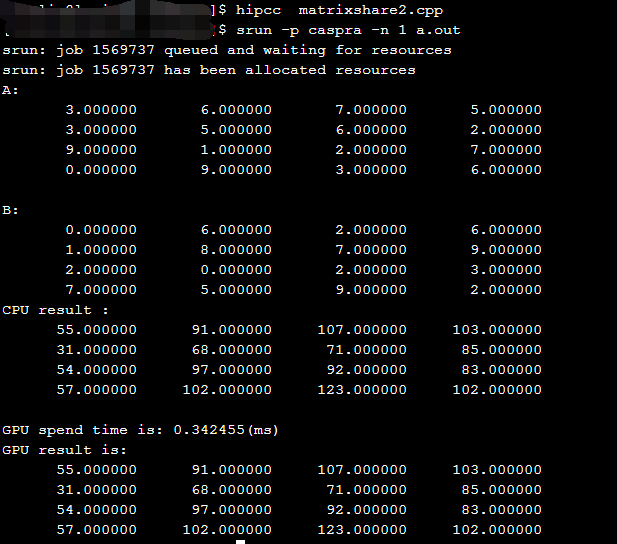
1.使用hip实现矩阵乘
1 #include <stdio.h> 2 #include <stdlib.h> 3 4 #include <hip/hip_runtime.h> 5 #include <hip/hip_runtime_api.h> 6 7 #define M 4 8 #define K 4 9 #define N 4 10 11 void initial(double* list,int row,int col) 12 { 13 double *num = list; 14 for (int i=0; i<row*col; i++) 15 { 16 num[i] = rand()%10; 17 } 18 } 19 20 void CpuMatrix(double *A,double *B,double *C) 21 { 22 int i,j,k; 23 24 for( i=0; i<M; i++) 25 { 26 for(j=0; j<N; j++) 27 { 28 double sum = 0; 29 for(int k=0; k<K; k++) 30 { 31 sum += A[i*K + k] * B[k * N + j]; 32 } 33 C[i * N + j] = sum; 34 } 35 } 36 } 37 38 __global__ void GpuMatrix(double *dev_A,double *dev_B,double *dev_C) 39 { 40 int ix = hipBlockIdx_x * hipBlockDim_x + hipThreadIdx_x; 41 int iy = hipBlockIdx_y * hipBlockDim_y + hipThreadIdx_y; 42 if(ix<K && iy<M) 43 { 44 double sum = 0; 45 for( int k = 0; k < K;k++) 46 { 47 sum += dev_A[iy*K + k] * dev_B[k*N + ix]; 48 } 49 dev_C[iy * N + ix] = sum; 50 } 51 } 52 53 void printMatrix(double *list,int row,int col) 54 { 55 double *p = list; 56 for(int i=0; i<row; i++) 57 { 58 for(int j=0; j<col; j++) 59 { 60 printf("%10lf",p[j]); 61 } 62 p = p + col; 63 printf(" "); 64 } 65 } 66 int main(int argc,char **argv) 67 { 68 int Axy = M*K; 69 int Abytes = Axy * sizeof(double); 70 71 int Bxy = K*N; 72 int Bbytes = Bxy * sizeof(double); 73 74 int nxy = M*N; 75 int nbytes = nxy * sizeof(double); 76 77 float time_cpu,time_gpu; 78 79 clock_t start_cpu,stop_cpu; 80 81 hipEvent_t start_GPU,stop_GPU; 82 83 double *host_A, *host_B, *host_C, *c_CPU; 84 host_A = (double*)malloc(Abytes); 85 host_B = (double*)malloc(Bbytes); 86 host_C = (double*)malloc(nbytes); 87 c_CPU = (double*)malloc(nbytes); 88 89 90 initial(host_A,M,K); 91 92 printf("A:(%d,%d): ",M,K); 93 printMatrix(host_A,M,K); 94 95 initial(host_B,K,N); 96 97 printf("B:(%d,%d): ",K,N); 98 printMatrix(host_B,K,N); 99 100 // start_cpu = clock(); 101 CpuMatrix(host_A,host_B,host_C); 102 // stop_cpu = clock(); 103 104 printf("Host_C:(%d,%d): ",M,N); 105 // printf(" CPU time is %f(ms) ",(float)(stop_cpu-start_cpu)/CLOCKS_PER_SEC); 106 printMatrix(host_C,M,N); 107 double *dev_A,*dev_B,*dev_C; 108 hipMalloc(&dev_A,Axy*sizeof(double)); 109 hipMalloc(&dev_B,Bxy*sizeof(double)); 110 hipMalloc(&dev_C,nxy*sizeof(double)); 111 112 dim3 block(1024,1); 113 dim3 grid(64,64); 114 115 hipMemcpy(dev_A,host_A,Abytes,hipMemcpyDeviceToHost); 116 hipMemcpy(dev_B,host_B,Bbytes,hipMemcpyDeviceToHost); 117 118 hipEventCreate(&start_GPU); 119 hipEventCreate(&stop_GPU); 120 hipEventRecord(start_GPU,0); 121 hipLaunchKernelGGL(GpuMatrix,grid,block,0,0,dev_A,dev_B,dev_C); 122 hipEventRecord(stop_GPU,0); 123 hipEventSynchronize(start_GPU); 124 hipEventSynchronize(stop_GPU); 125 hipEventElapsedTime(&time_gpu, start_GPU,stop_GPU); 126 printf(" The time from GPU: %f(ms) ", time_GPU/1000); 127 hipDeviceSynchronize(); 128 hipEventDestroy(start_GPU); 129 hipEventDestroy(stop_GPU); 130 131 hipMemcpy(c_CPU,dev_C,nbytes,hipMemcpyDeviceToHost); 132 printf("device_C:(%d,%d): ",M,N); 133 printMatrix(c_CPU,M,N); 134 135 136 hipFree(dev_A); 137 hipFree(dev_B); 138 hipFree(dev_C); 139 free(host_A); 140 free(host_B); 141 free(host_C); 142 free(c_CPU); 143 144 return 0; 145 }
结果如下:
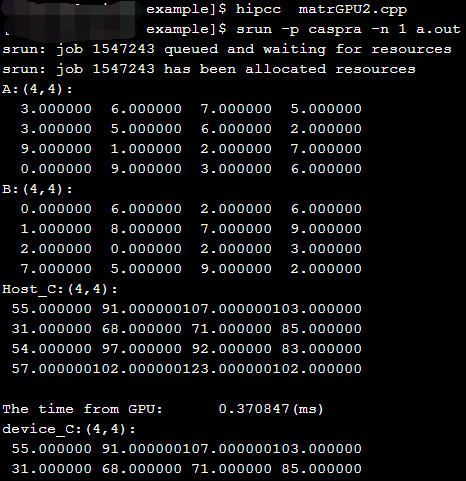

2.使用结构体实现HIP的矩阵乘
共享内存使用__shared__ 内存空间说明符来分配。
共享内存应该比全局内存快得多,这在线程结构中有提及并在共享内存中有详细描述。因此,任何可以用
共享内存访问替换全局内存访问的机会都应该被利用,如下面的矩阵乘法示例所示。
下面的示例代码是不利用共享内存的矩阵乘法的简单实现。每个线程读取 A 的一行和 B 的一列,并计算 C
的相应元素,如图 9 所示。因此,A 将从全局内存中被读取 B.width 次,而 B 将被读取 A.height 次。

1 #include <stdio.h> 2 #include <time.h> 3 #include <stdlib.h> 4 #include <hip/hip_runtime.h> 5 #include <hip/hip_runtime_api.h> 6 7 typedef struct{ 8 int width; 9 int height; 10 float* elements; 11 }Matrix; 12 13 #define BLOCK_SIZE 4 14 15 __global__ void MatMulKernel(const Matrix,const Matrix,Matrix); 16 17 void initial(float* A,int N) 18 { 19 int i; 20 for(i = 0;i<N;i++) 21 { 22 A[i] = rand()%10; 23 } 24 } 25 26 void shuchu(Matrix A,int N) 27 { 28 29 int j=0; 30 for(int i=0; i < N; i++) 31 { 32 if( j == A.width) 33 { 34 printf(" "); 35 j = 0; 36 i--; 37 }else 38 { 39 printf("%15lf",A.elements[i]); 40 j++; 41 } 42 } 43 } 44 45 __global__ void MatMulKernel(Matrix A,Matrix B,Matrix C) 46 { 47 float Cvalue = 0; 48 int row = hipBlockIdx_y * hipBlockDim_y + hipThreadIdx_y; 49 int col = hipBlockIdx_x * hipBlockDim_x + hipThreadIdx_x; 50 for(int e = 0; e < A.width; ++e) 51 { 52 Cvalue += A.elements[row * A.width + e] * B.elements[e*B.width + col]; 53 } 54 C.elements[row * C.width + col] = Cvalue; 55 } 56 57 //在CPU上计算矩阵乘 58 void CpuMatrix(Matrix A,Matrix B,Matrix C) 59 { 60 int M,N,K; 61 M = A.height; 62 N = B.width; 63 K = A.width; 64 int i,j,k; 65 for(i = 0;i < M;i++) 66 { 67 for(j = 0;j<N;j++) 68 { 69 float sum = 0.0; 70 for(k = 0;k<K;k++) 71 { 72 sum += A.elements[i * K + k] * B.elements[k * N + j]; 73 } 74 C.elements[i * N + j] = sum; 75 } 76 } 77 } 78 void MatMul(Matrix A,Matrix B,Matrix C) 79 { 80 Matrix d_A; 81 Matrix d_B; 82 Matrix d_C; 83 d_A.width = A.width; 84 d_A.height = A.height; 85 d_B.width = B.width; 86 d_B.height = B.height; 87 d_C.width = C.width; 88 d_C.height = C.height; 89 size_t size_A = A.width * A.height * sizeof(float); 90 size_t size_B = B.width * B.height * sizeof(float); 91 size_t size_C = C.width * C.height * sizeof(float); 92 93 hipMalloc(&d_A.elements,size_A); 94 hipMalloc(&d_B.elements,size_B); 95 hipMalloc(&d_C.elements,size_C); 96 dim3 dimBlock(BLOCK_SIZE,BLOCK_SIZE); 97 dim3 dimGrid(B.width / dimBlock.x,A.height / dimBlock.y); 98 99 hipMemcpy(d_A.elements,A.elements,size_A,hipMemcpyHostToDevice); 100 hipMemcpy(d_B.elements,B.elements,size_B,hipMemcpyHostToDevice); 101 //测试时间 102 float gpu_time; 103 hipEvent_t start_GPU,stop_GPU; 104 hipEventCreate(&start_GPU); 105 hipEventCreate(&stop_GPU); 106 hipEventRecord(start_GPU,0); 107 108 hipLaunchKernelGGL(MatMulKernel,dimGrid,dimBlock,0,0,d_A,d_B,d_C); 109 110 hipEventRecord(stop_GPU,0); 111 hipEventSynchronize(start_GPU); 112 hipEventSynchronize(stop_GPU); 113 hipEventElapsedTime(&gpu_time,start_GPU,stop_GPU); 114 hipDeviceSynchronize(); 115 printf(" GPU spend time is: %lf(ms) ",gpu_time/1000); 116 hipEventDestroy(start_GPU); 117 hipEventDestroy(stop_GPU); 118 hipMemcpy(C.elements,d_C.elements,size_C,hipMemcpyDeviceToHost); 119 120 printf(" GPU result is : "); 121 shuchu(C,C.width*C.height); 122 printf(" "); 123 hipFree(d_A.elements); 124 hipFree(d_B.elements); 125 hipFree(d_C.elements); 126 } 127 int main() 128 { 129 Matrix A; 130 Matrix B; 131 Matrix C; 132 A.width = BLOCK_SIZE; 133 A.height = BLOCK_SIZE; 134 B.width = BLOCK_SIZE; 135 B.height = BLOCK_SIZE; 136 C.width = BLOCK_SIZE; 137 C.height = BLOCK_SIZE; 138 139 int size = BLOCK_SIZE * BLOCK_SIZE; 140 int size_A = A.width * A.height * sizeof(float); 141 int size_B = B.width * B.height * sizeof(float); 142 int size_C = C.width * C.height * sizeof(float); 143 144 A.elements = (float *)malloc(size_A); 145 B.elements = (float *)malloc(size_B); 146 C.elements = (float *)malloc(size_C); 147 148 initial(A.elements,A.height*A.width); 149 printf("A: "); 150 shuchu(A,A.width*A.height); 151 152 printf(" B: "); 153 initial(B.elements,B.height*B.width); 154 shuchu(B,B.width*B.height); 155 156 //调用CPU计算 157 //测试CPU的计算时间 158 clock_t start_CPU,stop_CPU; 159 double cpu_time; 160 start_CPU = clock(); 161 162 CpuMatrix(A,B,C); 163 stop_CPU = clock(); 164 //cpu_time = (double)(stop_CPU-start_CPU)/CLOCKS_PER_SEC; 165 //printf(" CPU time is %lf(ms) ",cpu_time); 166 printf(" CPU result : "); 167 shuchu(C,C.width*C.height); 168 // shuchu(C,C.width*C.height); 169 printf(" "); 170 MatMul(A,B,C); 171 return 0; 172 } 173 174
运行结果如下:

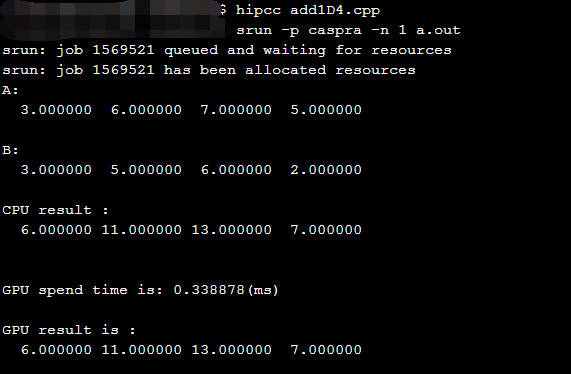
3.利用结构体实现HIP的数组相加
1 #include <stdio.h> 2 #include <time.h> 3 #include <stdlib.h> 4 #include <hip/hip_runtime.h> 5 #include <hip/hip_runtime_api.h> 6 7 typedef struct{ 8 int width; 9 float* elements; 10 }Matrix; 11 12 #define BLOCK_SIZE 4 13 14 __global__ void MatMulKernel(const Matrix,const Matrix,Matrix); 15 16 void initial(float* A,int N) 17 { 18 int i; 19 for(i = 0;i<N;i++) 20 { 21 A[i] = rand()%10; 22 } 23 } 24 25 void shuchu(Matrix A,int N) 26 { 27 for(int i=0; i < N; i++) 28 { 29 printf("%10lf",A.elements[i]); 30 } 31 printf(" "); 32 } 33 34 __global__ void MatMulKernel(Matrix A,Matrix B,Matrix C) 35 { 36 int col = hipBlockIdx_x * hipBlockDim_x + hipThreadIdx_x; 37 38 C.elements[col] = A.elements[col]+B.elements[col]; 39 } 40 41 42 void CpuMatrix(Matrix A,Matrix B,Matrix C) 43 { 44 int N; 45 N = B.width; 46 int i; 47 for(i=0;i<N;i++) 48 { 49 C.elements[i] = A.elements[i] + B.elements[i]; 50 } 51 52 } 53 void MatMul(Matrix A,Matrix B,Matrix C) 54 { 55 Matrix d_A; 56 Matrix d_B; 57 Matrix d_C; 58 d_A.width = A.width; 59 d_B.width = B.width; 60 d_C.width = C.width; 61 62 size_t size_A = A.width * sizeof(float); 63 size_t size_B = B.width * sizeof(float); 64 size_t size_C = C.width * sizeof(float); 65 66 hipMalloc(&d_A.elements,size_A); 67 hipMalloc(&d_B.elements,size_B); 68 hipMalloc(&d_C.elements,size_C); 69 dim3 dimBlock(BLOCK_SIZE,BLOCK_SIZE); 70 dim3 dimGrid(1); 71 72 hipMemcpy(d_A.elements,A.elements,size_A,hipMemcpyHostToDevice); 73 hipMemcpy(d_B.elements,B.elements,size_B,hipMemcpyHostToDevice); 74 75 float gpu_time; 76 hipEvent_t start_GPU,stop_GPU; 77 hipEventCreate(&start_GPU); 78 hipEventCreate(&stop_GPU); 79 hipEventRecord(start_GPU,0); 80 81 hipLaunchKernelGGL(MatMulKernel,dimGrid,dimBlock,0,0,d_A,d_B,d_C); 82 83 hipEventRecord(stop_GPU,0); 84 hipEventSynchronize(start_GPU); 85 hipEventSynchronize(stop_GPU); 86 hipEventElapsedTime(&gpu_time,start_GPU,stop_GPU); 87 hipDeviceSynchronize(); 88 printf(" GPU spend time is: %lf(ms) ",gpu_time/1000); 89 hipEventDestroy(start_GPU); 90 hipEventDestroy(stop_GPU); 91 hipMemcpy(C.elements,d_C.elements,size_C,hipMemcpyDeviceToHost); 92 93 printf(" GPU result is : "); 94 shuchu(C,C.width); 95 printf(" "); 96 hipFree(d_A.elements); 97 hipFree(d_B.elements); 98 hipFree(d_C.elements); 99 } 100 int main() 101 { 102 Matrix A; 103 Matrix B; 104 Matrix C; 105 A.width = BLOCK_SIZE; 106 107 B.width = BLOCK_SIZE; 108 109 C.width = BLOCK_SIZE; 110 111 int size_A = A.width * sizeof(float); 112 int size_B = B.width * sizeof(float); 113 int size_C = C.width * sizeof(float); 114 115 A.elements = (float *)malloc(size_A); 116 B.elements = (float *)malloc(size_B); 117 C.elements = (float *)malloc(size_C); 118 119 initial(A.elements,A.width); 120 printf("A: "); 121 shuchu(A,A.width); 122 123 printf(" B: "); 124 initial(B.elements,B.width); 125 shuchu(B,B.width); 126 127 CpuMatrix(A,B,C); 128 129 printf(" CPU result : "); 130 shuchu(C,C.width); 131 132 printf(" "); 133 MatMul(A,B,C); 134 return 0; 135 } 136 137
运行结果如下:
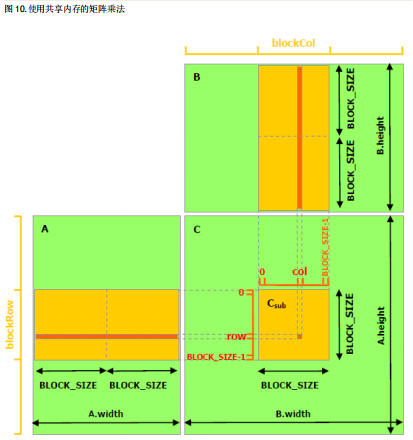
4.使用共享内存实现矩阵乘法(利用了结构体)
下面的示例代码是利用共享内存的矩阵乘法的实现.在这个实现中,每个线程块负责计算 C 的一个方形子 矩阵 Csub ,块内的每个线程负责计算 Csub 的一个元素.如图 10 所示,Csub 等于两个矩阵的乘积:维度为 (A.width, block_size)的子矩阵 A 与 Csub 有相同的行索引,维度为(block_size, A.width )的子矩阵 B 与 Csub 有相同的列索引.为了适应设备资源的需求,将这两个矩阵根据需要分为维度为 block_size 的多个 正方形矩阵.计算这些方形矩阵的乘积之和即可得到 Csub .这些乘积中的每一个的计算都是首先将两个 对应的正方形矩阵从全局内存加载到共享内存,一个线程加载一个元素,然后再让每个线程计算一个元 素.每个线程将这些乘积的结果累积到一个寄存器中,完成后再将结果写入全局内存.
通过这种方式分块计算,我们充分利用了快速的共享内存,并节省了大量的全局内存带宽,因为 A 只从全局内存中读取了(B.width / block_size)次,B 只从全局内存中读取了(A.height / block_size)次。
前一段示例代码中的矩阵类型使用了 stride 字段进行扩充,因此可以使用相同类型有效地表示子矩阵。__device__函数用于获取和设置元素并从矩阵中构建任何子矩阵。
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <hip/hip_runtime.h> 4 #include <hip/hip_runtime_api.h> 5 6 typedef struct{ 7 int width; 8 int height; 9 int stride; 10 float* elements; 11 }Matrix; 12 13 #define BLOCK_SIZE 4 14 15 //初始化 16 void initial(float* A,int N) 17 { 18 int i; 19 for(i = 0;i<N;i++) 20 { 21 A[i] = rand()%10; 22 } 23 } 24 25 26 __device__ float GetElement(const Matrix A,int row,int col) 27 { 28 return A.elements[row*A.stride+col]; 29 } 30 31 __device__ void SetElement(Matrix A,int row,int col,float value) 32 { 33 A.elements[row*A.stride+col]=value; 34 } 35 __device__ Matrix GetSubMatrix(Matrix A,int row,int col) 36 { 37 Matrix Asub; 38 Asub.width = BLOCK_SIZE; 39 Asub.height = BLOCK_SIZE; 40 Asub.stride = A.stride; 41 Asub.elements = &A.elements[A.stride*BLOCK_SIZE*row+BLOCK_SIZE*col]; 42 return Asub; 43 } 44 45 void shuchu(Matrix A,int N) 46 { 47 48 int j=0; 49 for(int i=0; i < N; i++) 50 { 51 if( j == A.width) 52 { 53 printf(" "); 54 j = 0; 55 i--; 56 }else 57 { 58 printf("%15lf",A.elements[i]); 59 j++; 60 } 61 } 62 printf(" "); 63 } 64 __global__ void MatMulKernel(Matrix A,Matrix B,Matrix C) 65 { 66 int blockRow = hipBlockIdx_y; 67 int blockCol = hipBlockIdx_x; 68 Matrix Csub = GetSubMatrix(C,blockRow,blockCol); 69 float Cvalue = 0; 70 int row = hipThreadIdx_y; 71 int col = hipThreadIdx_x; 72 for(int m=0; m<(A.width/BLOCK_SIZE);++m) 73 { 74 Matrix Asub = GetSubMatrix(A,blockRow,m); 75 Matrix Bsub = GetSubMatrix(B,m,blockCol); 76 __shared__ float As[BLOCK_SIZE][BLOCK_SIZE]; 77 __shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE]; 78 79 As[row][col]=GetElement(Asub,row,col); 80 Bs[row][col]=GetElement(Bsub,row,col); 81 82 __syncthreads(); 83 for(int e = 0;e<BLOCK_SIZE;++e) 84 { 85 Cvalue += As[row][e]*Bs[e][col]; 86 } 87 __syncthreads(); 88 SetElement(Csub,row,col,Cvalue); 89 } 90 } 91 92 void MatMul(const Matrix A,const Matrix B,Matrix C) 93 { 94 Matrix d_A; 95 d_A.width = d_A.stride = A.width; 96 d_A.height = A.height; 97 size_t size = A.width * A.height * sizeof(float); 98 hipMalloc(&d_A.elements,size); 99 hipMemcpy(d_A.elements,A.elements,size,hipMemcpyHostToDevice); 100 101 Matrix d_B; 102 d_B.width = d_B.stride=B.width; 103 d_B.height = B.height; 104 size = B.width * B.height * sizeof(float); 105 hipMalloc(&d_B.elements,size); 106 hipMemcpy(d_B.elements,B.elements,size,hipMemcpyHostToDevice); 107 108 Matrix d_C; 109 d_C.width = d_C.stride = C.width; 110 d_C.height = C.height; 111 size = C.width * C.height * sizeof(float); 112 hipMalloc(&d_C.elements,size); 113 dim3 dimBlock(BLOCK_SIZE,BLOCK_SIZE); 114 dim3 dimGrid(B.width / dimBlock.x,A.height / dimBlock.y); 115 116 float gpu_time; 117 hipEvent_t start_GPU,stop_GPU; 118 hipEventCreate(&start_GPU); 119 hipEventCreate(&stop_GPU); 120 hipEventRecord(start_GPU,0); 121 122 hipLaunchKernelGGL(MatMulKernel,dimGrid,dimBlock,0,0,d_A,d_B,d_C); 123 124 hipEventRecord(stop_GPU,0); 125 hipEventSynchronize(start_GPU); 126 hipEventSynchronize(stop_GPU); 127 hipEventElapsedTime(&gpu_time,start_GPU,stop_GPU); 128 hipDeviceSynchronize(); 129 printf(" GPU spend time is: %lf(ms) ",gpu_time/1000); 130 hipEventDestroy(start_GPU); 131 hipEventDestroy(stop_GPU); 132 133 hipMemcpy(C.elements,d_C.elements,size,hipMemcpyDeviceToHost); 134 135 printf(" GPU result is: "); 136 shuchu(C,C.width*C.height); 137 138 hipFree(d_A.elements); 139 hipFree(d_B.elements); 140 hipFree(d_C.elements); 141 } 142 143 //使用CPU进行计算 144 void CpuMatrix(Matrix A,Matrix B,Matrix C) 145 { 146 int M,N,K; 147 M = A.height; 148 N = B.width; 149 K = A.width; 150 int i,j,k; 151 for(i = 0;i < M;i++) 152 { 153 for(j = 0;j<N;j++) 154 { 155 float sum = 0.0; 156 for(k = 0;k<K;k++) 157 { 158 sum += A.elements[i * K + k] * B.elements[k * N + j]; 159 } 160 C.elements[i * N + j] = sum; 161 } 162 } 163 } 164 int main() 165 { 166 Matrix A; 167 Matrix B; 168 Matrix C; 169 170 A.width = BLOCK_SIZE; 171 A.height = BLOCK_SIZE; 172 B.width = BLOCK_SIZE; 173 B.height = BLOCK_SIZE; 174 C.width = BLOCK_SIZE; 175 C.height = BLOCK_SIZE; 176 177 int size_A = A.width * A.height * sizeof(float); 178 int size_B = B.width * B.height * sizeof(float); 179 int size_C = C.width * C.height * sizeof(float); 180 181 A.elements = (float *)malloc(size_A); 182 B.elements = (float *)malloc(size_B); 183 C.elements = (float *)malloc(size_C); 184 185 initial(A.elements,A.height*A.width); 186 printf("A: "); 187 shuchu(A,A.width*A.height); 188 189 printf(" B: "); 190 initial(B.elements,B.height*B.width); 191 shuchu(B,B.width*B.height); 192 193 CpuMatrix(A,B,C); 194 printf(" CPU result : "); 195 shuchu(C,C.width*C.height); 196 MatMul(A,B,C); 197 return 0; 198 }
运行结果如下: