1,python2的默认编码是ascii码。
2,python2中有2中数据模型来支持字符串这种数据类型,分别为str和unicode。
3,uncode转换为其他编码是encode,其他编码转换成unicode是decode(解码)。所以unicode是核心,比如你现在有个gbk的字符串,如果想要变成utf-8,那你需要先decode然后在encode才行。
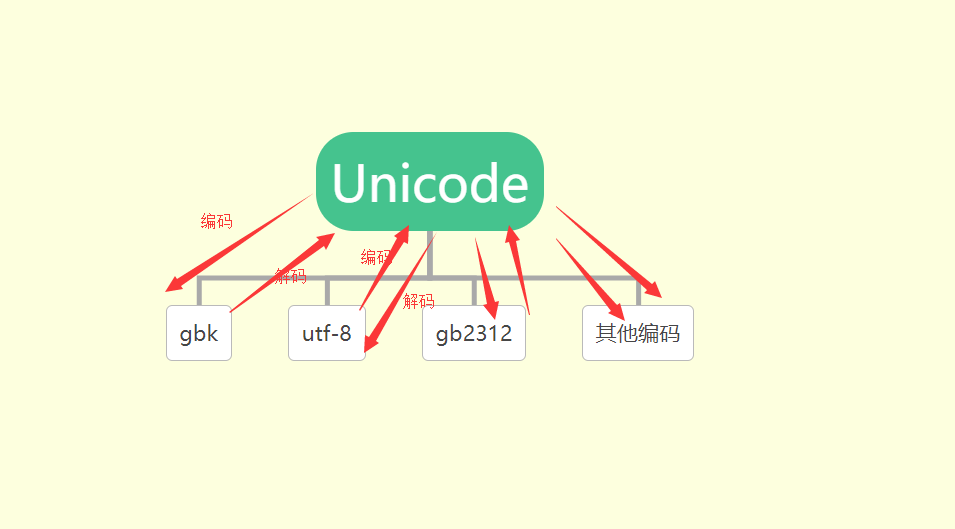
4,文件开头声明的编码与定义str是有关系的。str有utf-8 gbk gb2312 ascaii等。
比如:
#!/usr/bin/env python
# *-*coding:utf-8 *-*
s = '中国'
print(type(s))
结果:<type 'str'>
可以发现s是一个字符串,但其实它的编码也是utf-8,因为开头的声明变量就是utf-8。
#!/usr/bin/env python
# *-*coding:utf-8 *-*
s = '中国'
print(type(s))
data = s.decode('utf-8')
print(data)
print(type(data))
结果:
<type 'str'>
中国
<type 'unicode'>
可以发现s.decode(‘utf-8’)就将s解码为unicode,这个时候data就可以编码为其他的格式了。
比如:
#!/usr/bin/env python
# *-*coding:utf-8 *-*
s = '中国'
print(type(s))
s_unicode = s.decode('utf-8')
s_gbk = s_unicode.encode('gbk')
上述结果会输出一个gbk编码的字符串,但是可能会显示乱码。这个取决于你的终端。如果你使用的是windows 的cmd窗口,默认是gbk的话,就会显示出来了,但是如果你使用的是linux的终端或者pycharm运行会乱码。
5,上面说到一点,python2默认使用的是ascii码作为默认编码,所以会有一个问题。如下:
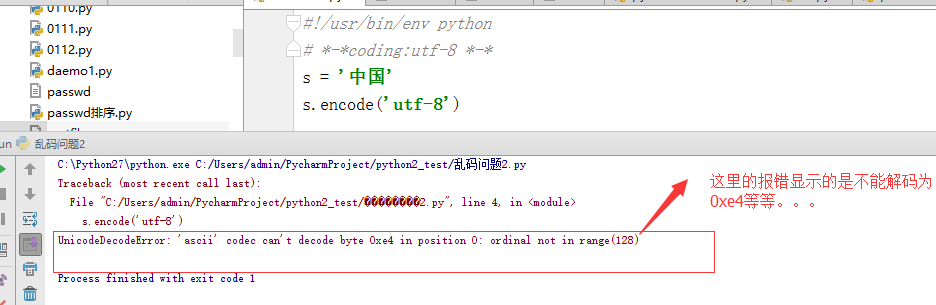
这就纳闷了,我刚刚明明是编码,为啥会显示解码呢?就算是解码为啥会是ascii码呢?这个就和Python2么默认编码有关系了。
因为python2默认在我编码的时候用默认的ascii码给我解码,所以
s.encode('utf-8') 过程是 s.decode('ascii').encode('utf-8' ) ,而s没办法解码为unicode。因为它其实本质上是utf-8,所以这也就无法解码了,报错了。
这就是默认编码的尴尬之处。
6,文件操作
python2操作文件,会经常报错。。。。。。。。。这就是因为咱们没搞清楚。所以,下面就谈谈自己的粗浅想法。
操作文件,建议使用codecs这个模块,非常方便。codecs提供open方法,open()方法可以指定编码格式。
使用这个方法打开这个文件读取返回都是unicode。写入时,如果write参数是unicode。则使用打开文件时的编码写入,如果是str,则先使用默认编码解码成unicode后再以打开文件的编码写入
这里需要注意的是如果str是中文,而默认编码sys.getdefaultencoding()是ascii的话会报解码错误。
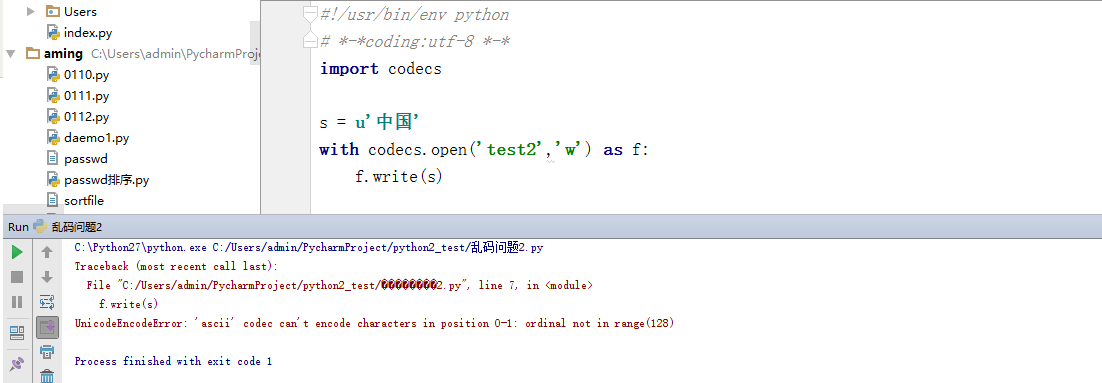
从上面可以发现默认打开文件,它会自动编码,如果没有指定编码,这个时候他用又得用默认编码,所以过程是s.encode('ascii') 所以这就不报错了吗?
所以写入的时候就指定编码就可以了。于是乎:
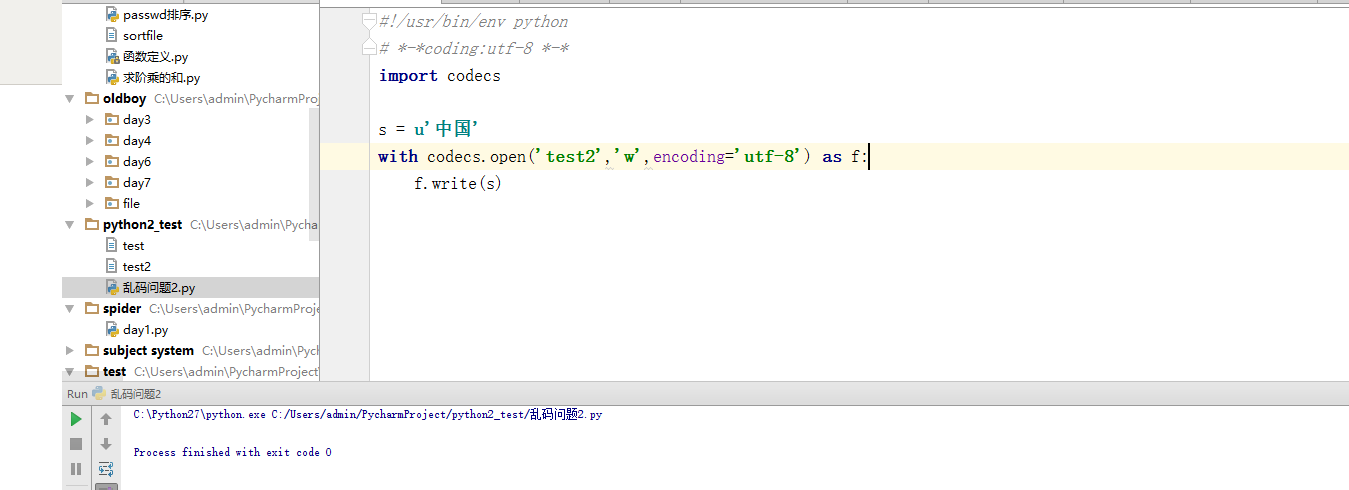
这样就可以避免报错了。
下面是读取,可以发现读取,是unicode编码。文件流.decode('utf-8')
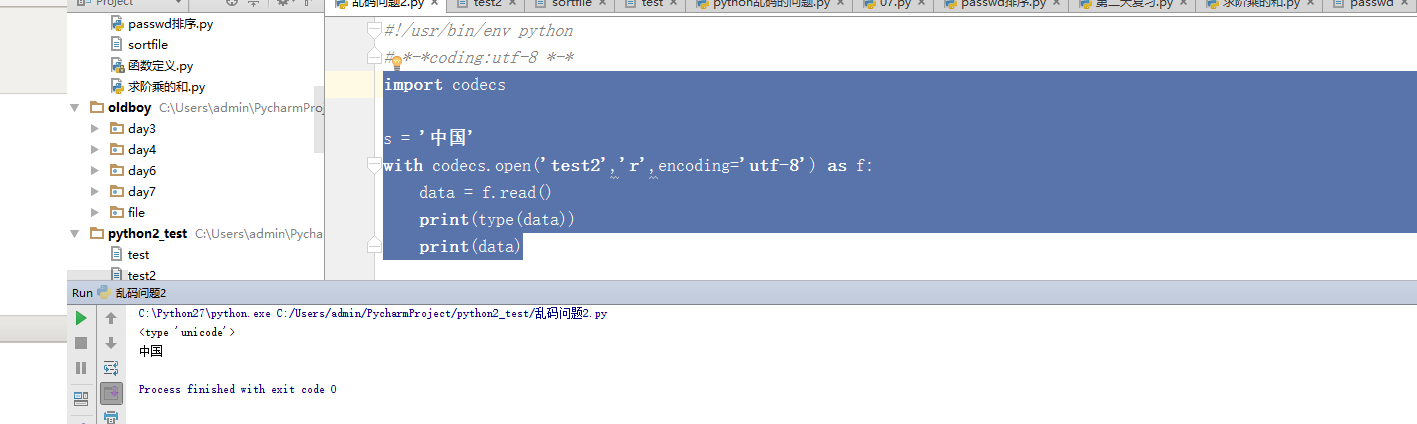
上面作为自己的笔记,可能有错误哦。