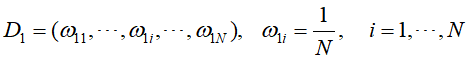
- 对于第m次训练,
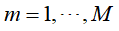
- 使用具有权值分布
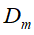 的训练数据集学习,得到基本分类器
的训练数据集学习,得到基本分类器
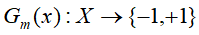
- 计算
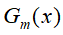 在训练数据集上分类误差率
在训练数据集上分类误差率
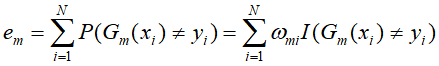
- 计算
 的系数
的系数
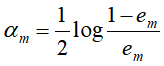
- 更新训练数据集的权值

- 使用具有权值分布
- 将上述得到的弱分类器进行线性组合

最终得到分类器
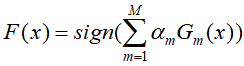
向前分步算法
实际上Adaboost算法是向前分步算法的特例,即Adaboost算法是模型为加法模型、损失函数为指数函数、学习算法为向前分步算法时的二分类学习方法。
向前分步算法(forward stagewise algorithm)学习的模型也是加法模型,能够从前向后,每步只学习一个基函数及其系数,进而使算法优化的复杂度得到降低。
向前分步算法流程:
输入:训练数据集
 ;损失函数
;损失函数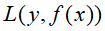 ;基函数集合
;基函数集合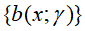 ;(损失函数的形式和基函数集合都是给定的,而在这算法的流程中,
;(损失函数的形式和基函数集合都是给定的,而在这算法的流程中,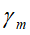 是基函数的参数,
是基函数的参数,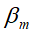 是基函数的系数)
是基函数的系数)
输出:加法模型
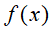 ;
;
(1)初始化
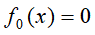
(2)对于第m次训练,
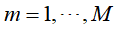
(a)极小化损失函数
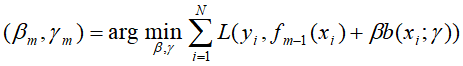
得到参数
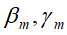
(b)更新
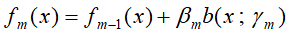
- 得到加法模型