语法糖
接触语法糖是在读《深入理解Java虚拟机》的时候,初始觉得语法糖是个挺有意思的概念,遂抽出一周实践详细总结一下语法糖。百度百科对于语法糖的解释如下;
语法糖(Syntactic sugar),也译为糖衣语法,是由英国计算机科学家彼得·约翰·兰达(Peter J. Landin)发明的一个术语,指计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更方便程序员使用。通常来说使用语法糖能够增加程序的可读性,从而减少程序代码出错的机会。
通过上面的解释我们知道语法糖可以看做是编译器实现的一些“小把戏”,这些“小把戏”可以提高编码效率,提升语法的严谨性,减少编码出错的机会,但是并不能对代码性能提供实质性的帮助。下面我们对Java中常见的几种语法糖进行总结分析;
1 泛型与泛型擦除
了解泛型的Java开发者都知道,泛型是JDK1.5新增的特性,本质是对参数化类型的应用,也就是说“所操作的数据类型被指定为一个参数”。这种参数化类型可以用在类、方法、接口的创建中。分别称为泛型类、泛型方法、泛型接口。
泛型早在C++中就已经存在了,JDK1.5之前,Java语言还没有出现泛型,只能通过Object是所有类型的父类和类型强制转换两个特点来实现类型泛型,如下代码:
@Test public void test1(){ List list1 = new ArrayList();//如果没有泛型的话,那么list中我们任意的存放各种数据类型的 数据 list1.add("String"); list1.add(new ClassCast()); Object object1 = list1.get(0);//那么从集合中取出数据的时候,只能通过向上转型为所有类的父类Object来取出数据 String str = (String) object1;//然后通过强制转换来获取正确数据类型的数据,这里是很容易出现类型转换异常的 // String str1 = (String) list1.get(1);//出现ClassCastException System.out.println(str);//String }
我们可以看到,如果没有泛型的话,那么我们在取出数据的时候向下转型成什么数据类型都是可以的,只有程序员和运行时的虚拟机知道这个取出的Object到底是什么类型的对象。在编译期间,编译器无法检测这个Object是否转型成功,如果仅仅依赖程序员去保证这项操作的正确性,许多ClassCastException的风险就会转嫁到程序运行期之中。
Java源自C,那么Java中的泛型和C中的泛型是一样的吗?实际上是大相径庭的,这中间就牵涉到了几个概念:真实泛型和伪泛型;
C#里面的泛型无论是在程序源代码中、编译后的IL(类似于.class的中间语言,此时的泛型就是一个占位符)或是运行期的CLR中,都是切实存在的,List<int>与List<String>就是两个不同的类型,它们在系统运行期生成,有自己的需方法表和类型数据,这种实现称为类型膨胀,基于这种方法实现的泛型称为真实泛型。说白了真实泛型不管是在源代码还是机器码中都是能够起到约束作用的。
Java语言中的泛型则与C#的截然不同,它只会存在于程序源码中(即只能在.java文件中看到泛型的存在),而在编译后的字节码文件中,就已经看不到泛型的痕迹了,此时已经替换为原来的原生类型(Raw Type,也称为裸类型)了,并且在相应的地方插入类强制类型转换的代码,因此,对于运行期的Java语言来说,ArrayList<int>与ArrayList<String>就是同一个类,所以泛型技术实际上是Java语言的一颗语法糖,Java语言中的泛型实现方法称为类型擦除,基于这种方法实现的泛型称为伪泛型。下面我们来看一段代码,并且比对一下编译后的代码可以看出泛型擦除的痕迹;
源代码 @Test public void test2(){ List<String> list1 = new ArrayList();//如果没有泛型的话,那么list中我们任意的存放各种数据类型的 数据 list1.add("String"); // list1.add(new ClassCast());此时编译器提示List<String>不能接受该参数 /** * 那么从集合中取出数据的时候,源代码中看起来好像是取出来的就是我们存放 * 的数据类型,实际上JVM中的操作还是取出来是Object类型, * 然后通过强制转换转为String,只是编译器通过泛型帮我们进行了类型检查, * 所以将运行时异常转变为编译期异常了 */ String str1 = list1.get(0); System.out.println(str1);//String }
编译后的代码 @Test public void test2() { List list1 = new ArrayList(); list1.add("String"); String str1 = (String)list1.get(0); System.out.println(str1); }
通过上面的对比我们发现Java中的泛型只是在编译期帮助我们进行类型检查的,通过编译器的类型检查将运行期异常转变为编译器错误。那么问自己一个问题,泛型是不是真的就被擦除的一点痕迹都不剩了呢?实际上也倒并非完全如此;
由于Java泛型的引入,各种场景(虚拟机解析、反射等)下的方法调用都可能对原有的基础产生影响和新的需求,如在泛型类中如何获取传入的参数化类型等。因此,JCP组织对虚拟机规范做出了相应的修改,引入了诸如Signature、LocalVariableTypeTable等新的属性用于解决伴随泛型而来的参数类型的识别问题,Signature是其中最重要的一项属性,它的作用就是存储一个方法在字节码层面的特征签名,这个属性中保存的参数类型并不是原生类型,而是包括了参数化类型的信息。修改后的虚拟机规范要求所有能识别49.0以上版本的Class文件的虚拟机都要能正确地识别Signature参数。总之来说,擦除法所谓的擦除,仅仅是对方法的Code属性中的字节码进行擦除,实际上元数据中还是保留了泛型信息,这也是我们在通过反射手段获取参数化类型的根本依据【下面我们缀一段通过反射获取泛型参数类型的操作】。聊到这里,考虑一个问题,那就是泛型能作为重载的依据吗?下面我们了解一下;
package cn.syntacticSugar.genericity.before; import java.lang.reflect.Method; import java.lang.reflect.Parameter; import java.lang.reflect.ParameterizedType; import java.lang.reflect.Type; import java.util.Arrays; import java.util.List; import java.util.ArrayList; public class GenericDemo { public static void main(String[] args) throws NoSuchMethodException, SecurityException{ // test(new ArrayList<String>()); // GenericDemo gd = new GenericDemo(); // Class<GenericDemo> clazz = (Class<GenericDemo>) gd.getClass(); // System.out.println(clazz.getName()); // Method[] method = clazz.getMethods(); // for (int i = 0; i < method.length; i++) { // Class<?> returnType = method[i].getReturnType(); // System.out.print("方法名称"+method[i].getName()+" "); // System.out.print("方法返回参数:"+returnType.getName()+" "); // Class<Parameter>[] parameter = (Class<Parameter>[]) method[i].getParameterTypes(); // for (int j = 0; j < parameter.length; j++) { // System.out.println(parameter[j].getName()); // } // // } Method method = GenericDemo.class.getMethod("test", List.class); Type[] types = method.getGenericParameterTypes(); for (Type type : types) { System.out.println("#"+type); if(type instanceof ParameterizedType){ Type[] genericTypes = ((ParameterizedType)type).getActualTypeArguments(); for(Type genericType:genericTypes){ System.out.println("泛型类型"+genericType); } } } // Type returnType = method.getGenericReturnType();//获取返回类型的泛型 // if(returnType instanceof ParameterizedType){ // Type [] genericTypes2s =((ParameterizedType)returnType).getActualTypeArguments(); // for(Type genericType2:genericTypes2s){ // System.out.println("返回值,泛型类型"+genericType2); // } // } } public static String test(List<String> list){ System.out.println("invoke test(List<String> list)"); return "123"; } }

我们获取到的泛型类型和实际类型一致,这说明的确我们的泛型并没有完全的在JVM中消失踪迹.
泛型和重载的一次有意思的探索
我们知道方法重载要求方法具备不同的特征签名,而返回值并不包含在特征签名中(在编译层面的特征签名),所以返回值不参与重载选择,但是在Class文件格式之中,只要描述符不是完全一致的两个方法就可以共存。也就是说,两个方法如果有相同的名称和特征签名,但返回值不同,那它们也是可以合法地共存于一个Class文件中的。如下的代码,我们通过三个版本的JDK进行测试,测试结果分别罗列出来
import java.util.List; import java.util.ArrayList; public class GenericDemo { public static void main(String[] args){ test(new ArrayList<String>()); test(new ArrayList<Integer>()); } public static String test(List<String> list){ System.out.println("invoke test(List<String> list)"); return "123"; } public static int test(List<Integer> list){ System.out.println("invoke test(List<Integer> list)"); return 12; } }
JDK1.6测试:
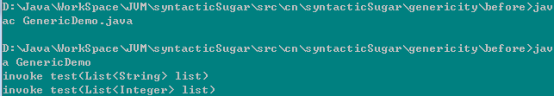
JDK1.7测试:

JDK1.8测试

我们通过三个版本的测试,发现只有JDK1.6可以编译文件,而且正常运行,其它再高版本的JDK不能支持这种情况下的“重载”了,但是可以将JDK1.6编译后的.Class文件正常解释执行.所以尽管在JVM层面重载会将返回值作为参考因素,但是在编译层面重载只考虑方法参数,而泛型擦除使得所有的参数变成了相同的数据类型,所以如上代码是不能通过的,而不能通过编译的代码,一切都是无谓的,在这里我们要注意不同的参数化类型不能作为方法重载的参考因素.
2 自动拆装箱
除了上面说的泛型外,其实还有一种语法糖是我们很常见的,那就是自动拆装箱。
自动拆装箱也是JDK1.5出现的特性(所以说JDK1.5是Java的一大飞跃,之后就是JDK1.8了,这是后话了)。在自动拆装箱之前,如果int类型想要转换为Integer只能通过手动调用Integer.valueOf(int)来完成转换,同样的拆箱的时候通过Integer.intValue()来完成,这些都需要我们手动来完成,无益于代码效率的提升。在JDK1.5中新增了自动拆装箱特性,该特性使得我们不用再自己手动完成自动拆装箱的操作,而是通过编译器帮我们实现自动拆装箱,这于性能无益,但是却提高了我们的开发效率,属于一个标准的语法糖。下面我们通过一段代码仔细瞜一眼;
package cn.syntacticSugar.box; import java.util.ArrayList; import java.util.List; public class SugarBox { public static void main(String[] args) { int i = 9; Integer in = 90; List<Integer> list = new ArrayList<Integer>(); list.add(7);//自动装箱 list.add(9); i = in + list.get(0);//自动拆箱 System.out.println(i);//97 } }
public class SugarBox { public SugarBox() { } public static void main(String args[]) { int i = 9; Integer in = Integer.valueOf(90); List list = new ArrayList(); list.add(Integer.valueOf(7)); list.add(Integer.valueOf(9)); i = in.intValue() + ((Integer)list.get(0)).intValue(); System.out.println(i); } }
关于自动拆装箱这个语法糖我们就介绍到这里,详细的自动拆装箱可以参见自动拆装箱笔记;
3 加强for循环
在我们开发编程中for循环是一种使用频率十分高的流程控制语句,我们都知道for循环有两种操作,一种是普通for循环,一种是JDK1.5新增的特性foreach(),也叫加强for循环;Java中的加强for循环实际上也是一种语法糖,底层是通过迭代器完成的,下面通过一段代码来说明;
package cn.syntacticSugar.fou; import java.util.ArrayList; import java.util.List; public class SugarFor { public static void main(String[] args) { List<String> list = new ArrayList<String>(); list.add("1"); list.add("12"); list.add("123"); list.add("1234"); for (int i = 0; i < list.size(); i++) { System.out.println(list.get(i)); } System.out.println("--------------------"); for (String string : list) { System.out.println(string); } } }
package cn.syntacticSugar.fou; import java.io.PrintStream; import java.util.*; public class SugarFor { public SugarFor() { } public static void main(String args[]) { List list = new ArrayList(); list.add("1"); list.add("12"); list.add("123"); list.add("1234"); for(int i = 0; i < list.size(); i++) System.out.println((String)list.get(i)); System.out.println("--------------------"); String string; for(Iterator iterator = list.iterator(); iterator.hasNext(); System.out.println(string)) string = (String)iterator.next(); } }
从上面我们可以看出普通for循环的底层仍旧是普通for循环。而加强for循环的底层是通过迭代器来进行循环操作的;通过上面的操作我们还可以看出如果条件语句的控制语句只有一条的时候,大括号“{}”是可以省略的,如果没有省略,那么编译器会替我们省略,这也可以理解为语法糖的一种;关于加强for我们就认识到这里,详细认识for语句,请参考JDK简史;
4 条件编译
条件语句也是我们日常开发中使用频率很高的一种语句。条件语句的判断依据就是条件判断的真假,一般情况下的条件判断是动态的,需要在JVM运行时才能确认真假,但是不排除有一些条件判断是可以在编译器期间就能够有结果的。这种情况下编译器会优化代码,将条件进行条件编译,生成的中间码class文件中直接以结果呈现,下面通过一段代码来看一下;
package cn.syntacticSugar.condition; public class SugarCondition { public static void main(String[] args) { if(5>3){ System.out.println(5>3); }else { System.out.println(5<3); } } }
package cn.syntacticSugar.condition; import java.io.PrintStream; public class SugarCondition { public SugarCondition() { } public static void main(String args[]) { System.out.println(true); } }
通过上面我们可以看到,当条件在编译期间就可以确定的话,那么编译器会在编译时对其优化,同时我们要注意在实际开发中IDE是会对这种代码提示Dead Code的,意思是无效代码的意思;条件语句也是可以用在while语句中的,那么当条件语句中用在while中会怎么样呢?下面我们通过一些代码看一下;
package cn.syntacticSugar.condition; public class SugarCondition { public static void main(String[] args) { test(5, 4); test11(); //test111(); } public static void test(int i1,int i2){ while(i1 > i2){ System.out.println(i1 + i2); } } public static void test11(){ while (5>3) { System.out.println(5>3); } } }
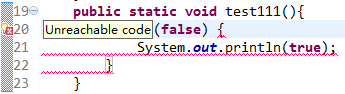
package cn.syntacticSugar.condition; import java.io.PrintStream; public class SugarCondition { public SugarCondition() { } public static void main(String args[]) { test(5, 4); test11(); } public static void test(int i1, int i2) { while(i1 > i2) System.out.println(i1 + i2); } public static void test11() { do System.out.println(true); while(true); } }
通过上面的代码我们可以看出,条件语句如果用在while语句中是会有惊人的变化的,如果条件结果为true,那么意味着是死循环,此时编译器会将while语句编程do while循环(死循环没什么区别了),但是如果条件是false,那么编译器会提示Unreachable Code,意思是下面代码执行不到,此时会提示我们删除下面执行不到的代码作为解决办法。看到这里我们已经很明白条件语句也是语法糖的一个成员了。
总结:
上面我们介绍了四种语法糖,实际上Java中除了这四种还有很多其他的语法糖,如变长参数、枚举类、内部类,断言语句等,这些我们以后遇到再一一介绍,这里不再赘述。对于语法糖我们只需要把握住一点,那就是“计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更方便程序员使用。通常来说使用语法糖能够增加程序的可读性,从而减少程序代码出错的机会。”,有了这个认识,我们就能很容易分辨Java中的那些语法糖了.