问题:元数据管理是在内存中进行的,一旦故障,无法恢复。
解决方法:采用fsimage镜像文件和edit log编辑日志的方式来持久化数据。
fsimage是二进制的序列化文件,相当于内存的快照,可以跨平台,恢复速度快。但是不能每时每刻记录fsimage(如果记录频繁,数量多或者文件大,内存读取速度就会变慢),于是就有edit log辅助记录。
edit log记录的是对元数据增删改的操作,但是记录过多,就会越来越庞大。namenode读取这两个文件,恢复的速度就会减慢。
于是,有一种机制,定时将fsimage,edit log合并成新的fsimage即可。这个工作不能由工作繁忙的namenode来做,所有就出现了一个助手,
secondaryNameNode来协助工作。
SecondaryNameNode的工作机制
参考网址:https://zhuanlan.zhihu.com/p/117770907
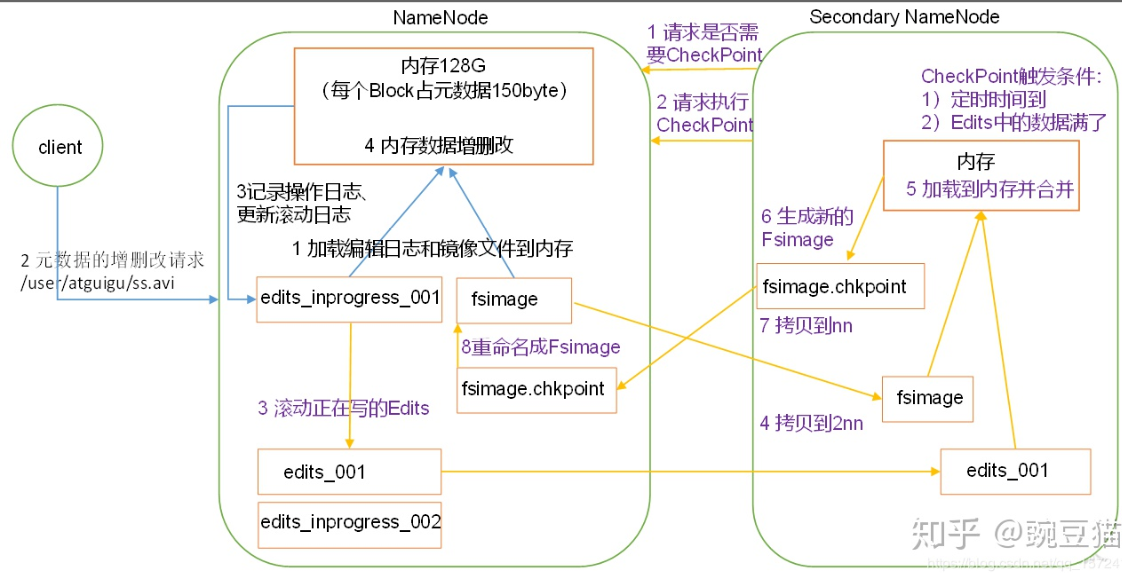
1) NameNode
- 加载至内存
第一次启动集群,初始化namenode,将生成一个空的fsimage文件和edit log日志文件;如果不是第一次,内存会将fsimage文件和edit log日志加载到内存 中,并将fsimage,edit log做一次合并,edit log变成一个空的日志文件,内存中是最新的元数据信息;
- 客户端发起元数据的增删改
- 将增删改操作记录到新的edit log中
- 在内存中做元数据的增删改操作
2)SecondaryNameNode
- 定期询问是否需要checkpoint,并返回信息
- 对nn执行checkpoint
当满足时间>1h 或者 edit log日志>64M时,会对namenode进行checkpoint
- 对原edit log进行标记,生成一个新的edit log
新的edit log用来记录合并后的新的元数据操作。
- 拷贝fsimage和edit log(标记)到secondaryNamenode
- 在内存中将这个两个文件合并
- 生成一个新的fsimage
- 将fsimage拷贝至namenode
- 替换之前的fsimage